 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Perception in Text Strings
Oct 02, 2024



Understanding visual semantics embedded in consecutive characters is a crucial capability for both large language models (LLMs) and multi-modal large language models (MLLMs). This type of artifact possesses the unique characteristic that identical information can be readily formulated in both texts and images, making them a significant proxy for analyzing modern LLMs' and MLLMs' capabilities in modality-agnostic vision understanding. In this work, we select ASCII art as a representative artifact, where the lines and brightness used to depict each concept are rendered by characters, and we frame the problem as an ASCII art recognition task. We benchmark model performance on this task by constructing an evaluation dataset with an elaborate categorization tree and also collect a training set to elicit the models' visual perception ability. Through a comprehensive analysis of dozens of models, results reveal that although humans can achieve nearly 100% accuracy, the state-of-the-art LLMs and MLLMs lag far behind. Models are capable of recognizing concepts depicted in the ASCII arts given only text inputs indicated by over 60% accuracy for some concepts, but most of them achieves merely around 30% accuracy when averaged across all categories. When provided with images as inputs, GPT-4o gets 82.68%, outperforming the strongest open-source MLLM by 21.95%. Although models favor different kinds of ASCII art depending on the modality provided, none of the MLLMs successfully benefit when both modalities are supplied simultaneously. Moreover, supervised fine-tuning helps improve models' accuracy especially when provided with the image modality, but also highlights the need for better training techniques to enhance the information fusion among modalities.
Improving Topic Relevance Model by Mix-structured Summarization and LLM-based Data Augmentation
Apr 03, 2024



Topic relevance between query and document is a very important part of social search, which can evaluate the degree of matching between document and user's requirement. In most social search scenarios such as Dianping, modeling search relevance always faces two challenges. One is that many documents in social search are very long and have much redundant information. The other is that the training data for search relevance model is difficult to get, especially for multi-classification relevance model. To tackle above two problems, we first take query concatenated with the query-based summary and the document summary without query as the input of topic relevance model, which can help model learn the relevance degree between query and the core topic of document. Then, we utilize the language understanding and generation abilities of large language model (LLM) to rewrite and generate query from queries and documents in existing training data, which can construct new query-document pairs as training data. Extensive offline experiments and online A/B tests show that the proposed approaches effectively improve the performance of relevance modeling.
Zero-shot Faithfulness Evaluation for Text Summarization with Foundation Language Model
Oct 18, 2023



Despite tremendous improvements in natural language generation, summarization models still suffer from the unfaithfulness issue. Previous work evaluates faithfulness either using models trained on the other tasks or in-domain synthetic data, or prompting a large model such as ChatGPT. This paper proposes to do zero-shot faithfulness evaluation simply with a moderately-sized foundation language model. We introduce a new metric FFLM, which is a combination of probability changes based on the intuition that prefixing a piece of text that is consistent with the output will increase the probability of predicting the output. Experiments show that FFLM performs competitively with or even outperforms ChatGPT on both inconsistency detection and faithfulness rating with 24x fewer parameters. FFLM also achieves improvements over other strong baselines.
In-sample Curriculum Learning by Sequence Completion for Natural Language Generation
Nov 21, 2022



Curriculum learning has shown promising improvements in multiple domains by training machine learning models from easy samples to hard ones. Previous works which either design rules or train models for scoring the difficulty highly rely on task-specific expertise, and cannot generalize. Inspired by the ``easy-to-hard'' intuition, we propose to do in-sample curriculum learning for natural language generation tasks. Our learning strategy starts training the model to generate the last few words, i.e., do sequence completion, and gradually extends to generate the whole output sequence. Comprehensive experiments show that it generalizes well to different tasks and achieves significant improvements over strong baselines.
Taxonomy of Abstractive Dialogue Summarization: Scenarios, Approaches and Future Directions
Oct 18, 2022
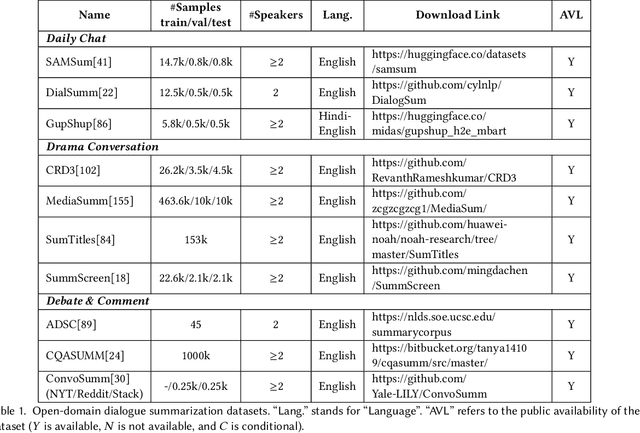
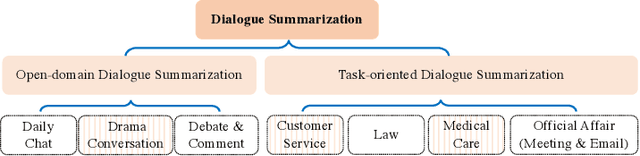
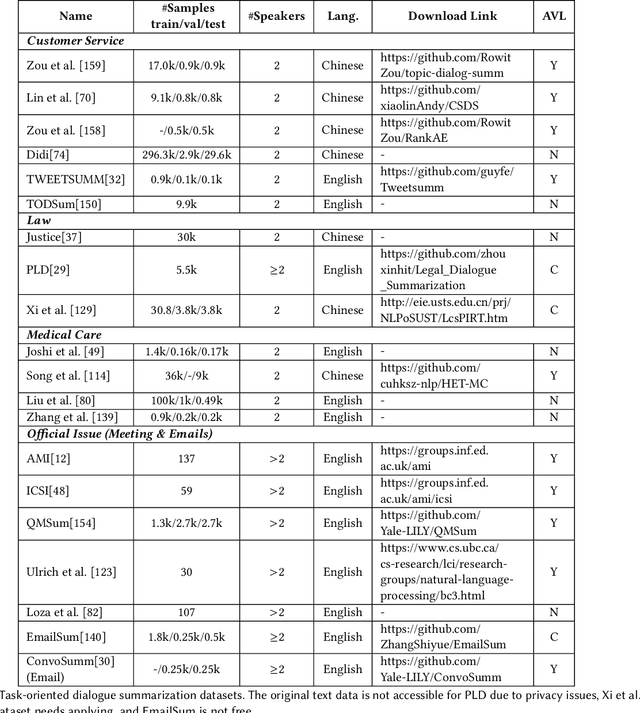
Abstractive dialogue summarization is to generate a concise and fluent summary covering the salient information in a dialogue among two or more interlocutors. It has attracted great attention in recent years based on the massive emergence of social communication platforms and an urgent requirement for efficient dialogue information understanding and digestion. Different from news or articles in traditional document summarization, dialogues bring unique characteristics and additional challenges, including different language styles and formats, scattered information, flexible discourse structures and unclear topic boundaries. This survey provides a comprehensive investigation on existing work for abstractive dialogue summarization from scenarios, approaches to evaluations. It categorizes the task into two broad categories according to the type of input dialogues, i.e., open-domain and task-oriented, and presents a taxonomy of existing techniques in three directions, namely, injecting dialogue features, designing auxiliary training tasks and using additional data.A list of datasets under different scenarios and widely-accepted evaluation metrics are summarized for completeness. After that, the trends of scenarios and techniques are summarized, together with deep insights on correlations between extensively exploited features and different scenarios. Based on these analyses, we recommend future directions including more controlled and complicated scenarios, technical innovations and comparisons, publicly available datasets in special domains, etc.
Post-Training Dialogue Summarization using Pseudo-Paraphrasing
Apr 28, 2022


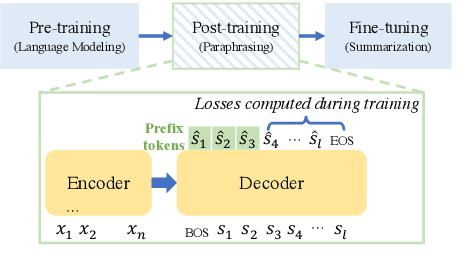
Previous dialogue summarization techniques adapt large language models pretrained on the narrative text by injecting dialogue-specific features into the models. These features either require additional knowledge to recognize or make the resulting models harder to tune. To bridge the format gap between dialogues and narrative summaries in dialogue summarization tasks, we propose to post-train pretrained language models (PLMs) to rephrase from dialogue to narratives. After that, the model is fine-tuned for dialogue summarization as usual. Comprehensive experiments show that our approach significantly improves vanilla PLMs on dialogue summarization and outperforms other SOTA models by the summary quality and implementation costs.
Multi-turn Response Selection using Dialogue Dependency Relations
Oct 04, 2020
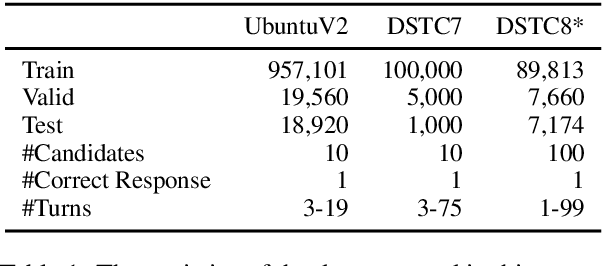
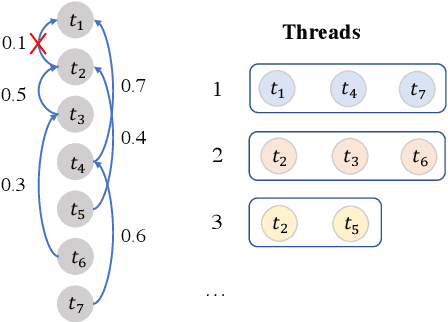

Multi-turn response selection is a task designed for developing dialogue agents. The performance on this task has a remarkable improvement with pre-trained language models. However, these models simply concatenate the turns in dialogue history as the input and largely ignore the dependencies between the turns. In this paper, we propose a dialogue extraction algorithm to transform a dialogue history into threads based on their dependency relations. Each thread can be regarded as a self-contained sub-dialogue. We also propose Thread-Encoder model to encode threads and candidates into compact representations by pre-trained Transformers and finally get the matching score through an attention layer. The experiments show that dependency relations are helpful for dialogue context understanding, and our model outperforms the state-of-the-art baselines on both DSTC7 and DSTC8*, with competitive results on UbuntuV2.