 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-ISSM: Objective Quality Assessment of Point Clouds Using Multi-scale Implicit Structural Similarity
Jan 03, 2026The unstructured and irregular nature of point clouds poses a significant challenge for objective quality assessment (PCQA), particularly in establishing accurate perceptual feature correspondence. To tackle this, we propose the Multi-scale Implicit Structural Similarity Measurement (MS-ISSM). Unlike traditional point-to-point matching, MS-ISSM utilizes Radial Basis Functions (RBF) to represent local features continuously, transforming distortion measurement into a comparison of implicit function coefficients. This approach effectively circumvents matching errors inherent in irregular data. Additionally, we propose a ResGrouped-MLP quality assessment network, which robustly maps multi-scale feature differences to perceptual scores. The network architecture departs from traditional flat MLPs by adopting a grouped encoding strategy integrated with Residual Blocks and Channel-wise Attention mechanisms. This hierarchical design allows the model to preserve the distinct physical semantics of luma, chroma, and geometry while adaptively focusing on the most salient distortion features across High, Medium, and Low scales. Experimental results on multiple benchmarks demonstrate that MS-ISSM outperforms state-of-the-art metrics in both reliability and generalization. The source code is available at: https://github.com/ZhangChen2022/MS-ISSM.
Audio Turing Test: Benchmarking the Human-likeness of Large Language Model-based Text-to-Speech Systems in Chinese
May 16, 2025Recent advances in large language models (LLMs) have significantly improved text-to-speech (TTS) systems, enhancing control over speech style, naturalness, and emotional expression, which brings TTS Systems closer to human-level performance. Although the Mean Opinion Score (MOS) remains the standard for TTS System evaluation, it suffers from subjectivity, environmental inconsistencies, and limited interpretability. Existing evaluation datasets also lack a multi-dimensional design, often neglecting factors such as speaking styles, context diversity, and trap utterances, which is particularly evident in Chinese TTS evaluation. To address these challenges, we introduce the Audio Turing Test (ATT), a multi-dimensional Chinese corpus dataset ATT-Corpus paired with a simple, Turing-Test-inspired evaluation protocol. Instead of relying on complex MOS scales or direct model comparisons, ATT asks evaluators to judge whether a voice sounds human. This simplification reduces rating bias and improves evaluation robustness. To further support rapid model development, we also finetune Qwen2-Audio-Instruct with human judgment data as Auto-ATT for automatic evaluation. Experimental results show that ATT effectively differentiates models across specific capability dimensions using its multi-dimensional design. Auto-ATT also demonstrates strong alignment with human evaluations, confirming its value as a fast and reliable assessment tool. The white-box ATT-Corpus and Auto-ATT can be found in ATT Hugging Face Collection (https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4).
RBFIM: Perceptual Quality Assessment for Compressed Point Clouds Using Radial Basis Function Interpolation
Mar 18, 2025One of the main challenges in point cloud compression (PCC) is how to evaluate the perceived distortion so that the codec can be optimized for perceptual quality. Current standard practices in PCC highlight a primary issue: while single-feature metrics are widely used to assess compression distortion, the classic method of searching point-to-point nearest neighbors frequently fails to adequately build precise correspondences between point clouds, resulting in an ineffective capture of human perceptual features. To overcome the related limitations, we propose a novel assessment method called RBFIM, utilizing radial basis function (RBF) interpolation to convert discrete point features into a continuous feature function for the distorted point cloud. By substituting the geometry coordinates of the original point cloud into the feature function, we obtain the bijective sets of point features. This enables an establishment of precise corresponding features between distorted and original point clouds and significantly improves the accuracy of quality assessments. Moreover, this method avoids the complexity caused by bidirectional searches. Extensive experiments on multiple subjective quality datasets of compressed point clouds demonstrate that our RBFIM excels in addressing human perception tasks, thereby providing robust support for PCC optimization efforts.
Boosting LLM via Learning from Data Iteratively and Selectively
Dec 23, 2024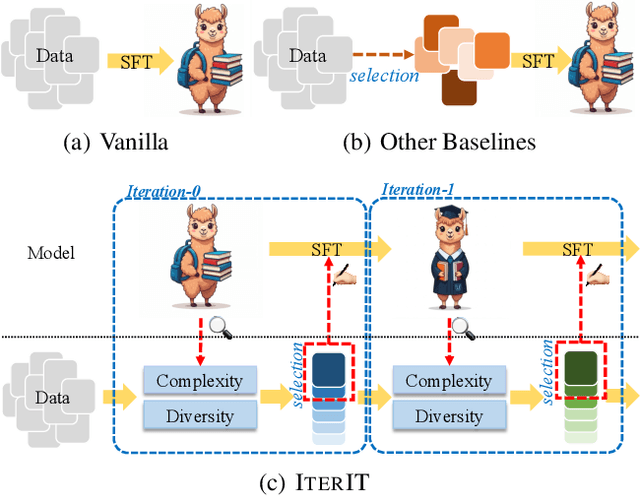
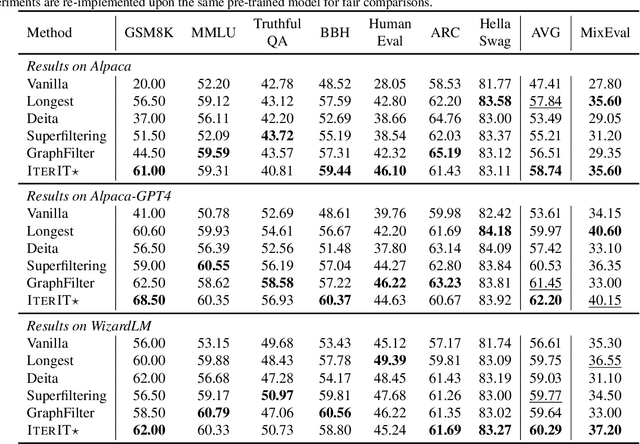
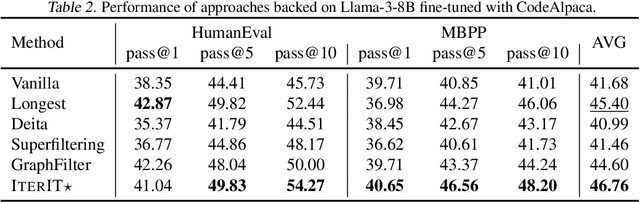
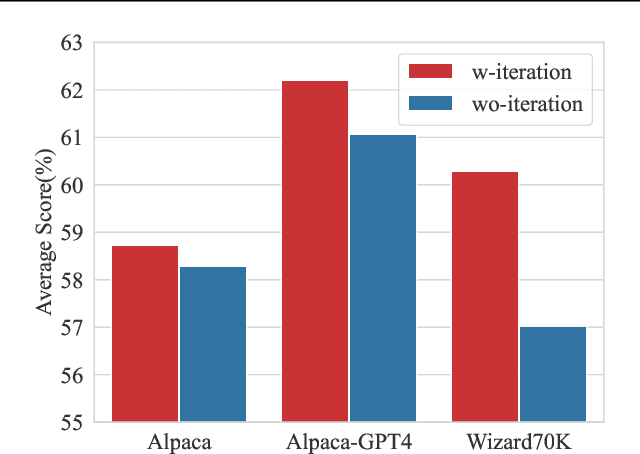
Datasets nowadays are generally constructed from multiple sources and using different synthetic techniques, making data de-noising and de-duplication crucial before being used for post-training. In this work, we propose to perform instruction tuning by iterative data selection (\ApproachName{}). We measure the quality of a sample from complexity and diversity simultaneously. Instead of calculating the complexity score once for all before fine-tuning, we highlight the importance of updating this model-specific score during fine-tuning to accurately accommodate the dynamic changes of the model. On the other hand, the diversity score is defined on top of the samples' responses under the consideration of their informativeness. IterIT integrates the strengths of both worlds by iteratively updating the complexity score for the top-ranked samples and greedily selecting the ones with the highest complexity-diversity score. Experiments on multiple instruction-tuning data demonstrate consistent improvements of IterIT over strong baselines. Moreover, our approach also generalizes well to domain-specific scenarios and different backbone models. All resources will be available at https://github.com/JiaQiSJTU/IterIT.
A Controlled Study on Long Context Extension and Generalization in LLMs
Sep 18, 2024



Broad textual understanding and in-context learning require language models that utilize full document contexts. Due to the implementation challenges associated with directly training long-context models, many methods have been proposed for extending models to handle long contexts. However, owing to differences in data and model classes, it has been challenging to compare these approaches, leading to uncertainty as to how to evaluate long-context performance and whether it differs from standard evaluation. We implement a controlled protocol for extension methods with a standardized evaluation, utilizing consistent base models and extension data. Our study yields several insights into long-context behavior. First, we reaffirm the critical role of perplexity as a general-purpose performance indicator even in longer-context tasks. Second, we find that current approximate attention methods systematically underperform across long-context tasks. Finally, we confirm that exact fine-tuning based methods are generally effective within the range of their extension, whereas extrapolation remains challenging. All codebases, models, and checkpoints will be made available open-source, promoting transparency and facilitating further research in this critical area of AI development.
DynoSurf: Neural Deformation-based Temporally Consistent Dynamic Surface Reconstruction
Mar 18, 2024



This paper explores the problem of reconstructing temporally consistent surfaces from a 3D point cloud sequence without correspondence. To address this challenging task, we propose DynoSurf, an unsupervised learning framework integrating a template surface representation with a learnable deformation field. Specifically, we design a coarse-to-fine strategy for learning the template surface based on the deformable tetrahedron representation. Furthermore, we propose a learnable deformation representation based on the learnable control points and blending weights, which can deform the template surface non-rigidly while maintaining the consistency of the local shape. Experimental results demonstrate the significant superiority of DynoSurf over current state-of-the-art approaches, showcasing its potential as a powerful tool for dynamic mesh reconstruction. The code is publicly available at https://github.com/yaoyx689/DynoSurf.
Dynamic 3D Point Cloud Sequences as 2D Videos
Mar 02, 2024Dynamic 3D point cloud sequences serve as one of the most common and practical representation modalities of dynamic real-world environments. However, their unstructured nature in both spatial and temporal domains poses significant challenges to effective and efficient processing. Existing deep point cloud sequence modeling approaches imitate the mature 2D video learning mechanisms by developing complex spatio-temporal point neighbor grouping and feature aggregation schemes, often resulting in methods lacking effectiveness, efficiency, and expressive power. In this paper, we propose a novel generic representation called \textit{Structured Point Cloud Videos} (SPCVs). Intuitively, by leveraging the fact that 3D geometric shapes are essentially 2D manifolds, SPCV re-organizes a point cloud sequence as a 2D video with spatial smoothness and temporal consistency, where the pixel values correspond to the 3D coordinates of points. The structured nature of our SPCV representation allows for the seamless adaptation of well-established 2D image/video techniques, enabling efficient and effective processing and analysis of 3D point cloud sequences. To achieve such re-organization, we design a self-supervised learning pipeline that is geometrically regularized and driven by self-reconstructive and deformation field learning objectives. Additionally, we construct SPCV-based frameworks for both low-level and high-level 3D point cloud sequence processing and analysis tasks, including action recognition, temporal interpolation, and compression. Extensive experiments demonstrate the versatility and superiority of the proposed SPCV, which has the potential to offer new possibilities for deep learning on unstructured 3D point cloud sequences. Code will be released at https://github.com/ZENGYIMING-EAMON/SPCV.
On the Efficacy of Eviction Policy for Key-Value Constrained Generative Language Model Inference
Feb 17, 2024



Despite the recent success associated with Large Language Models (LLMs), they are notably cost-prohibitive to deploy in resource-constrained environments due to their excessive memory and computational demands. In addition to model parameters, the key-value cache is also stored in GPU memory, growing linearly with batch size and sequence length. As a remedy, recent works have proposed various eviction policies for maintaining the overhead of key-value cache under a given budget. This paper embarks on the efficacy of existing eviction policies in terms of importance score calculation and eviction scope construction. We identify the deficiency of prior policies in these two aspects and introduce RoCo, a robust cache omission policy based on temporal attention scores and robustness measures. Extensive experimentation spanning prefilling and auto-regressive decoding stages validates the superiority of RoCo. Finally, we release EasyKV, a versatile software package dedicated to user-friendly key-value constrained generative inference. Code available at https://github.com/DRSY/EasyKV.
Self-supervised Learning of LiDAR 3D Point Clouds via 2D-3D Neural Calibration
Jan 23, 2024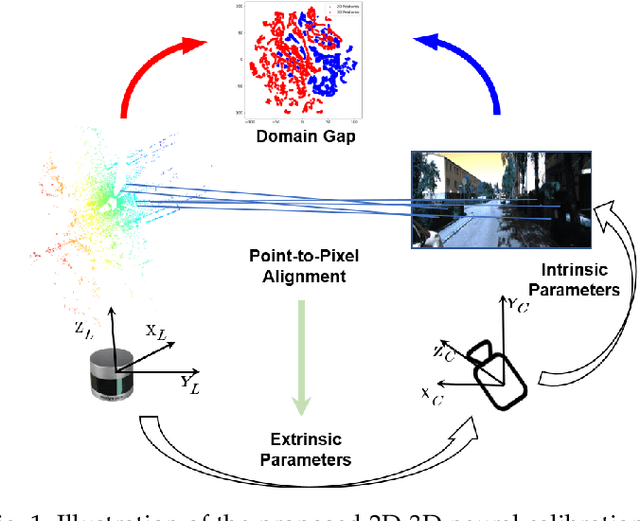
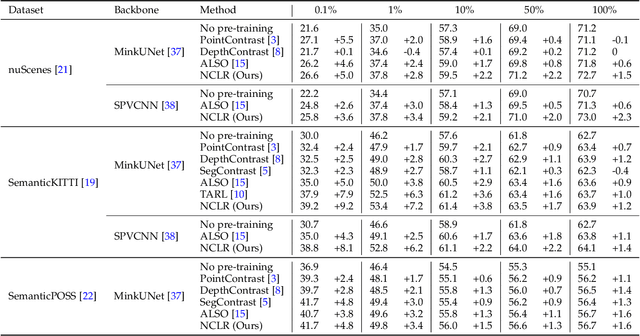
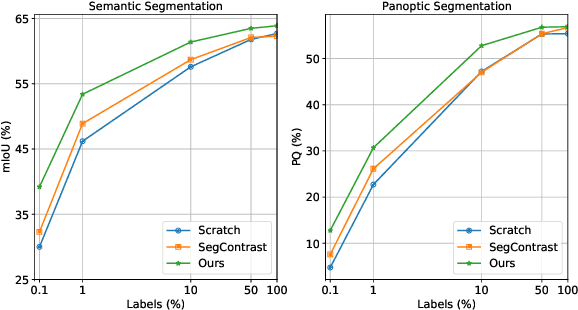
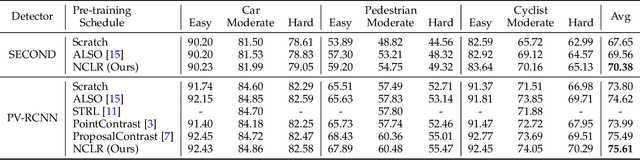
This paper introduces a novel self-supervised learning framework for enhancing 3D perception in autonomous driving scenes. Specifically, our approach, named NCLR, focuses on 2D-3D neural calibration, a novel pretext task that estimates the rigid transformation aligning camera and LiDAR coordinate systems. First, we propose the learnable transformation alignment to bridge the domain gap between image and point cloud data, converting features into a unified representation space for effective comparison and matching. Second, we identify the overlapping area between the image and point cloud with the fused features. Third, we establish dense 2D-3D correspondences to estimate the rigid transformation. The framework not only learns fine-grained matching from points to pixels but also achieves alignment of the image and point cloud at a holistic level, understanding their relative pose. We demonstrate NCLR's efficacy by applying the pre-trained backbone to downstream tasks, such as LiDAR-based 3D semantic segmentation, object detection, and panoptic segmentation. Comprehensive experiments on various datasets illustrate the superiority of NCLR over existing self-supervised methods. The results confirm that joint learning from different modalities significantly enhances the network's understanding abilities and effectiveness of learned representation. Code will be available at \url{https://github.com/Eaphan/NCLR}.
Measuring the Discrepancy between 3D Geometric Models using Directional Distance Fields
Jan 18, 2024Qualifying the discrepancy between 3D geometric models, which could be represented with either point clouds or triangle meshes, is a pivotal issue with board applications. Existing methods mainly focus on directly establishing the correspondence between two models and then aggregating point-wise distance between corresponding points, resulting in them being either inefficient or ineffective. In this paper, we propose DirDist, an efficient, effective, robust, and differentiable distance metric for 3D geometry data. Specifically, we construct DirDist based on the proposed implicit representation of 3D models, namely directional distance field (DDF), which defines the directional distances of 3D points to a model to capture its local surface geometry. We then transfer the discrepancy between two 3D geometric models as the discrepancy between their DDFs defined on an identical domain, naturally establishing model correspondence. To demonstrate the advantage of our DirDist, we explore various distance metric-driven 3D geometric modeling tasks, including template surface fitting, rigid registration, non-rigid registration, scene flow estimation and human pose optimization. Extensive experiments show that our DirDist achieves significantly higher accuracy under all tasks. As a generic distance metric, DirDist has the potential to advance the field of 3D geometric modeling. The source code is available at \url{https://github.com/rsy6318/DirDist}.