 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverFill: Two-Stage Models for Efficient Language Model Decoding
Aug 11, 2025Large language models (LLMs) excel across diverse tasks but face significant deployment challenges due to high inference costs. LLM inference comprises prefill (compute-bound) and decode (memory-bound) stages, with decode dominating latency particularly for long sequences. Current decoder-only models handle both stages uniformly, despite their distinct computational profiles. We propose OverFill, which decouples these stages to optimize accuracy-efficiency tradeoffs. OverFill begins with a full model for prefill, processing system and user inputs in parallel. It then switches to a dense pruned model, while generating tokens sequentially. Leveraging more compute during prefill, OverFill improves generation quality with minimal latency overhead. Our 3B-to-1B OverFill configuration outperforms 1B pruned models by 83.2%, while the 8B-to-3B configuration improves over 3B pruned models by 79.2% on average across standard benchmarks. OverFill matches the performance of same-sized models trained from scratch, while using significantly less training data. Our code is available at https://github.com/friendshipkim/overfill.
Fairness Practices in Industry: A Case Study in Machine Learning Teams Building Recommender Systems
May 26, 2025The rapid proliferation of recommender systems necessitates robust fairness practices to address inherent biases. Assessing fairness, though, is challenging due to constantly evolving metrics and best practices. This paper analyzes how industry practitioners perceive and incorporate these changing fairness standards in their workflows. Through semi-structured interviews with 11 practitioners from technical teams across a range of large technology companies, we investigate industry implementations of fairness in recommendation system products. We focus on current debiasing practices, applied metrics, collaborative strategies, and integrating academic research into practice. Findings show a preference for multi-dimensional debiasing over traditional demographic methods, and a reliance on intuitive rather than academic metrics. This study also highlights the difficulties in balancing fairness with both the practitioner's individual (bottom-up) roles and organizational (top-down) workplace constraints, including the interplay with legal and compliance experts. Finally, we offer actionable recommendations for the recommender system community and algorithmic fairness practitioners, underlining the need to refine fairness practices continually.
A Controlled Study on Long Context Extension and Generalization in LLMs
Sep 18, 2024



Broad textual understanding and in-context learning require language models that utilize full document contexts. Due to the implementation challenges associated with directly training long-context models, many methods have been proposed for extending models to handle long contexts. However, owing to differences in data and model classes, it has been challenging to compare these approaches, leading to uncertainty as to how to evaluate long-context performance and whether it differs from standard evaluation. We implement a controlled protocol for extension methods with a standardized evaluation, utilizing consistent base models and extension data. Our study yields several insights into long-context behavior. First, we reaffirm the critical role of perplexity as a general-purpose performance indicator even in longer-context tasks. Second, we find that current approximate attention methods systematically underperform across long-context tasks. Finally, we confirm that exact fine-tuning based methods are generally effective within the range of their extension, whereas extrapolation remains challenging. All codebases, models, and checkpoints will be made available open-source, promoting transparency and facilitating further research in this critical area of AI development.
EG4D: Explicit Generation of 4D Object without Score Distillation
May 28, 2024In recent years, the increasing demand for dynamic 3D assets in design and gaming applications has given rise to powerful generative pipelines capable of synthesizing high-quality 4D objects. Previous methods generally rely on score distillation sampling (SDS) algorithm to infer the unseen views and motion of 4D objects, thus leading to unsatisfactory results with defects like over-saturation and Janus problem. Therefore, inspired by recent progress of video diffusion models, we propose to optimize a 4D representation by explicitly generating multi-view videos from one input image. However, it is far from trivial to handle practical challenges faced by such a pipeline, including dramatic temporal inconsistency, inter-frame geometry and texture diversity, and semantic defects brought by video generation results. To address these issues, we propose DG4D, a novel multi-stage framework that generates high-quality and consistent 4D assets without score distillation. Specifically, collaborative techniques and solutions are developed, including an attention injection strategy to synthesize temporal-consistent multi-view videos, a robust and efficient dynamic reconstruction method based on Gaussian Splatting, and a refinement stage with diffusion prior for semantic restoration. The qualitative results and user preference study demonstrate that our framework outperforms the baselines in generation quality by a considerable margin. Code will be released at \url{https://github.com/jasongzy/EG4D}.
MambaByte: Token-free Selective State Space Model
Jan 24, 2024



Token-free language models learn directly from raw bytes and remove the bias of subword tokenization. Operating on bytes, however, results in significantly longer sequences, and standard autoregressive Transformers scale poorly in such settings. We experiment with MambaByte, a token-free adaptation of the Mamba state space model, trained autoregressively on byte sequences. Our experiments indicate the computational efficiency of MambaByte compared to other byte-level models. We also find MambaByte to be competitive with and even outperform state-of-the-art subword Transformers. Furthermore, owing to linear scaling in length, MambaByte benefits from fast inference compared to Transformers. Our findings establish the viability of MambaByte in enabling token-free language modeling.
Diffusion Models Without Attention
Nov 30, 2023

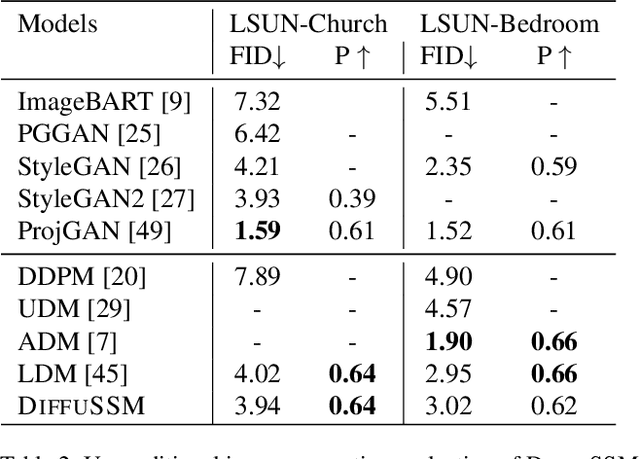
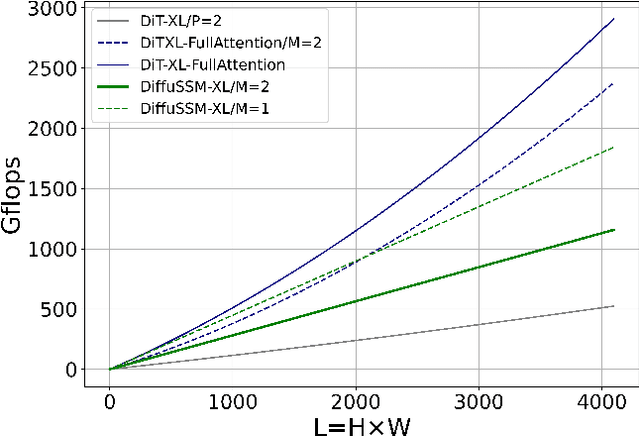
In recent advancements in high-fidelity image generation, Denoising Diffusion Probabilistic Models (DDPMs) have emerged as a key player. However, their application at high resolutions presents significant computational challenges. Current methods, such as patchifying, expedite processes in UNet and Transformer architectures but at the expense of representational capacity. Addressing this, we introduce the Diffusion State Space Model (DiffuSSM), an architecture that supplants attention mechanisms with a more scalable state space model backbone. This approach effectively handles higher resolutions without resorting to global compression, thus preserving detailed image representation throughout the diffusion process. Our focus on FLOP-efficient architectures in diffusion training marks a significant step forward. Comprehensive evaluations on both ImageNet and LSUN datasets at two resolutions demonstrate that DiffuSSMs are on par or even outperform existing diffusion models with attention modules in FID and Inception Score metrics while significantly reducing total FLOP usage.
On What Basis? Predicting Text Preference Via Structured Comparative Reasoning
Nov 14, 2023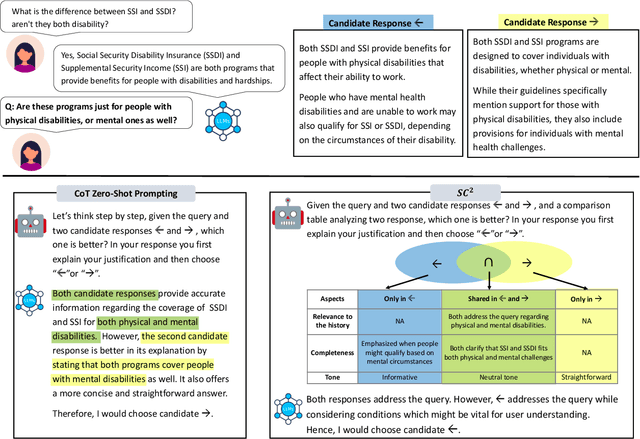

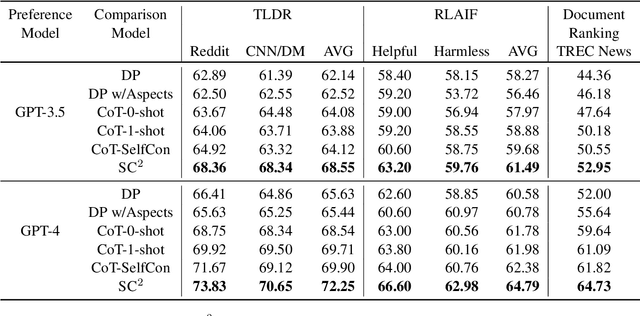
Comparative reasoning plays a crucial role in text preference prediction; however, large language models (LLMs) often demonstrate inconsistencies in their reasoning. While approaches like Chain-of-Thought improve accuracy in many other settings, they struggle to consistently distinguish the similarities and differences of complex texts. We introduce SC, a prompting approach that predicts text preferences by generating structured intermediate comparisons. SC begins by proposing aspects of comparison, followed by generating textual comparisons under each aspect. We select consistent comparisons with a pairwise consistency comparator that ensures each aspect's comparisons clearly distinguish differences between texts, significantly reducing hallucination and improving consistency. Our comprehensive evaluations across various NLP tasks, including summarization, retrieval, and automatic rating, demonstrate that SC equips LLMs to achieve state-of-the-art performance in text preference prediction.
Explanation-aware Soft Ensemble Empowers Large Language Model In-context Learning
Nov 13, 2023Large language models (LLMs) have shown remarkable capabilities in various natural language understanding tasks. With only a few demonstration examples, these LLMs can quickly adapt to target tasks without expensive gradient updates. Common strategies to boost such 'in-context' learning ability are to ensemble multiple model decoded results and require the model to generate an explanation along with the prediction. However, these models often treat different class predictions equally and neglect the potential discrepancy between the explanations and predictions. To fully unleash the power of explanations, we propose EASE, an Explanation-Aware Soft Ensemble framework to empower in-context learning with LLMs. We design two techniques, explanation-guided ensemble, and soft probability aggregation, to mitigate the effect of unreliable explanations and improve the consistency between explanations and final predictions. Experiments on seven natural language understanding tasks and four varying-size LLMs demonstrate the effectiveness of our proposed framework.
TimelineQA: A Benchmark for Question Answering over Timelines
Jun 01, 2023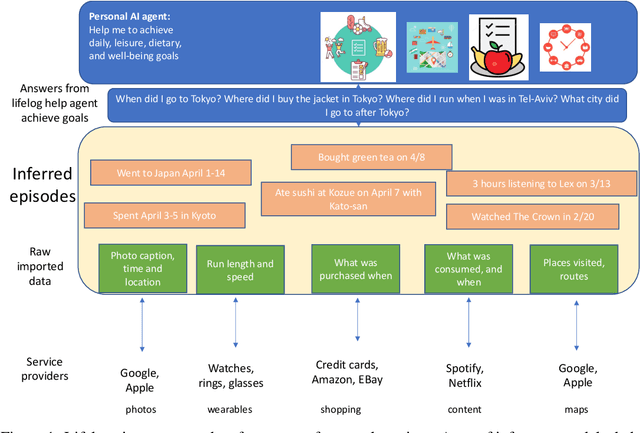



Lifelogs are descriptions of experiences that a person had during their life. Lifelogs are created by fusing data from the multitude of digital services, such as online photos, maps, shopping and content streaming services. Question answering over lifelogs can offer personal assistants a critical resource when they try to provide advice in context. However, obtaining answers to questions over lifelogs is beyond the current state of the art of question answering techniques for a variety of reasons, the most pronounced of which is that lifelogs combine free text with some degree of structure such as temporal and geographical information. We create and publicly release TimelineQA1, a benchmark for accelerating progress on querying lifelogs. TimelineQA generates lifelogs of imaginary people. The episodes in the lifelog range from major life episodes such as high school graduation to those that occur on a daily basis such as going for a run. We describe a set of experiments on TimelineQA with several state-of-the-art QA models. Our experiments reveal that for atomic queries, an extractive QA system significantly out-performs a state-of-the-art retrieval-augmented QA system. For multi-hop queries involving aggregates, we show that the best result is obtained with a state-of-the-art table QA technique, assuming the ground truth set of episodes for deriving the answer is available.
Pretraining Without Attention
Dec 20, 2022Transformers have been essential to pretraining success in NLP. Other architectures have been used, but require attention layers to match benchmark accuracy. This work explores pretraining without attention. We test recently developed routing layers based on state-space models (SSM) and model architectures based on multiplicative gating. Used together these modeling choices have a large impact on pretraining accuracy. Empirically the proposed Bidirectional Gated SSM (BiGS) replicates BERT pretraining results without attention and can be extended to long-form pretraining of 4096 tokens without approximation.