 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOPO: Policy Optimization using Ranked Rewards
Feb 01, 2026Standard reinforcement learning from human feedback (RLHF) trains a reward model on pairwise preference data and then uses it for policy optimization. However, while reward models are optimized to capture relative preferences, existing policy optimization techniques rely on absolute reward magnitudes during training. In settings where the rewards are non-verifiable such as summarization, instruction following, and chat completion, this misalignment often leads to suboptimal performance. We introduce Group Ordinal Policy Optimization (GOPO), a policy optimization method that uses only the ranking of the rewards and discards their magnitudes. Our rank-based transformation of rewards provides several gains, compared to Group Relative Policy Optimization (GRPO), in settings with non-verifiable rewards: (1) consistently higher training/validation reward trajectories, (2) improved LLM-as-judge evaluations across most intermediate training steps, and (3) reaching a policy of comparable quality in substantially less training steps than GRPO. We demonstrate consistent improvements across a range of tasks and model sizes.
OverFill: Two-Stage Models for Efficient Language Model Decoding
Aug 11, 2025Large language models (LLMs) excel across diverse tasks but face significant deployment challenges due to high inference costs. LLM inference comprises prefill (compute-bound) and decode (memory-bound) stages, with decode dominating latency particularly for long sequences. Current decoder-only models handle both stages uniformly, despite their distinct computational profiles. We propose OverFill, which decouples these stages to optimize accuracy-efficiency tradeoffs. OverFill begins with a full model for prefill, processing system and user inputs in parallel. It then switches to a dense pruned model, while generating tokens sequentially. Leveraging more compute during prefill, OverFill improves generation quality with minimal latency overhead. Our 3B-to-1B OverFill configuration outperforms 1B pruned models by 83.2%, while the 8B-to-3B configuration improves over 3B pruned models by 79.2% on average across standard benchmarks. OverFill matches the performance of same-sized models trained from scratch, while using significantly less training data. Our code is available at https://github.com/friendshipkim/overfill.
Approximating Language Model Training Data from Weights
Jun 18, 2025Modern language models often have open weights but closed training data. We formalize the problem of data approximation from model weights and propose several baselines and metrics. We develop a gradient-based approach that selects the highest-matching data from a large public text corpus and show its effectiveness at recovering useful data given only weights of the original and finetuned models. Even when none of the true training data is known, our method is able to locate a small subset of public Web documents can be used to train a model to close to the original model performance given models trained for both classification and supervised-finetuning. On the AG News classification task, our method improves performance from 65% (using randomly selected data) to 80%, approaching the expert benchmark of 88%. When applied to a model trained with SFT on MSMARCO web documents, our method reduces perplexity from 3.3 to 2.3, compared to an expert LLAMA model's perplexity of 2.0.
From Chat Logs to Collective Insights: Aggregative Question Answering
May 29, 2025Conversational agents powered by large language models (LLMs) are rapidly becoming integral to our daily interactions, generating unprecedented amounts of conversational data. Such datasets offer a powerful lens into societal interests, trending topics, and collective concerns. Yet, existing approaches typically treat these interactions as independent and miss critical insights that could emerge from aggregating and reasoning across large-scale conversation logs. In this paper, we introduce Aggregative Question Answering, a novel task requiring models to reason explicitly over thousands of user-chatbot interactions to answer aggregative queries, such as identifying emerging concerns among specific demographics. To enable research in this direction, we construct a benchmark, WildChat-AQA, comprising 6,027 aggregative questions derived from 182,330 real-world chatbot conversations. Experiments show that existing methods either struggle to reason effectively or incur prohibitive computational costs, underscoring the need for new approaches capable of extracting collective insights from large-scale conversational data.
NetFlowGen: Leveraging Generative Pre-training for Network Traffic Dynamics
Dec 30, 2024Understanding the traffic dynamics in networks is a core capability for automated systems to monitor and analyze networking behaviors, reducing expensive human efforts and economic risks through tasks such as traffic classification, congestion prediction, and attack detection. However, it is still challenging to accurately model network traffic with machine learning approaches in an efficient and broadly applicable manner. Task-specific models trained from scratch are used for different networking applications, which limits the efficiency of model development and generalization of model deployment. Furthermore, while networking data is abundant, high-quality task-specific labels are often insufficient for training individual models. Large-scale self-supervised learning on unlabeled data provides a natural pathway for tackling these challenges. We propose to pre-train a general-purpose machine learning model to capture traffic dynamics with only traffic data from NetFlow records, with the goal of fine-tuning for different downstream tasks with small amount of labels. Our presented NetFlowGen framework goes beyond a proof-of-concept for network traffic pre-training and addresses specific challenges such as unifying network feature representations, learning from large unlabeled traffic data volume, and testing on real downstream tasks in DDoS attack detection. Experiments demonstrate promising results of our pre-training framework on capturing traffic dynamics and adapting to different networking tasks.
Neuron Merging: Compensating for Pruned Neurons
Oct 25, 2020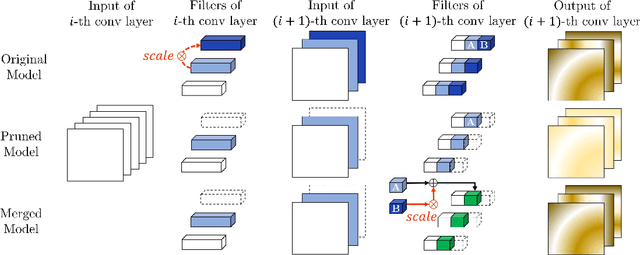
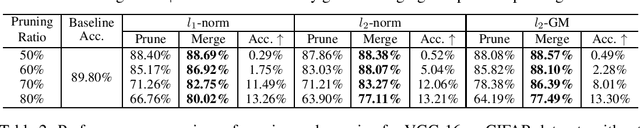
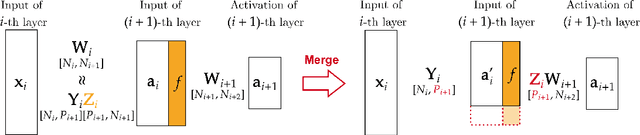
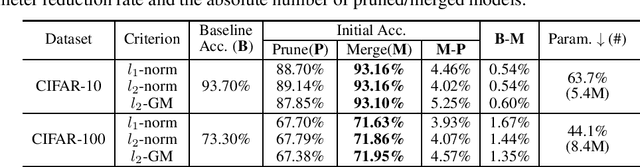
Network pruning is widely used to lighten and accelerate neural network models. Structured network pruning discards the whole neuron or filter, leading to accuracy loss. In this work, we propose a novel concept of neuron merging applicable to both fully connected layers and convolution layers, which compensates for the information loss due to the pruned neurons/filters. Neuron merging starts with decomposing the original weights into two matrices/tensors. One of them becomes the new weights for the current layer, and the other is what we name a scaling matrix, guiding the combination of neurons. If the activation function is ReLU, the scaling matrix can be absorbed into the next layer under certain conditions, compensating for the removed neurons. We also propose a data-free and inexpensive method to decompose the weights by utilizing the cosine similarity between neurons. Compared to the pruned model with the same topology, our merged model better preserves the output feature map of the original model; thus, it maintains the accuracy after pruning without fine-tuning. We demonstrate the effectiveness of our approach over network pruning for various model architectures and datasets. As an example, for VGG-16 on CIFAR-10, we achieve an accuracy of 93.16% while reducing 64% of total parameters, without any fine-tuning. The code can be found here: https://github.com/friendshipkim/neuron-merging
REPrune: Filter Pruning via Representative Election
Jul 21, 2020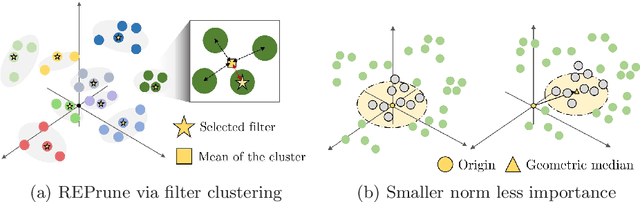
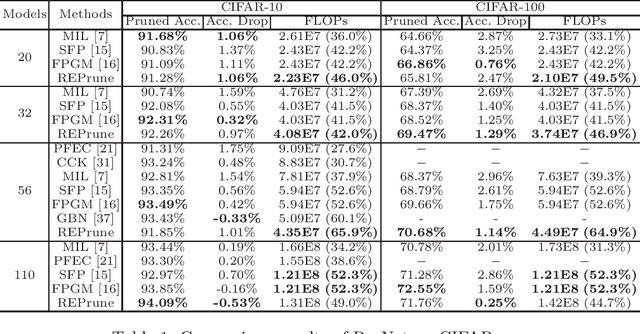
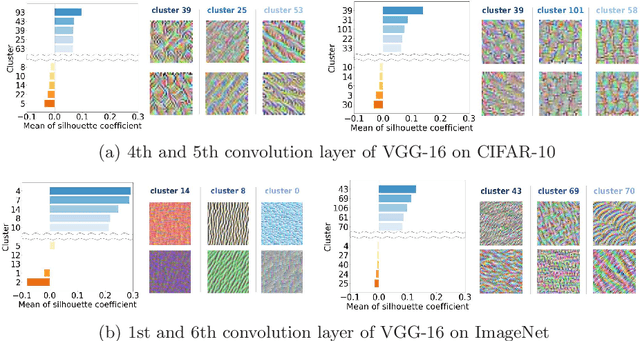
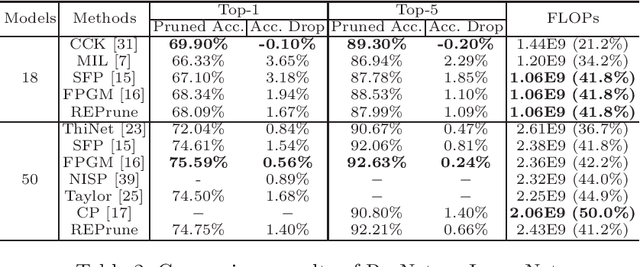
Even though norm-based filter pruning methods are widely accepted, it is questionable whether the "smaller-norm-less-important" criterion is optimal in determining filters to prune. Especially when we can keep only a small fraction of the original filters, it is more crucial to choose the filters that can best represent the whole filters regardless of norm values. Our novel pruning method entitled "REPrune" addresses this problem by selecting representative filters via clustering. By selecting one filter from a cluster of similar filters and avoiding selecting adjacent large filters, REPrune can achieve a better compression rate with similar accuracy. Our method also recovers the accuracy more rapidly and requires a smaller shift of filters during fine-tuning. Empirically, REPrune reduces more than 49% FLOPs, with 0.53% accuracy gain on ResNet-110 for CIFAR-10. Also, REPrune reduces more than 41.8% FLOPs with 1.67% Top-1 validation loss on ResNet-18 for ImageNet.