 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDitto: Accelerating Diffusion Model via Temporal Value Similarity
Jan 20, 2025



Diffusion models achieve superior performance in image generation tasks. However, it incurs significant computation overheads due to its iterative structure. To address these overheads, we analyze this iterative structure and observe that adjacent time steps in diffusion models exhibit high value similarity, leading to narrower differences between consecutive time steps. We adapt these characteristics to a quantized diffusion model and reveal that the majority of these differences can be represented with reduced bit-width, and even zero. Based on our observations, we propose the Ditto algorithm, a difference processing algorithm that leverages temporal similarity with quantization to enhance the efficiency of diffusion models. By exploiting the narrower differences and the distributive property of layer operations, it performs full bit-width operations for the initial time step and processes subsequent steps with temporal differences. In addition, Ditto execution flow optimization is designed to mitigate the memory overhead of temporal difference processing, further boosting the efficiency of the Ditto algorithm. We also design the Ditto hardware, a specialized hardware accelerator, fully exploiting the dynamic characteristics of the proposed algorithm. As a result, the Ditto hardware achieves up to 1.5x speedup and 17.74% energy saving compared to other accelerators.
Enhancing Quantum Memory Lifetime with Measurement-Free Local Error Correction and Reinforcement Learning
Aug 18, 2024Reliable quantum computation requires systematic identification and correction of errors that occur and accumulate in quantum hardware. To diagnose and correct such errors, standard quantum error-correcting protocols utilize $\textit{global}$ error information across the system obtained by mid-circuit readout of ancillary qubits. We investigate circuit-level error-correcting protocols that are measurement-free and based on $\textit{local}$ error information. Such a local error correction (LEC) circuit consists of faulty multi-qubit gates to perform both syndrome extraction and ancilla-controlled error removal. We develop and implement a reinforcement learning framework that takes a fixed set of faulty gates as inputs and outputs an optimized LEC circuit. To evaluate this approach, we quantitatively characterize an extension of logical qubit lifetime by a noisy LEC circuit. For the 2D classical Ising model and 4D toric code, our optimized LEC circuit performs better at extending a memory lifetime compared to a conventional LEC circuit based on Toom's rule in a sub-threshold gate error regime. We further show that such circuits can be used to reduce the rate of mid-circuit readouts to preserve a 2D toric code memory. Finally, we discuss the application of the LEC protocol on dissipative preparation of quantum states with topological phases.
REPrune: Channel Pruning via Kernel Representative Selection
Mar 08, 2024Channel pruning is widely accepted to accelerate modern convolutional neural networks (CNNs). The resulting pruned model benefits from its immediate deployment on general-purpose software and hardware resources. However, its large pruning granularity, specifically at the unit of a convolution filter, often leads to undesirable accuracy drops due to the inflexibility of deciding how and where to introduce sparsity to the CNNs. In this paper, we propose REPrune, a novel channel pruning technique that emulates kernel pruning, fully exploiting the finer but structured granularity. REPrune identifies similar kernels within each channel using agglomerative clustering. Then, it selects filters that maximize the incorporation of kernel representatives while optimizing the maximum cluster coverage problem. By integrating with a simultaneous training-pruning paradigm, REPrune promotes efficient, progressive pruning throughout training CNNs, avoiding the conventional train-prune-finetune sequence. Experimental results highlight that REPrune performs better in computer vision tasks than existing methods, effectively achieving a balance between acceleration ratio and performance retention.
Neuron Merging: Compensating for Pruned Neurons
Oct 25, 2020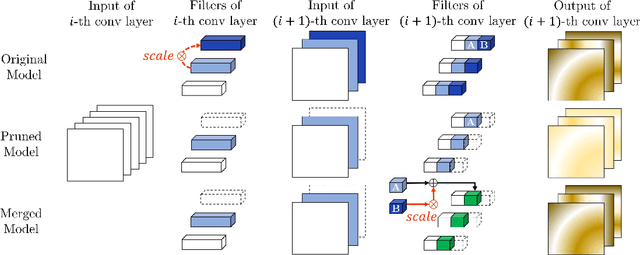
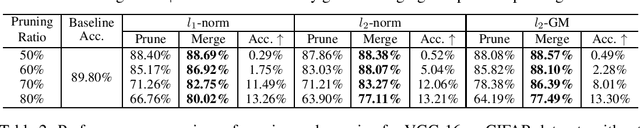
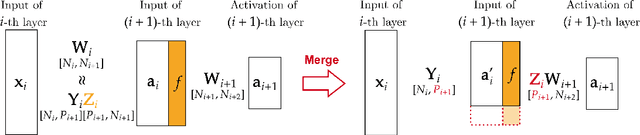
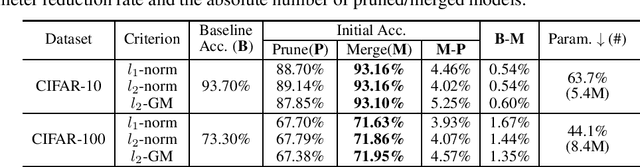
Network pruning is widely used to lighten and accelerate neural network models. Structured network pruning discards the whole neuron or filter, leading to accuracy loss. In this work, we propose a novel concept of neuron merging applicable to both fully connected layers and convolution layers, which compensates for the information loss due to the pruned neurons/filters. Neuron merging starts with decomposing the original weights into two matrices/tensors. One of them becomes the new weights for the current layer, and the other is what we name a scaling matrix, guiding the combination of neurons. If the activation function is ReLU, the scaling matrix can be absorbed into the next layer under certain conditions, compensating for the removed neurons. We also propose a data-free and inexpensive method to decompose the weights by utilizing the cosine similarity between neurons. Compared to the pruned model with the same topology, our merged model better preserves the output feature map of the original model; thus, it maintains the accuracy after pruning without fine-tuning. We demonstrate the effectiveness of our approach over network pruning for various model architectures and datasets. As an example, for VGG-16 on CIFAR-10, we achieve an accuracy of 93.16% while reducing 64% of total parameters, without any fine-tuning. The code can be found here: https://github.com/friendshipkim/neuron-merging
REPrune: Filter Pruning via Representative Election
Jul 21, 2020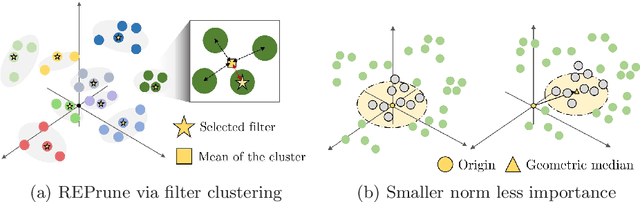
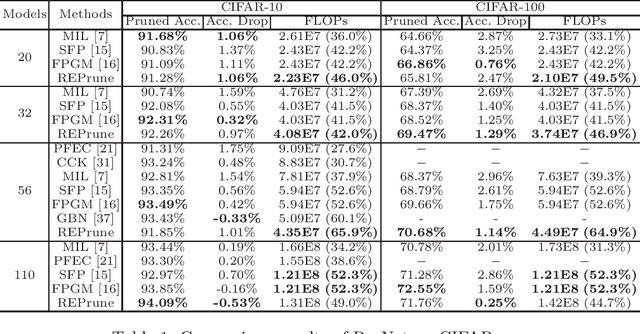
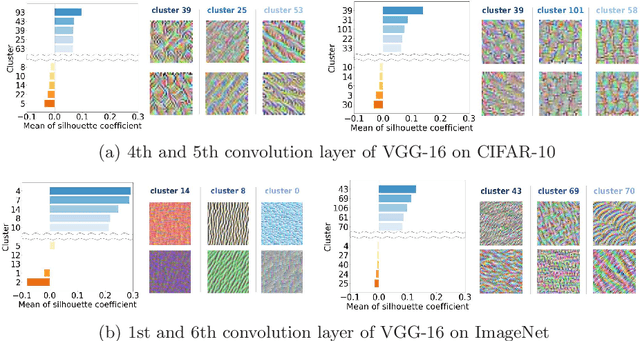
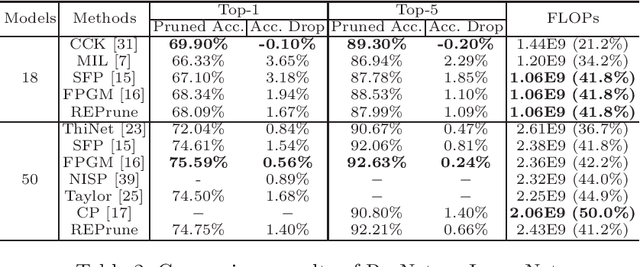
Even though norm-based filter pruning methods are widely accepted, it is questionable whether the "smaller-norm-less-important" criterion is optimal in determining filters to prune. Especially when we can keep only a small fraction of the original filters, it is more crucial to choose the filters that can best represent the whole filters regardless of norm values. Our novel pruning method entitled "REPrune" addresses this problem by selecting representative filters via clustering. By selecting one filter from a cluster of similar filters and avoiding selecting adjacent large filters, REPrune can achieve a better compression rate with similar accuracy. Our method also recovers the accuracy more rapidly and requires a smaller shift of filters during fine-tuning. Empirically, REPrune reduces more than 49% FLOPs, with 0.53% accuracy gain on ResNet-110 for CIFAR-10. Also, REPrune reduces more than 41.8% FLOPs with 1.67% Top-1 validation loss on ResNet-18 for ImageNet.