 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarizable atomic multipoles for learning long-range electrostatics
May 07, 2026Long-range electrostatics and polarization remain central obstacles to extending machine learning interatomic potentials (MLIPs) to ionic, polar, and interfacial systems. Here, we introduce a semi-local framework for learning electrostatics from energies and forces using polarizable atomic multipoles. Local equivariant descriptors predict environment-dependent latent monopoles, dipoles, and quadrupoles, while residual non-local charge transfer and polarization are captured by non-self-consistent linear response in induced charges and dipoles. Across four diverse benchmarks and four short-range MLIP architectures, the multipole hierarchy and response terms systematically improve potential energy surface accuracy, with the largest gains in systems where long-range effects are essential. More importantly, the learned latent variables recover physically meaningful electrical responses: accurate Born effective charge tensors, emergent polarizabilities, infrared spectra in close agreement with experiments, and semi-quantitative Raman spectra for bulk water and hybrid MAPbI$_3$ perovskite. This systematically improvable, physically transparent framework enables MLIPs trained on standard energy and force labels to predict polarization-sensitive observables.
LiveWeb-IE: A Benchmark For Online Web Information Extraction
Mar 14, 2026Web information extraction (WIE) is the task of automatically extracting data from web pages, offering high utility for various applications. The evaluation of WIE systems has traditionally relied on benchmarks built from HTML snapshots captured at a single point in time. However, this offline evaluation paradigm fails to account for the temporally evolving nature of the web; consequently, performance on these static benchmarks often fails to generalize to dynamic real-world scenarios. To bridge this gap, we introduce \dataset, a new benchmark designed for evaluating WIE systems directly against live websites. Based on trusted and permission-granted websites, we curate natural language queries that require information extraction of various data categories, such as text, images, and hyperlinks. We further design these queries to represent four levels of complexity, based on the number and cardinality of attributes to be extracted, enabling a granular assessment of WIE systems. In addition, we propose Visual Grounding Scraper (VGS), a novel multi-stage agentic framework that mimics human cognitive processes by visually narrowing down web page content to extract desired information. Extensive experiments across diverse backbone models demonstrate the effectiveness and robustness of VGS. We believe that this study lays the foundation for developing practical and robust WIE systems.
Diffusion-Based sRGB Real Noise Generation via Prompt-Driven Noise Representation Learning
Mar 05, 2026Denoising in the sRGB image space is challenging due to noise variability. Although end-to-end methods perform well, their effectiveness in real-world scenarios is limited by the scarcity of real noisy-clean image pairs, which are expensive and difficult to collect. To address this limitation, several generative methods have been developed to synthesize realistic noisy images from limited data. These generative approaches often rely on camera metadata during both training and testing to synthesize real-world noise. However, the lack of metadata or inconsistencies between devices restricts their usability. Therefore, we propose a novel framework called Prompt-Driven Noise Generation (PNG). This model is capable of acquiring high-dimensional prompt features that capture the characteristics of real-world input noise and creating a variety of realistic noisy images consistent with the distribution of the input noise. By eliminating the dependency on explicit camera metadata, our approach significantly enhances the generalizability and applicability of noise synthesis. Comprehensive experiments reveal that our model effectively produces realistic noisy images and show the successful application of these generated images in removing real-world noise across various benchmark datasets.
ExpGuard: LLM Content Moderation in Specialized Domains
Mar 03, 2026With the growing deployment of large language models (LLMs) in real-world applications, establishing robust safety guardrails to moderate their inputs and outputs has become essential to ensure adherence to safety policies. Current guardrail models predominantly address general human-LLM interactions, rendering LLMs vulnerable to harmful and adversarial content within domain-specific contexts, particularly those rich in technical jargon and specialized concepts. To address this limitation, we introduce ExpGuard, a robust and specialized guardrail model designed to protect against harmful prompts and responses across financial, medical, and legal domains. In addition, we present ExpGuardMix, a meticulously curated dataset comprising 58,928 labeled prompts paired with corresponding refusal and compliant responses, from these specific sectors. This dataset is divided into two subsets: ExpGuardTrain, for model training, and ExpGuardTest, a high-quality test set annotated by domain experts to evaluate model robustness against technical and domain-specific content. Comprehensive evaluations conducted on ExpGuardTest and eight established public benchmarks reveal that ExpGuard delivers competitive performance across the board while demonstrating exceptional resilience to domain-specific adversarial attacks, surpassing state-of-the-art models such as WildGuard by up to 8.9% in prompt classification and 15.3% in response classification. To encourage further research and development, we open-source our code, data, and model, enabling adaptation to additional domains and supporting the creation of increasingly robust guardrail models.
Continuous Degradation Modeling via Latent Flow Matching for Real-World Super-Resolution
Feb 04, 2026While deep learning-based super-resolution (SR) methods have shown impressive outcomes with synthetic degradation scenarios such as bicubic downsampling, they frequently struggle to perform well on real-world images that feature complex, nonlinear degradations like noise, blur, and compression artifacts. Recent efforts to address this issue have involved the painstaking compilation of real low-resolution (LR) and high-resolution (HR) image pairs, usually limited to several specific downscaling factors. To address these challenges, our work introduces a novel framework capable of synthesizing authentic LR images from a single HR image by leveraging the latent degradation space with flow matching. Our approach generates LR images with realistic artifacts at unseen degradation levels, which facilitates the creation of large-scale, real-world SR training datasets. Comprehensive quantitative and qualitative assessments verify that our synthetic LR images accurately replicate real-world degradations. Furthermore, both traditional and arbitrary-scale SR models trained using our datasets consistently yield much better HR outcomes.
InsertAnywhere: Bridging 4D Scene Geometry and Diffusion Models for Realistic Video Object Insertion
Dec 19, 2025Recent advances in diffusion-based video generation have opened new possibilities for controllable video editing, yet realistic video object insertion (VOI) remains challenging due to limited 4D scene understanding and inadequate handling of occlusion and lighting effects. We present InsertAnywhere, a new VOI framework that achieves geometrically consistent object placement and appearance-faithful video synthesis. Our method begins with a 4D aware mask generation module that reconstructs the scene geometry and propagates user specified object placement across frames while maintaining temporal coherence and occlusion consistency. Building upon this spatial foundation, we extend a diffusion based video generation model to jointly synthesize the inserted object and its surrounding local variations such as illumination and shading. To enable supervised training, we introduce ROSE++, an illumination aware synthetic dataset constructed by transforming the ROSE object removal dataset into triplets of object removed video, object present video, and a VLM generated reference image. Through extensive experiments, we demonstrate that our framework produces geometrically plausible and visually coherent object insertions across diverse real world scenarios, significantly outperforming existing research and commercial models.
Long-range electrostatics for machine learning interatomic potentials is easier than we thought
Dec 19, 2025The lack of long-range electrostatics is a key limitation of modern machine learning interatomic potentials (MLIPs), hindering reliable applications to interfaces, charge-transfer reactions, polar and ionic materials, and biomolecules. In this Perspective, we distill two design principles behind the Latent Ewald Summation (LES) framework, which can capture long-range interactions, charges, and electrical response just by learning from standard energy and force training data: (i) use a Coulomb functional form with environment-dependent charges to capture electrostatic interactions, and (ii) avoid explicit training on ambiguous density functional theory (DFT) partial charges. When both principles are satisfied, substantial flexibility remains: essentially any short-range MLIP can be augmented; charge equilibration schemes can be added when desired; dipoles and Born effective charges can be inferred or finetuned; and charge/spin-state embeddings or tensorial targets can be further incorporated. We also discuss current limitations and open challenges. Together, these minimal, physics-guided design rules suggest that incorporating long-range electrostatics into MLIPs is simpler and perhaps more broadly applicable than is commonly assumed.
IDF: Iterative Dynamic Filtering Networks for Generalizable Image Denoising
Aug 27, 2025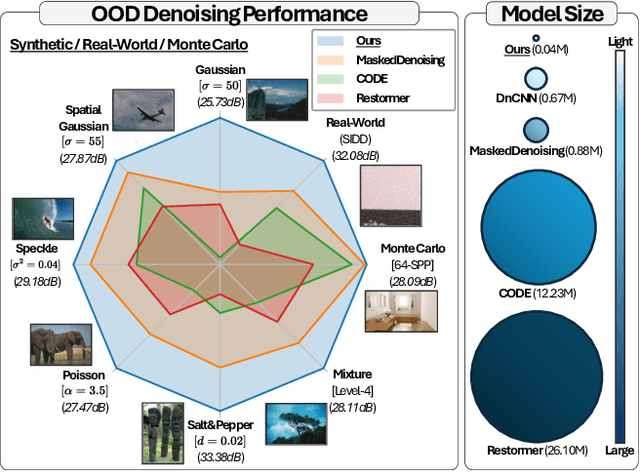
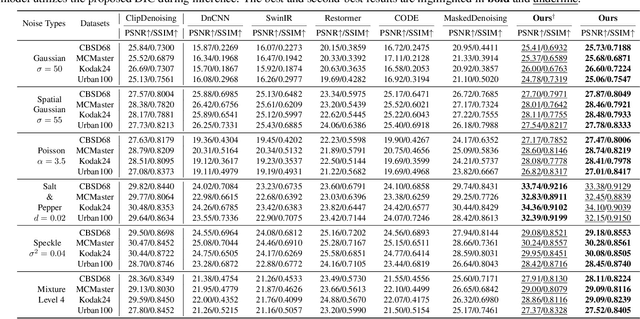

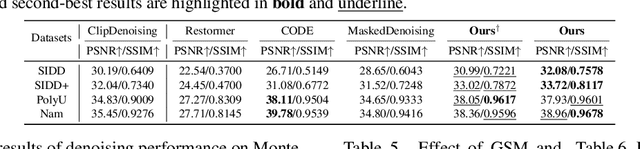
Image denoising is a fundamental challenge in computer vision, with applications in photography and medical imaging. While deep learning-based methods have shown remarkable success, their reliance on specific noise distributions limits generalization to unseen noise types and levels. Existing approaches attempt to address this with extensive training data and high computational resources but they still suffer from overfitting. To address these issues, we conduct image denoising by utilizing dynamically generated kernels via efficient operations. This approach helps prevent overfitting and improves resilience to unseen noise. Specifically, our method leverages a Feature Extraction Module for robust noise-invariant features, Global Statistics and Local Correlation Modules to capture comprehensive noise characteristics and structural correlations. The Kernel Prediction Module then employs these cues to produce pixel-wise varying kernels adapted to local structures, which are then applied iteratively for denoising. This ensures both efficiency and superior restoration quality. Despite being trained on single-level Gaussian noise, our compact model (~ 0.04 M) excels across diverse noise types and levels, demonstrating the promise of iterative dynamic filtering for practical image denoising.
Harnessing Meta-Learning for Controllable Full-Frame Video Stabilization
Aug 26, 2025Video stabilization remains a fundamental problem in computer vision, particularly pixel-level synthesis solutions for video stabilization, which synthesize full-frame outputs, add to the complexity of this task. These methods aim to enhance stability while synthesizing full-frame videos, but the inherent diversity in motion profiles and visual content present in each video sequence makes robust generalization with fixed parameters difficult. To address this, we present a novel method that improves pixel-level synthesis video stabilization methods by rapidly adapting models to each input video at test time. The proposed approach takes advantage of low-level visual cues available during inference to improve both the stability and visual quality of the output. Notably, the proposed rapid adaptation achieves significant performance gains even with a single adaptation pass. We further propose a jerk localization module and a targeted adaptation strategy, which focuses the adaptation on high-jerk segments for maximizing stability with fewer adaptation steps. The proposed methodology enables modern stabilizers to overcome the longstanding SOTA approaches while maintaining the full frame nature of the modern methods, while offering users with control mechanisms akin to classical approaches. Extensive experiments on diverse real-world datasets demonstrate the versatility of the proposed method. Our approach consistently improves the performance of various full-frame synthesis models in both qualitative and quantitative terms, including results on downstream applications.
TV-LiVE: Training-Free, Text-Guided Video Editing via Layer Informed Vitality Exploitation
Jun 08, 2025

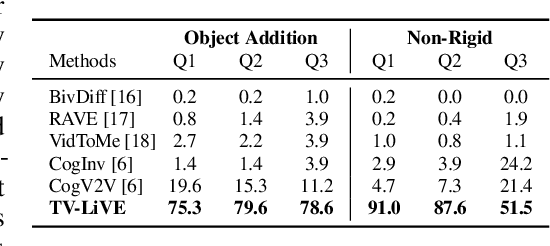

Video editing has garnered increasing attention alongside the rapid progress of diffusion-based video generation models. As part of these advancements, there is a growing demand for more accessible and controllable forms of video editing, such as prompt-based editing. Previous studies have primarily focused on tasks such as style transfer, background replacement, object substitution, and attribute modification, while maintaining the content structure of the source video. However, more complex tasks, including the addition of novel objects and nonrigid transformations, remain relatively unexplored. In this paper, we present TV-LiVE, a Training-free and text-guided Video editing framework via Layerinformed Vitality Exploitation. We empirically identify vital layers within the video generation model that significantly influence the quality of generated outputs. Notably, these layers are closely associated with Rotary Position Embeddings (RoPE). Based on this observation, our method enables both object addition and non-rigid video editing by selectively injecting key and value features from the source model into the corresponding layers of the target model guided by the layer vitality. For object addition, we further identify prominent layers to extract the mask regions corresponding to the newly added target prompt. We found that the extracted masks from the prominent layers faithfully indicate the region to be edited. Experimental results demonstrate that TV-LiVE outperforms existing approaches for both object addition and non-rigid video editing. Project Page: https://emjay73.github.io/TV_LiVE/