 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Video, Catch Keyword: Context-aware Keyword Attention for Moment Retrieval and Highlight Detection
Jan 05, 2025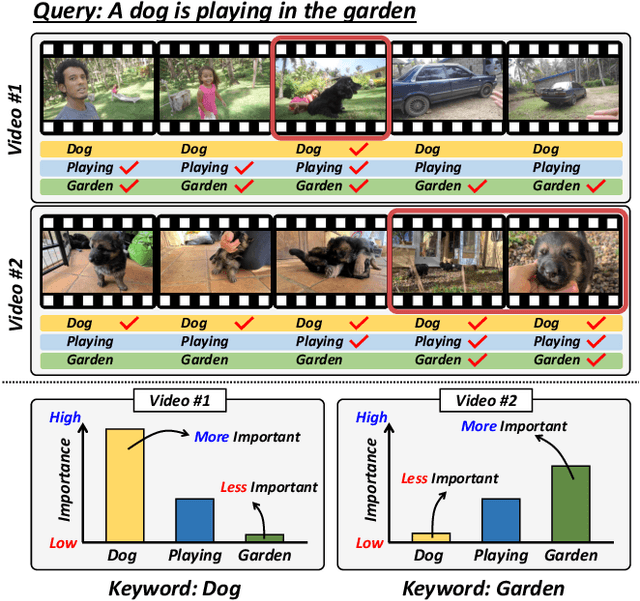
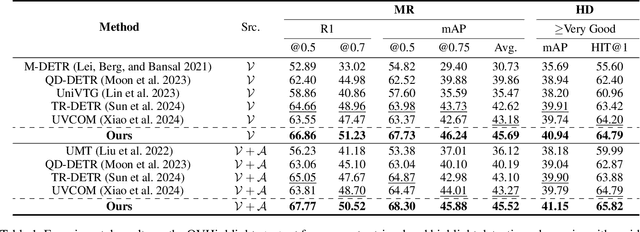
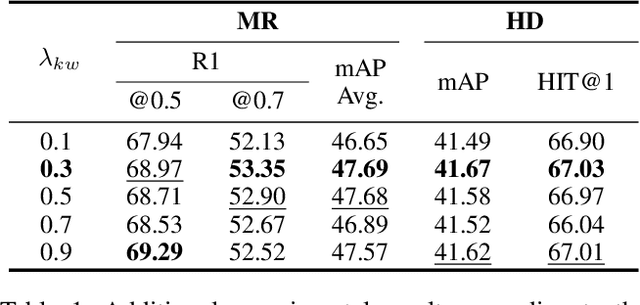
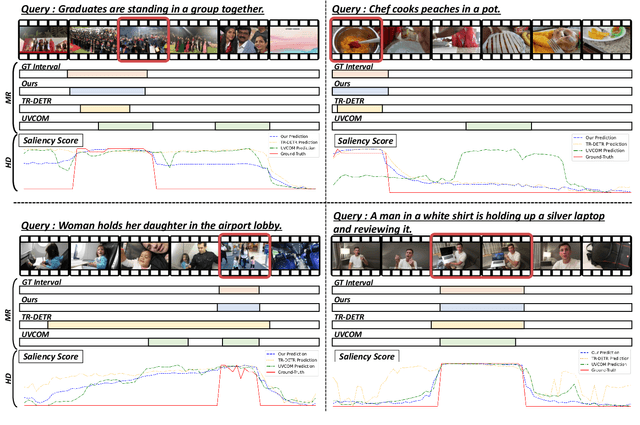
The goal of video moment retrieval and highlight detection is to identify specific segments and highlights based on a given text query. With the rapid growth of video content and the overlap between these tasks, recent works have addressed both simultaneously. However, they still struggle to fully capture the overall video context, making it challenging to determine which words are most relevant. In this paper, we present a novel Video Context-aware Keyword Attention module that overcomes this limitation by capturing keyword variation within the context of the entire video. To achieve this, we introduce a video context clustering module that provides concise representations of the overall video context, thereby enhancing the understanding of keyword dynamics. Furthermore, we propose a keyword weight detection module with keyword-aware contrastive learning that incorporates keyword information to enhance fine-grained alignment between visual and textual features. Extensive experiments on the QVHighlights, TVSum, and Charades-STA benchmarks demonstrate that our proposed method significantly improves performance in moment retrieval and highlight detection tasks compared to existing approaches. Our code is available at: https://github.com/VisualAIKHU/Keyword-DETR
Learning to Visually Localize Sound Sources from Mixtures without Prior Source Knowledge
Mar 26, 2024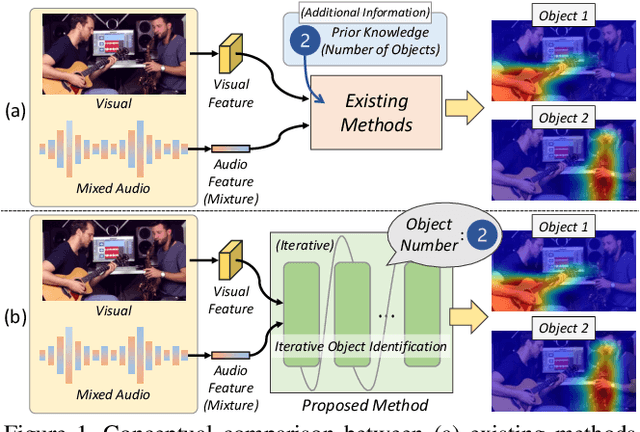
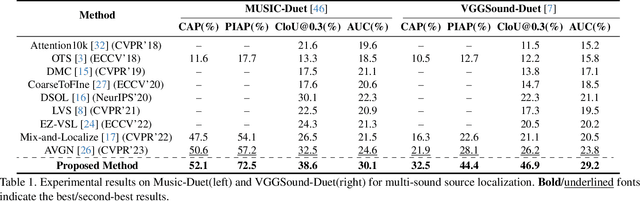
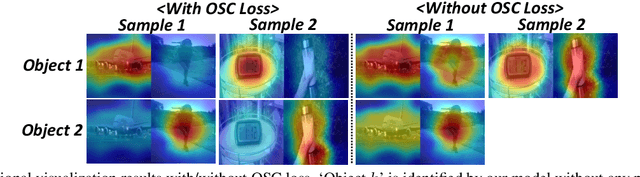
The goal of the multi-sound source localization task is to localize sound sources from the mixture individually. While recent multi-sound source localization methods have shown improved performance, they face challenges due to their reliance on prior information about the number of objects to be separated. In this paper, to overcome this limitation, we present a novel multi-sound source localization method that can perform localization without prior knowledge of the number of sound sources. To achieve this goal, we propose an iterative object identification (IOI) module, which can recognize sound-making objects in an iterative manner. After finding the regions of sound-making objects, we devise object similarity-aware clustering (OSC) loss to guide the IOI module to effectively combine regions of the same object but also distinguish between different objects and backgrounds. It enables our method to perform accurate localization of sound-making objects without any prior knowledge. Extensive experimental results on the MUSIC and VGGSound benchmarks show the significant performance improvements of the proposed method over the existing methods for both single and multi-source. Our code is available at: https://github.com/VisualAIKHU/NoPrior_MultiSSL
Audio-Visual Spatial Integration and Recursive Attention for Robust Sound Source Localization
Aug 18, 2023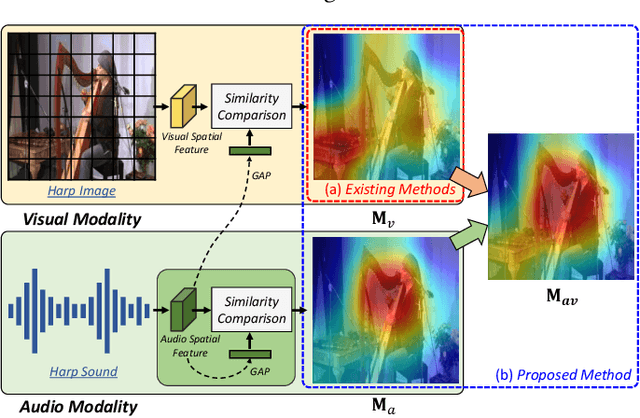
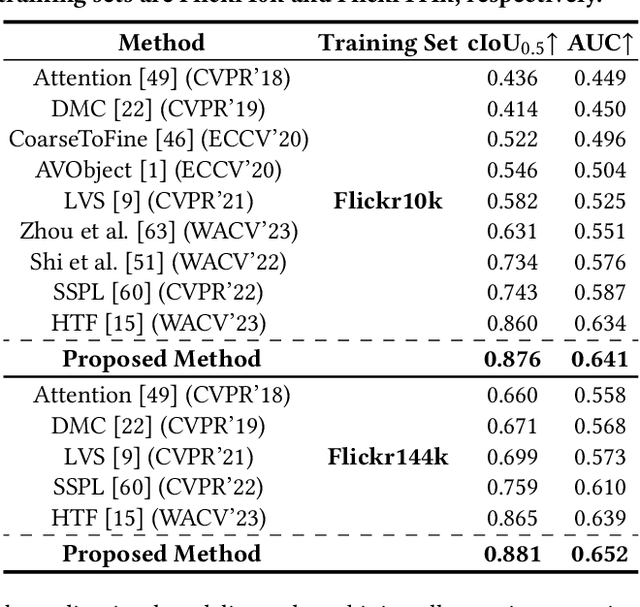

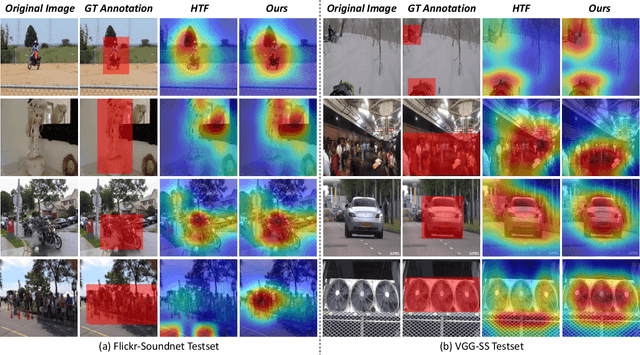
The objective of the sound source localization task is to enable machines to detect the location of sound-making objects within a visual scene. While the audio modality provides spatial cues to locate the sound source, existing approaches only use audio as an auxiliary role to compare spatial regions of the visual modality. Humans, on the other hand, utilize both audio and visual modalities as spatial cues to locate sound sources. In this paper, we propose an audio-visual spatial integration network that integrates spatial cues from both modalities to mimic human behavior when detecting sound-making objects. Additionally, we introduce a recursive attention network to mimic human behavior of iterative focusing on objects, resulting in more accurate attention regions. To effectively encode spatial information from both modalities, we propose audio-visual pair matching loss and spatial region alignment loss. By utilizing the spatial cues of audio-visual modalities and recursively focusing objects, our method can perform more robust sound source localization. Comprehensive experimental results on the Flickr SoundNet and VGG-Sound Source datasets demonstrate the superiority of our proposed method over existing approaches. Our code is available at: https://github.com/VisualAIKHU/SIRA-SSL