 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Adaptation to Generalization: Adaptive Visual Prompting for Medical Image Segmentation
Apr 19, 2026Visual prompting has emerged as a powerful method for adapting pre-trained models to new domains without updating model parameters. However, existing prompting methods typically optimize a single prompt per domain and apply it uniformly to all inputs, limiting their ability to generalize under intra and inter-domain variability, which is especially critical in the medical field. To address this, we propose APEX, an Adaptive Prompt EXtraction framework that retrieves input-specific prompts from a learnable prompt memory. The memory stores diverse, domain-discriminative prompt representations and is queried via domain features extracted from the Fourier spectrum. To learn robust and discriminative domain features, we introduce a novel Low-Frequency Feature Contrastive (LFC) learning framework that clusters representations from the same domain while separating those from different domains. Extensive experiments on two medical segmentation tasks demonstrate that APEX significantly improves generalization across both seen and unseen domains. Furthermore, it complements any existing backbones and consistently enhances performance, confirming its effectiveness as a plug-and-play prompting solution in medical fields. The code is available at https://github.com/cetinkayaevren/apex/
Generate, Analyze, and Refine: Training-Free Sound Source Localization via MLLM Meta-Reasoning
Apr 08, 2026Sound source localization task aims to identify the locations of sound-emitting objects by leveraging correlations between audio and visual modalities. Most existing SSL methods rely on contrastive learning-based feature matching, but lack explicit reasoning and verification, limiting their effectiveness in complex acoustic scenes. Inspired by human meta-cognitive processes, we propose a training-free SSL framework that exploits the intrinsic reasoning capabilities of Multimodal Large Language Models (MLLMs). Our Generation-Analysis-Refinement (GAR) pipeline consists of three stages: Generation produces initial bounding boxes and audio classifications; Analysis quantifies Audio-Visual Consistency via open-set role tagging and anchor voting; and Refinement applies adaptive gating to prevent unnecessary adjustments. Extensive experiments on single-source and multi-source benchmarks demonstrate competitive performance. The source code is available at https://github.com/VisualAIKHU/GAR-SSL.
Task Prototype-Based Knowledge Retrieval for Multi-Task Learning from Partially Annotated Data
Jan 12, 2026Multi-task learning (MTL) is critical in real-world applications such as autonomous driving and robotics, enabling simultaneous handling of diverse tasks. However, obtaining fully annotated data for all tasks is impractical due to labeling costs. Existing methods for partially labeled MTL typically rely on predictions from unlabeled tasks, making it difficult to establish reliable task associations and potentially leading to negative transfer and suboptimal performance. To address these issues, we propose a prototype-based knowledge retrieval framework that achieves robust MTL instead of relying on predictions from unlabeled tasks. Our framework consists of two key components: (1) a task prototype embedding task-specific characteristics and quantifying task associations, and (2) a knowledge retrieval transformer that adaptively refines feature representations based on these associations. To achieve this, we introduce an association knowledge generating (AKG) loss to ensure the task prototype consistently captures task-specific characteristics. Extensive experiments demonstrate the effectiveness of our framework, highlighting its potential for robust multi-task learning, even when only a subset of tasks is annotated.
Learning from Oblivion: Predicting Knowledge Overflowed Weights via Retrodiction of Forgetting
Aug 07, 2025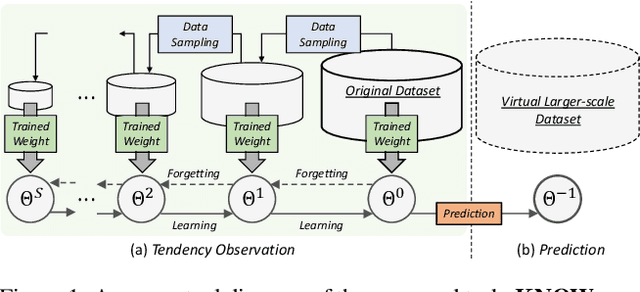
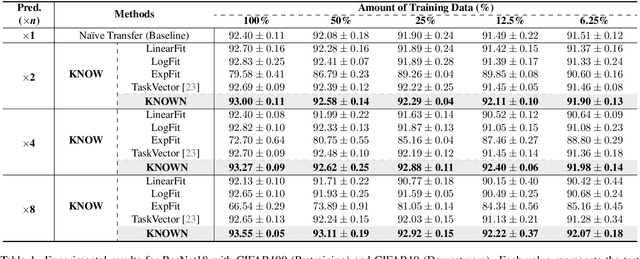
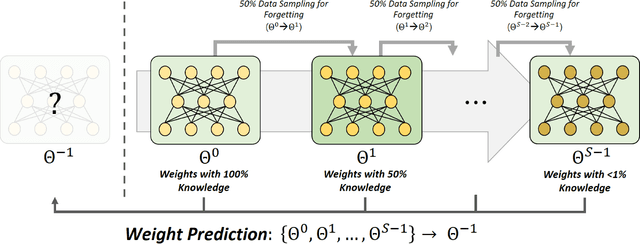
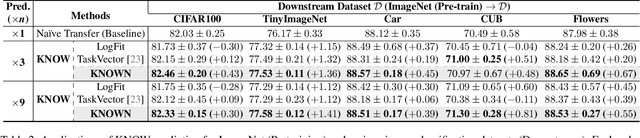
Pre-trained weights have become a cornerstone of modern deep learning, enabling efficient knowledge transfer and improving downstream task performance, especially in data-scarce scenarios. However, a fundamental question remains: how can we obtain better pre-trained weights that encapsulate more knowledge beyond the given dataset? In this work, we introduce \textbf{KNowledge Overflowed Weights (KNOW)} prediction, a novel strategy that leverages structured forgetting and its inversion to synthesize knowledge-enriched weights. Our key insight is that sequential fine-tuning on progressively downsized datasets induces a structured forgetting process, which can be modeled and reversed to recover knowledge as if trained on a larger dataset. We construct a dataset of weight transitions governed by this controlled forgetting and employ meta-learning to model weight prediction effectively. Specifically, our \textbf{KNowledge Overflowed Weights Nowcaster (KNOWN)} acts as a hyper-model that learns the general evolution of weights and predicts enhanced weights with improved generalization. Extensive experiments across diverse datasets and architectures demonstrate that KNOW prediction consistently outperforms Na\"ive fine-tuning and simple weight prediction, leading to superior downstream performance. Our work provides a new perspective on reinterpreting forgetting dynamics to push the limits of knowledge transfer in deep learning.
Watch Video, Catch Keyword: Context-aware Keyword Attention for Moment Retrieval and Highlight Detection
Jan 05, 2025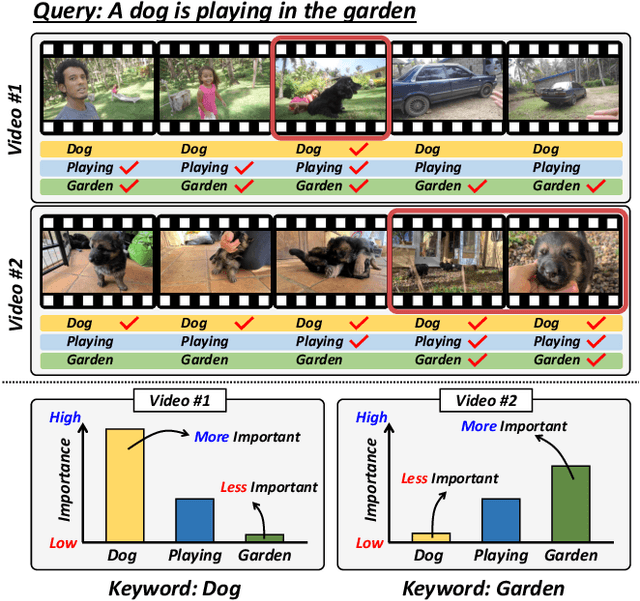
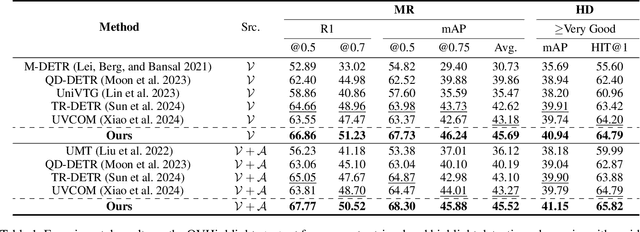
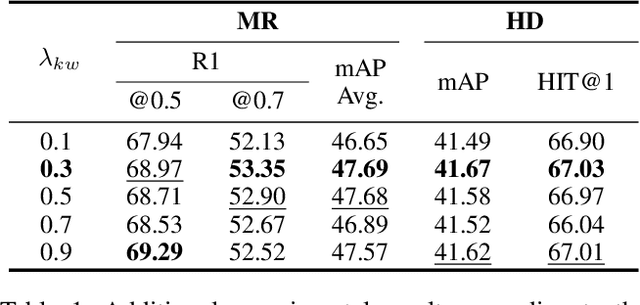
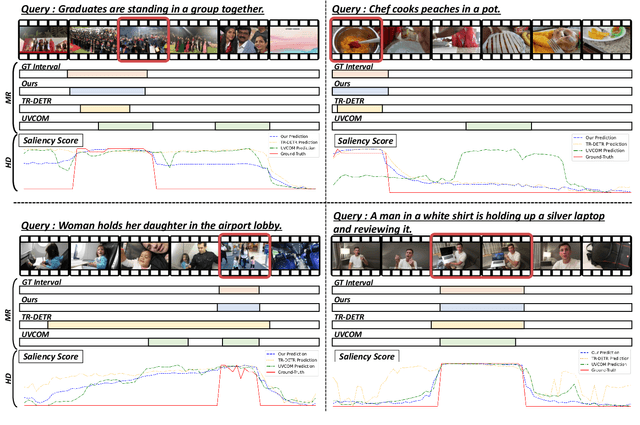
The goal of video moment retrieval and highlight detection is to identify specific segments and highlights based on a given text query. With the rapid growth of video content and the overlap between these tasks, recent works have addressed both simultaneously. However, they still struggle to fully capture the overall video context, making it challenging to determine which words are most relevant. In this paper, we present a novel Video Context-aware Keyword Attention module that overcomes this limitation by capturing keyword variation within the context of the entire video. To achieve this, we introduce a video context clustering module that provides concise representations of the overall video context, thereby enhancing the understanding of keyword dynamics. Furthermore, we propose a keyword weight detection module with keyword-aware contrastive learning that incorporates keyword information to enhance fine-grained alignment between visual and textual features. Extensive experiments on the QVHighlights, TVSum, and Charades-STA benchmarks demonstrate that our proposed method significantly improves performance in moment retrieval and highlight detection tasks compared to existing approaches. Our code is available at: https://github.com/VisualAIKHU/Keyword-DETR
Multispectral Pedestrian Detection with Sparsely Annotated Label
Jan 05, 2025



Although existing Sparsely Annotated Object Detection (SAOD) approches have made progress in handling sparsely annotated environments in multispectral domain, where only some pedestrians are annotated, they still have the following limitations: (i) they lack considerations for improving the quality of pseudo-labels for missing annotations, and (ii) they rely on fixed ground truth annotations, which leads to learning only a limited range of pedestrian visual appearances in the multispectral domain. To address these issues, we propose a novel framework called Sparsely Annotated Multispectral Pedestrian Detection (SAMPD). For limitation (i), we introduce Multispectral Pedestrian-aware Adaptive Weight (MPAW) and Positive Pseudo-label Enhancement (PPE) module. Utilizing multispectral knowledge, these modules ensure the generation of high-quality pseudo-labels and enable effective learning by increasing weights for high-quality pseudo-labels based on modality characteristics. To address limitation (ii), we propose an Adaptive Pedestrian Retrieval Augmentation (APRA) module, which adaptively incorporates pedestrian patches from ground-truth and dynamically integrates high-quality pseudo-labels with the ground-truth, facilitating a more diverse learning pool of pedestrians. Extensive experimental results demonstrate that our SAMPD significantly enhances performance in sparsely annotated environments within the multispectral domain.
Towards Model-Agnostic Dataset Condensation by Heterogeneous Models
Sep 22, 2024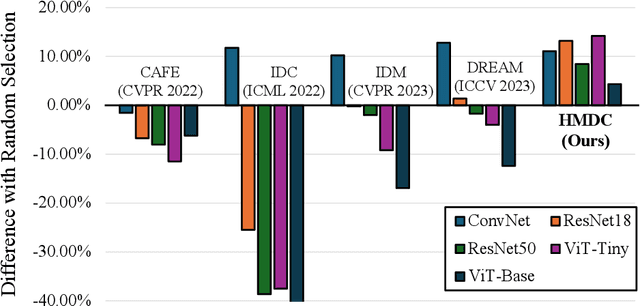
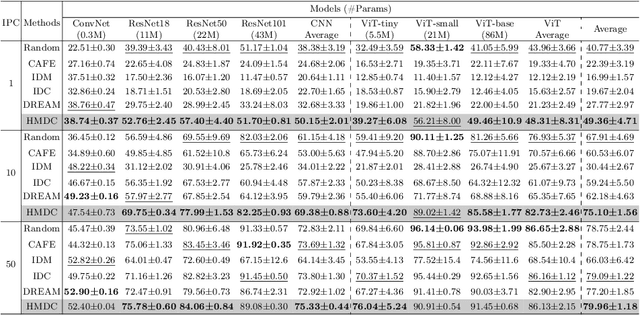
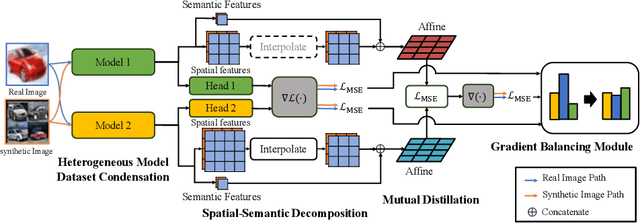

Abstract. The advancement of deep learning has coincided with the proliferation of both models and available data. The surge in dataset sizes and the subsequent surge in computational requirements have led to the development of the Dataset Condensation (DC). While prior studies have delved into generating synthetic images through methods like distribution alignment and training trajectory tracking for more efficient model training, a significant challenge arises when employing these condensed images practically. Notably, these condensed images tend to be specific to particular models, constraining their versatility and practicality. In response to this limitation, we introduce a novel method, Heterogeneous Model Dataset Condensation (HMDC), designed to produce universally applicable condensed images through cross-model interactions. To address the issues of gradient magnitude difference and semantic distance in models when utilizing heterogeneous models, we propose the Gradient Balance Module (GBM) and Mutual Distillation (MD) with the SpatialSemantic Decomposition method. By balancing the contribution of each model and maintaining their semantic meaning closely, our approach overcomes the limitations associated with model-specific condensed images and enhances the broader utility. The source code is available in https://github.com/KHU-AGI/HMDC.
Learning Trimodal Relation for Audio-Visual Question Answering with Missing Modality
Jul 23, 2024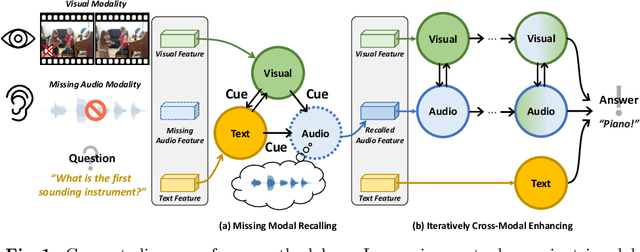
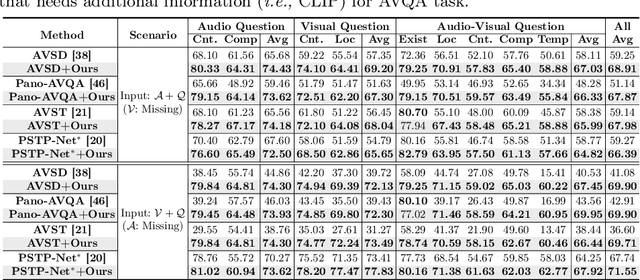
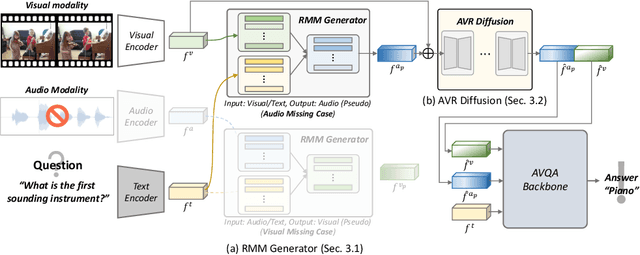
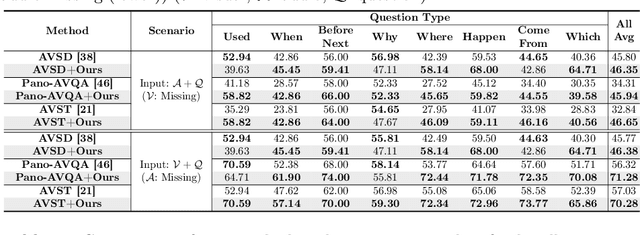
Recent Audio-Visual Question Answering (AVQA) methods rely on complete visual and audio input to answer questions accurately. However, in real-world scenarios, issues such as device malfunctions and data transmission errors frequently result in missing audio or visual modality. In such cases, existing AVQA methods suffer significant performance degradation. In this paper, we propose a framework that ensures robust AVQA performance even when a modality is missing. First, we propose a Relation-aware Missing Modal (RMM) generator with Relation-aware Missing Modal Recalling (RMMR) loss to enhance the ability of the generator to recall missing modal information by understanding the relationships and context among the available modalities. Second, we design an Audio-Visual Relation-aware (AVR) diffusion model with Audio-Visual Enhancing (AVE) loss to further enhance audio-visual features by leveraging the relationships and shared cues between the audio-visual modalities. As a result, our method can provide accurate answers by effectively utilizing available information even when input modalities are missing. We believe our method holds potential applications not only in AVQA research but also in various multi-modal scenarios.
MonoWAD: Weather-Adaptive Diffusion Model for Robust Monocular 3D Object Detection
Jul 23, 2024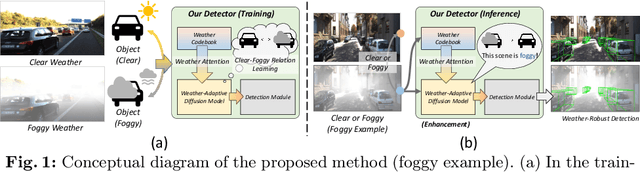
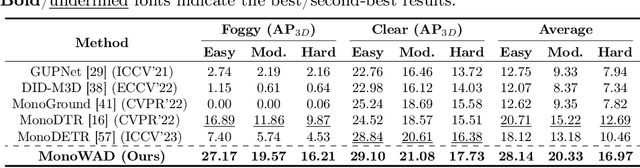
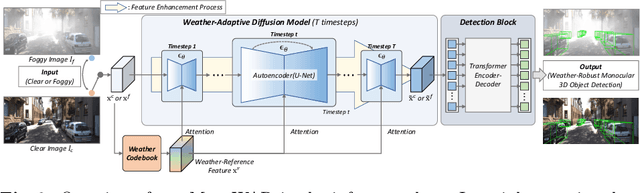
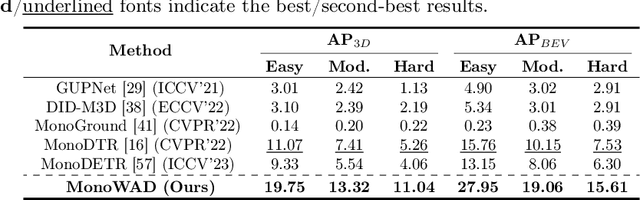
Monocular 3D object detection is an important challenging task in autonomous driving. Existing methods mainly focus on performing 3D detection in ideal weather conditions, characterized by scenarios with clear and optimal visibility. However, the challenge of autonomous driving requires the ability to handle changes in weather conditions, such as foggy weather, not just clear weather. We introduce MonoWAD, a novel weather-robust monocular 3D object detector with a weather-adaptive diffusion model. It contains two components: (1) the weather codebook to memorize the knowledge of the clear weather and generate a weather-reference feature for any input, and (2) the weather-adaptive diffusion model to enhance the feature representation of the input feature by incorporating a weather-reference feature. This serves an attention role in indicating how much improvement is needed for the input feature according to the weather conditions. To achieve this goal, we introduce a weather-adaptive enhancement loss to enhance the feature representation under both clear and foggy weather conditions. Extensive experiments under various weather conditions demonstrate that MonoWAD achieves weather-robust monocular 3D object detection. The code and dataset are released at https://github.com/VisualAIKHU/MonoWAD.
Learning to Visually Localize Sound Sources from Mixtures without Prior Source Knowledge
Mar 26, 2024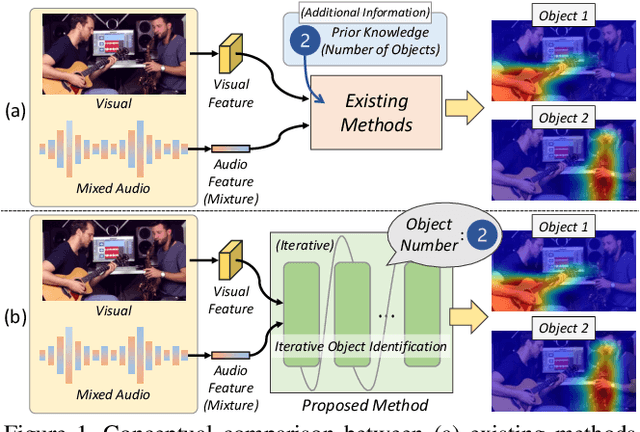
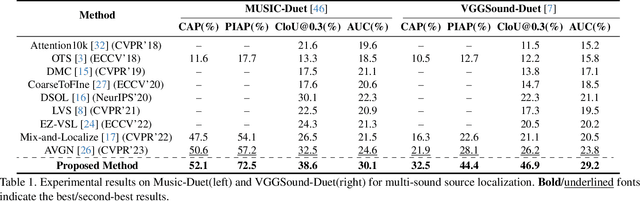
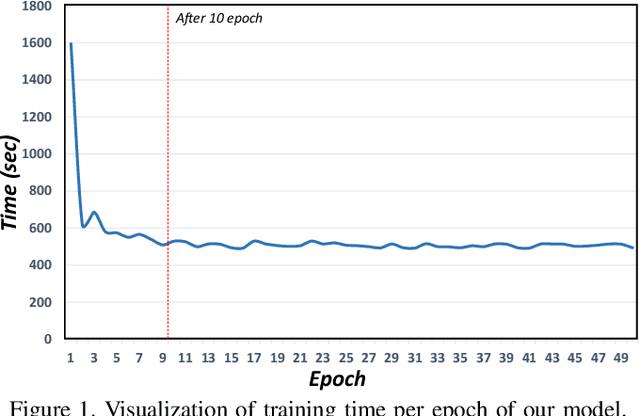
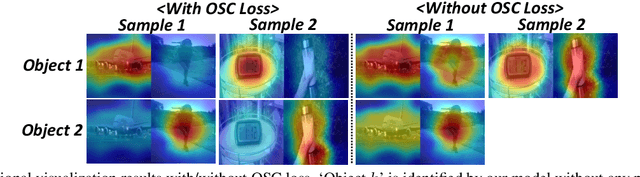
The goal of the multi-sound source localization task is to localize sound sources from the mixture individually. While recent multi-sound source localization methods have shown improved performance, they face challenges due to their reliance on prior information about the number of objects to be separated. In this paper, to overcome this limitation, we present a novel multi-sound source localization method that can perform localization without prior knowledge of the number of sound sources. To achieve this goal, we propose an iterative object identification (IOI) module, which can recognize sound-making objects in an iterative manner. After finding the regions of sound-making objects, we devise object similarity-aware clustering (OSC) loss to guide the IOI module to effectively combine regions of the same object but also distinguish between different objects and backgrounds. It enables our method to perform accurate localization of sound-making objects without any prior knowledge. Extensive experimental results on the MUSIC and VGGSound benchmarks show the significant performance improvements of the proposed method over the existing methods for both single and multi-source. Our code is available at: https://github.com/VisualAIKHU/NoPrior_MultiSSL