 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkBrake: Mitigating Overthinking in Tool Reasoning
Oct 01, 2025Small reasoning models (SRMs) often overthink during tool use: they reach a correct tool-argument configuration, then continue reasoning and overwrite it with an incorrect final call. We diagnose overthinking via oracle rollouts that inject </think> at sentence boundaries. On the Berkeley Function Calling Leaderboard (BFCL), this oracle termination lifts average accuracy from 85.8\% to 94.2\% while reducing tokens by 80-94\%, revealing substantial recoverable headroom and potential redundant reasoning. While prior work on concise reasoning has largely targeted mathematics, tool reasoning remains underexplored. We adapt various early-termination baselines to tool use and introduce ThinkBrake, a training-free decoding heuristic. ThinkBrake monitors the log-probability margin between </think> and the current top token at sentence boundaries and triggers termination when this margin becomes small. Across BFCL's single turn, non-live and live splits, ThinkBrake preserves or improves accuracy while reducing tokens up to 25\%, outperforming various baselines.
Toward Architecture-Agnostic Local Control of Posterior Collapse in VAEs
Aug 17, 2025Variational autoencoders (VAEs), one of the most widely used generative models, are known to suffer from posterior collapse, a phenomenon that reduces the diversity of generated samples. To avoid posterior collapse, many prior works have tried to control the influence of regularization loss. However, the trade-off between reconstruction and regularization is not satisfactory. For this reason, several methods have been proposed to guarantee latent identifiability, which is the key to avoiding posterior collapse. However, they require structural constraints on the network architecture. For further clarification, we define local posterior collapse to reflect the importance of individual sample points in the data space and to relax the network constraint. Then, we propose Latent Reconstruction(LR) loss, which is inspired by mathematical properties of injective and composite functions, to control posterior collapse without restriction to a specific architecture. We experimentally evaluate our approach, which controls posterior collapse on varied datasets such as MNIST, fashionMNIST, Omniglot, CelebA, and FFHQ.
Adversarial Wear and Tear: Exploiting Natural Damage for Generating Physical-World Adversarial Examples
Mar 27, 2025



The presence of adversarial examples in the physical world poses significant challenges to the deployment of Deep Neural Networks in safety-critical applications such as autonomous driving. Most existing methods for crafting physical-world adversarial examples are ad-hoc, relying on temporary modifications like shadows, laser beams, or stickers that are tailored to specific scenarios. In this paper, we introduce a new class of physical-world adversarial examples, AdvWT, which draws inspiration from the naturally occurring phenomenon of `wear and tear', an inherent property of physical objects. Unlike manually crafted perturbations, `wear and tear' emerges organically over time due to environmental degradation, as seen in the gradual deterioration of outdoor signboards. To achieve this, AdvWT follows a two-step approach. First, a GAN-based, unsupervised image-to-image translation network is employed to model these naturally occurring damages, particularly in the context of outdoor signboards. The translation network encodes the characteristics of damaged signs into a latent `damage style code'. In the second step, we introduce adversarial perturbations into the style code, strategically optimizing its transformation process. This manipulation subtly alters the damage style representation, guiding the network to generate adversarial images where the appearance of damages remains perceptually realistic, while simultaneously ensuring their effectiveness in misleading neural networks. Through comprehensive experiments on two traffic sign datasets, we show that AdvWT effectively misleads DNNs in both digital and physical domains. AdvWT achieves an effective attack success rate, greater robustness, and a more natural appearance compared to existing physical-world adversarial examples. Additionally, integrating AdvWT into training enhances a model's generalizability to real-world damaged signs.
Neural Clustering for Prefractured Mesh Generation in Real-time Object Destruction
Feb 07, 2025
Prefracture method is a practical implementation for real-time object destruction that is hardly achievable within performance constraints, but can produce unrealistic results due to its heuristic nature. To mitigate it, we approach the clustering of prefractured mesh generation as an unordered segmentation on point cloud data, and propose leveraging the deep neural network trained on a physics-based dataset. Our novel paradigm successfully predicts the structural weakness of object that have been limited, exhibiting ready-to-use results with remarkable quality.
Beta-Sigma VAE: Separating beta and decoder variance in Gaussian variational autoencoder
Sep 14, 2024



Variational autoencoder (VAE) is an established generative model but is notorious for its blurriness. In this work, we investigate the blurry output problem of VAE and resolve it, exploiting the variance of Gaussian decoder and $\beta$ of beta-VAE. Specifically, we reveal that the indistinguishability of decoder variance and $\beta$ hinders appropriate analysis of the model by random likelihood value, and limits performance improvement by omitting the gain from $\beta$. To address the problem, we propose Beta-Sigma VAE (BS-VAE) that explicitly separates $\beta$ and decoder variance $\sigma^2_x$ in the model. Our method demonstrates not only superior performance in natural image synthesis but also controllable parameters and predictable analysis compared to conventional VAE. In our experimental evaluation, we employ the analysis of rate-distortion curve and proxy metrics on computer vision datasets. The code is available on https://github.com/overnap/BS-VAE
Neural Radiance Fields for Transparent Object Using Visual Hull
Dec 13, 2023


Unlike opaque object, novel view synthesis of transparent object is a challenging task, because transparent object refracts light of background causing visual distortions on the transparent object surface along the viewpoint change. Recently introduced Neural Radiance Fields (NeRF) is a view synthesis method. Thanks to its remarkable performance improvement, lots of following applications based on NeRF in various topics have been developed. However, if an object with a different refractive index is included in a scene such as transparent object, NeRF shows limited performance because refracted light ray at the surface of the transparent object is not appropriately considered. To resolve the problem, we propose a NeRF-based method consisting of the following three steps: First, we reconstruct a three-dimensional shape of a transparent object using visual hull. Second, we simulate the refraction of the rays inside of the transparent object according to Snell's law. Last, we sample points through refracted rays and put them into NeRF. Experimental evaluation results demonstrate that our method addresses the limitation of conventional NeRF with transparent objects.
Single Image Reflection Removal with Reflection Intensity Prior Knowledge
Dec 06, 2023Single Image Reflection Removal (SIRR) in real-world images is a challenging task due to diverse image degradations occurring on the glass surface during light transmission and reflection. Many existing methods rely on specific prior assumptions to resolve the problem. In this paper, we propose a general reflection intensity prior that captures the intensity of the reflection phenomenon and demonstrate its effectiveness. To learn the reflection intensity prior, we introduce the Reflection Prior Extraction Network (RPEN). By segmenting images into regional patches, RPEN learns non-uniform reflection prior in an image. We propose Prior-based Reflection Removal Network (PRRN) using a simple transformer U-Net architecture that adapts reflection prior fed from RPEN. Experimental results on real-world benchmarks demonstrate the effectiveness of our approach achieving state-of-the-art accuracy in SIRR.
Internal-External Boundary Attention Fusion for Glass Surface Segmentation
Jul 01, 2023Glass surfaces of transparent objects and mirrors are not able to be uniquely and explicitly characterized by their visual appearances because they contain the visual appearance of other reflected or transmitted surfaces as well. Detecting glass regions from a single-color image is a challenging task. Recent deep-learning approaches have paid attention to the description of glass surface boundary where the transition of visual appearances between glass and non-glass surfaces are observed. In this work, we analytically investigate how glass surface boundary helps to characterize glass objects. Inspired by prior semantic segmentation approaches with challenging image types such as X-ray or CT scans, we propose separated internal-external boundary attention modules that individually learn and selectively integrate visual characteristics of the inside and outside region of glass surface from a single color image. Our proposed method is evaluated on six public benchmarks comparing with state-of-the-art methods showing promising results.
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
Jul 01, 2023



Segment Anything Model (SAM) has attracted significant attention due to its impressive zero-shot transfer performance and high versatility for numerous vision applications (like image editing with fine-grained control). Many of such applications need to be run on resource-constraint edge devices, like mobile phones. In this work, we aim to make SAM mobile-friendly by replacing the heavyweight image encoder with a lightweight one. A naive way to train such a new SAM as in the original SAM paper leads to unsatisfactory performance, especially when limited training sources are available. We find that this is mainly caused by the coupled optimization of the image encoder and mask decoder, motivated by which we propose decoupled distillation. Concretely, we distill the knowledge from the heavy image encoder (ViT-H in the original SAM) to a lightweight image encoder, which can be automatically compatible with the mask decoder in the original SAM. The training can be completed on a single GPU within less than one day, and the resulting lightweight SAM is termed MobileSAM which is more than 60 times smaller yet performs on par with the original SAM. For inference speed, With a single GPU, MobileSAM runs around 10ms per image: 8ms on the image encoder and 4ms on the mask decoder. With superior performance, our MobileSAM is around 5 times faster than the concurrent FastSAM and 7 times smaller, making it more suitable for mobile applications. Moreover, we show that MobileSAM can run relatively smoothly on CPU. The code for our project is provided at \href{https://github.com/ChaoningZhang/MobileSAM}{\textcolor{red}{MobileSAM}}), with a demo showing that MobileSAM can run relatively smoothly on CPU.
Continual Learning with Neuron Activation Importance
Jul 27, 2021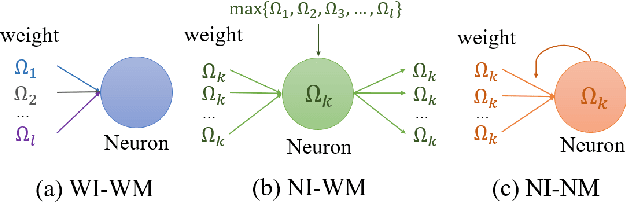
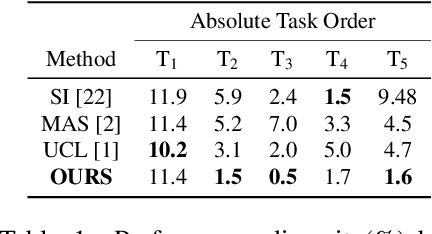
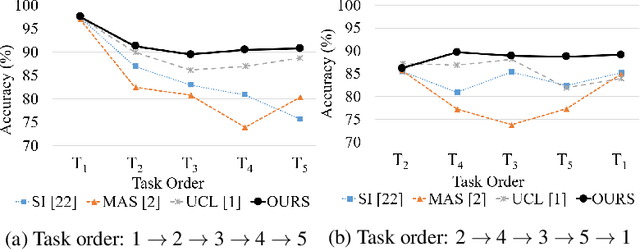
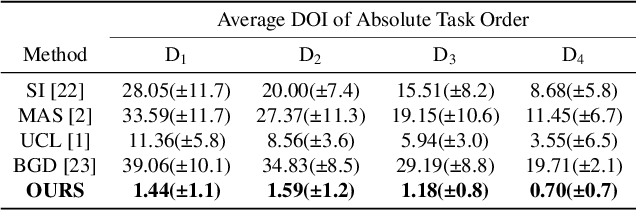
Continual learning is a concept of online learning with multiple sequential tasks. One of the critical barriers of continual learning is that a network should learn a new task keeping the knowledge of old tasks without access to any data of the old tasks. In this paper, we propose a neuron activation importance-based regularization method for stable continual learning regardless of the order of tasks. We conduct comprehensive experiments on existing benchmark data sets to evaluate not just the stability and plasticity of our method with improved classification accuracy also the robustness of the performance along the changes of task order.