 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Eyes Betray AI: Social Gaze Consistency as a Semantic Cue for AI-Generated Image Detection
May 27, 2026Recent generative models have largely closed the gap on low-level artifacts - pixel fingerprints, frequency anomalies, upsampling traces - particularly in person-centric and partial-edit settings where the manipulated region is small and surrounded by photometrically authentic content. We introduce Social Gaze Consistency, a high-level semantic cue defined as the mutual coherence of gaze direction, head-eye alignment, and pupil placement between interacting individuals, and show that it constitutes a previously underutilized detection axis orthogonal to existing low-level paradigms. We instantiate this insight through three coupled mechanisms: (i) a controlled diagnostic dataset with region-specific perturbations of gaze-consistent imagery, where strict pair-level grouping forecloses generator-fingerprint memorization as an optimization-time shortcut rather than relying on augmentation; (ii) Block-Compositional Caption Supervision, which holds a single 5-block reasoning skeleton invariant across 1,250 macro-combined captions, decoupling reasoning consistency from surface diversity; (iii) Cross-architecture validation showing the same supervision improves a vision-language backbone (FakeVLM) by +3.7 pp on the COCOAI Interaction subset (balanced accuracy 67.8 -> 71.5) and +1.3 pp on the COCOAI Person subset (83.0 -> 84.3), with consistent gains on a vision-only backbone (Effort), evidencing a backbone-agnostic cue. Real- and fake-class recalls rise simultaneously, ruling out a "predict-all-fake" artifact. A four-step mechanistic account - paired-edit shortcut blocking, hard-to-easy difficulty transfer, CLIP prior preservation, and diffusion-family shared spectral weakness in periocular structure - explains why training on a single inpainter (FLUX.1-Fill) transfers to multi-generator suites. We will release the code upon acceptance to facilitate reproducibility.
Design of Orthogonal Phase of Arrival Positioning Scheme Based on 5G PRS and Optimization of TOA Performance
Oct 30, 2025This study analyzes the performance of positioning techniques based on configuration changes of 5G New Radio signals. In 5G networks, a terminal position is determined from the Time of Arrival of Positioning Reference Signals transmitted by base stations. We propose an algorithm that improves TOA accuracy under low sampling rate constraints and implement 5G PRS for positioning in a software defined modem. We also examine how flexible time frequency resource allocation of PRS affects TOA estimation accuracy and discuss optimal PRS configurations for a given signal environment.
Multi-Task Multi-Fidelity Learning of Properties for Energetic Materials
Aug 21, 2024
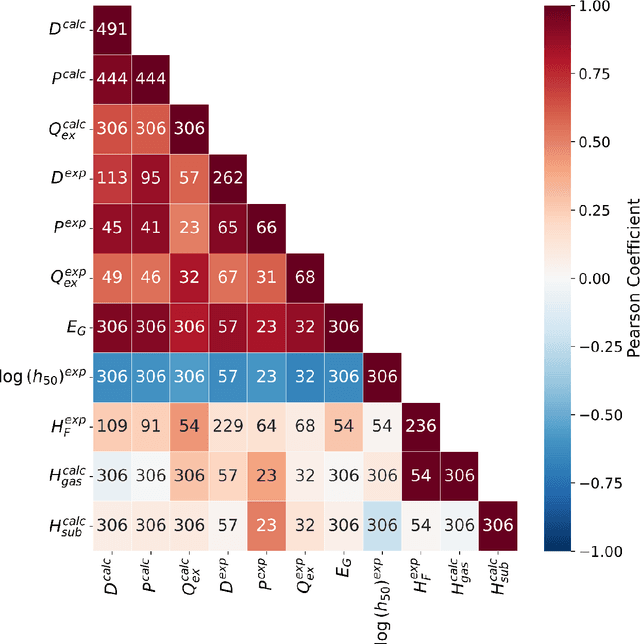
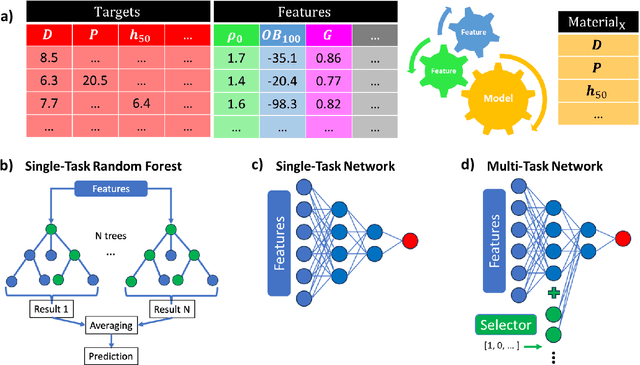
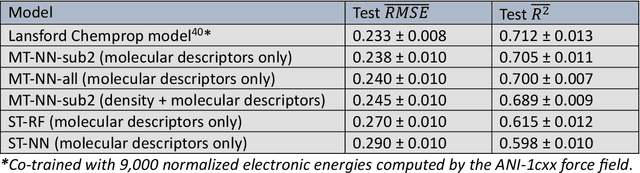
Data science and artificial intelligence are playing an increasingly important role in the physical sciences. Unfortunately, in the field of energetic materials data scarcity limits the accuracy and even applicability of ML tools. To address data limitations, we compiled multi-modal data: both experimental and computational results for several properties. We find that multi-task neural networks can learn from multi-modal data and outperform single-task models trained for specific properties. As expected, the improvement is more significant for data-scarce properties. These models are trained using descriptors built from simple molecular information and can be readily applied for large-scale materials screening to explore multiple properties simultaneously. This approach is widely applicable to fields outside energetic materials.
AAPL: Adding Attributes to Prompt Learning for Vision-Language Models
Apr 25, 2024



Recent advances in large pre-trained vision-language models have demonstrated remarkable performance on zero-shot downstream tasks. Building upon this, recent studies, such as CoOp and CoCoOp, have proposed the use of prompt learning, where context within a prompt is replaced with learnable vectors, leading to significant improvements over manually crafted prompts. However, the performance improvement for unseen classes is still marginal, and to tackle this problem, data augmentation has been frequently used in traditional zero-shot learning techniques. Through our experiments, we have identified important issues in CoOp and CoCoOp: the context learned through traditional image augmentation is biased toward seen classes, negatively impacting generalization to unseen classes. To address this problem, we propose adversarial token embedding to disentangle low-level visual augmentation features from high-level class information when inducing bias in learnable prompts. Through our novel mechanism called "Adding Attributes to Prompt Learning", AAPL, we guide the learnable context to effectively extract text features by focusing on high-level features for unseen classes. We have conducted experiments across 11 datasets, and overall, AAPL shows favorable performances compared to the existing methods in few-shot learning, zero-shot learning, cross-dataset, and domain generalization tasks.
Continual Learning with Neuron Activation Importance
Jul 27, 2021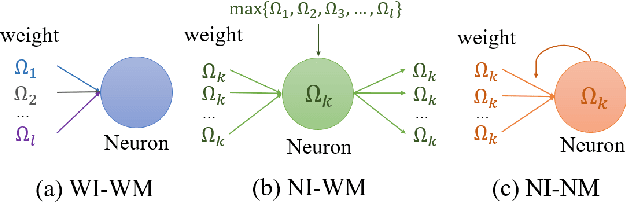
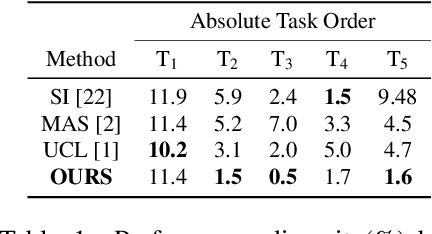
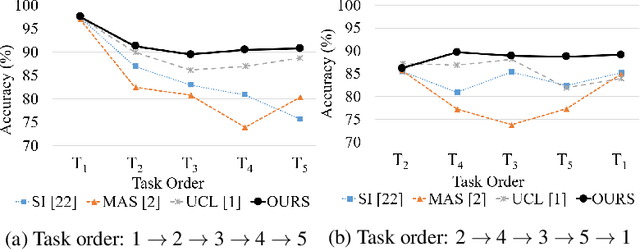
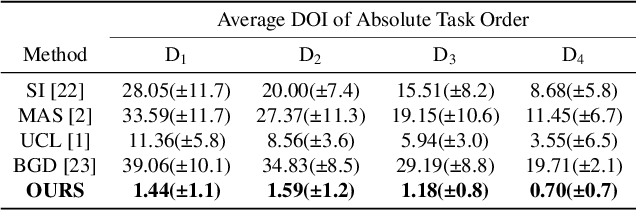
Continual learning is a concept of online learning with multiple sequential tasks. One of the critical barriers of continual learning is that a network should learn a new task keeping the knowledge of old tasks without access to any data of the old tasks. In this paper, we propose a neuron activation importance-based regularization method for stable continual learning regardless of the order of tasks. We conduct comprehensive experiments on existing benchmark data sets to evaluate not just the stability and plasticity of our method with improved classification accuracy also the robustness of the performance along the changes of task order.