 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere It Moves, It Matters: Referring Surgical Instrument Segmentation via Motion
Jan 18, 2026Enabling intuitive, language-driven interaction with surgical scenes is a critical step toward intelligent operating rooms and autonomous surgical robotic assistance. However, the task of referring segmentation, localizing surgical instruments based on natural language descriptions, remains underexplored in surgical videos, with existing approaches struggling to generalize due to reliance on static visual cues and predefined instrument names. In this work, we introduce SurgRef, a novel motion-guided framework that grounds free-form language expressions in instrument motion, capturing how tools move and interact across time, rather than what they look like. This allows models to understand and segment instruments even under occlusion, ambiguity, or unfamiliar terminology. To train and evaluate SurgRef, we present Ref-IMotion, a diverse, multi-institutional video dataset with dense spatiotemporal masks and rich motion-centric expressions. SurgRef achieves state-of-the-art accuracy and generalization across surgical procedures, setting a new benchmark for robust, language-driven surgical video segmentation.
Adversarial Wear and Tear: Exploiting Natural Damage for Generating Physical-World Adversarial Examples
Mar 27, 2025



The presence of adversarial examples in the physical world poses significant challenges to the deployment of Deep Neural Networks in safety-critical applications such as autonomous driving. Most existing methods for crafting physical-world adversarial examples are ad-hoc, relying on temporary modifications like shadows, laser beams, or stickers that are tailored to specific scenarios. In this paper, we introduce a new class of physical-world adversarial examples, AdvWT, which draws inspiration from the naturally occurring phenomenon of `wear and tear', an inherent property of physical objects. Unlike manually crafted perturbations, `wear and tear' emerges organically over time due to environmental degradation, as seen in the gradual deterioration of outdoor signboards. To achieve this, AdvWT follows a two-step approach. First, a GAN-based, unsupervised image-to-image translation network is employed to model these naturally occurring damages, particularly in the context of outdoor signboards. The translation network encodes the characteristics of damaged signs into a latent `damage style code'. In the second step, we introduce adversarial perturbations into the style code, strategically optimizing its transformation process. This manipulation subtly alters the damage style representation, guiding the network to generate adversarial images where the appearance of damages remains perceptually realistic, while simultaneously ensuring their effectiveness in misleading neural networks. Through comprehensive experiments on two traffic sign datasets, we show that AdvWT effectively misleads DNNs in both digital and physical domains. AdvWT achieves an effective attack success rate, greater robustness, and a more natural appearance compared to existing physical-world adversarial examples. Additionally, integrating AdvWT into training enhances a model's generalizability to real-world damaged signs.
Learning Trimodal Relation for Audio-Visual Question Answering with Missing Modality
Jul 23, 2024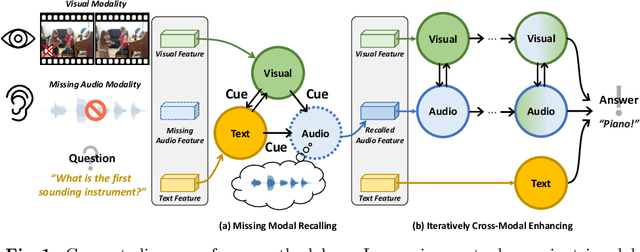
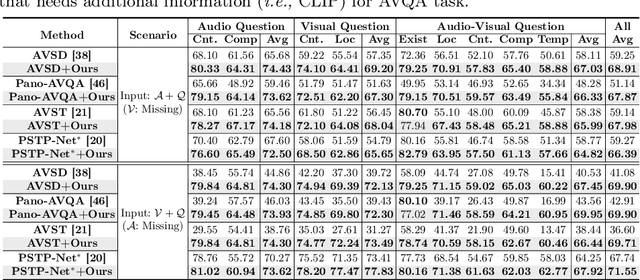
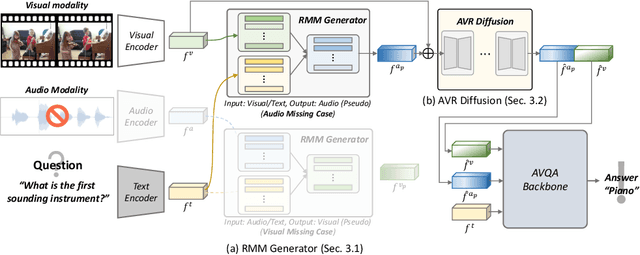
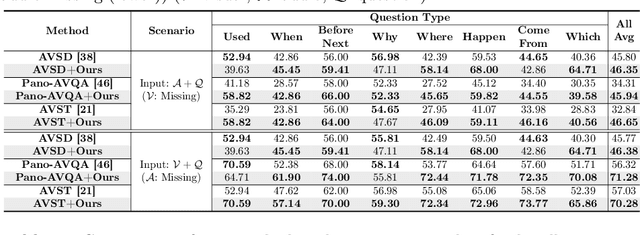
Recent Audio-Visual Question Answering (AVQA) methods rely on complete visual and audio input to answer questions accurately. However, in real-world scenarios, issues such as device malfunctions and data transmission errors frequently result in missing audio or visual modality. In such cases, existing AVQA methods suffer significant performance degradation. In this paper, we propose a framework that ensures robust AVQA performance even when a modality is missing. First, we propose a Relation-aware Missing Modal (RMM) generator with Relation-aware Missing Modal Recalling (RMMR) loss to enhance the ability of the generator to recall missing modal information by understanding the relationships and context among the available modalities. Second, we design an Audio-Visual Relation-aware (AVR) diffusion model with Audio-Visual Enhancing (AVE) loss to further enhance audio-visual features by leveraging the relationships and shared cues between the audio-visual modalities. As a result, our method can provide accurate answers by effectively utilizing available information even when input modalities are missing. We believe our method holds potential applications not only in AVQA research but also in various multi-modal scenarios.
Robust Proxy: Improving Adversarial Robustness by Robust Proxy Learning
Jun 27, 2023Recently, it has been widely known that deep neural networks are highly vulnerable and easily broken by adversarial attacks. To mitigate the adversarial vulnerability, many defense algorithms have been proposed. Recently, to improve adversarial robustness, many works try to enhance feature representation by imposing more direct supervision on the discriminative feature. However, existing approaches lack an understanding of learning adversarially robust feature representation. In this paper, we propose a novel training framework called Robust Proxy Learning. In the proposed method, the model explicitly learns robust feature representations with robust proxies. To this end, firstly, we demonstrate that we can generate class-representative robust features by adding class-wise robust perturbations. Then, we use the class representative features as robust proxies. With the class-wise robust features, the model explicitly learns adversarially robust features through the proposed robust proxy learning framework. Through extensive experiments, we verify that we can manually generate robust features, and our proposed learning framework could increase the robustness of the DNNs.
Advancing Adversarial Training by Injecting Booster Signal
Jun 27, 2023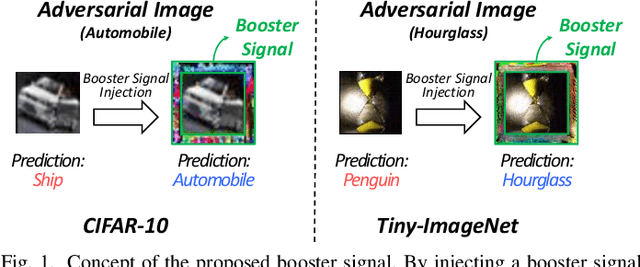
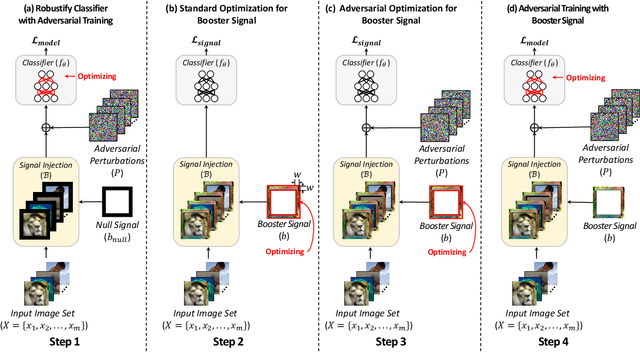
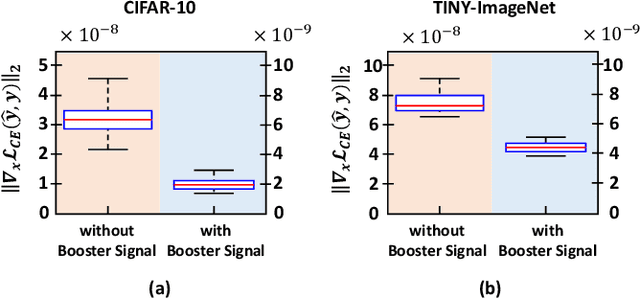
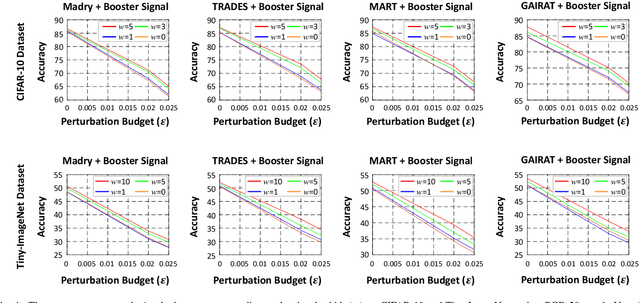
Recent works have demonstrated that deep neural networks (DNNs) are highly vulnerable to adversarial attacks. To defend against adversarial attacks, many defense strategies have been proposed, among which adversarial training has been demonstrated to be the most effective strategy. However, it has been known that adversarial training sometimes hurts natural accuracy. Then, many works focus on optimizing model parameters to handle the problem. Different from the previous approaches, in this paper, we propose a new approach to improve the adversarial robustness by using an external signal rather than model parameters. In the proposed method, a well-optimized universal external signal called a booster signal is injected into the outside of the image which does not overlap with the original content. Then, it boosts both adversarial robustness and natural accuracy. The booster signal is optimized in parallel to model parameters step by step collaboratively. Experimental results show that the booster signal can improve both the natural and robust accuracies over the recent state-of-the-art adversarial training methods. Also, optimizing the booster signal is general and flexible enough to be adopted on any existing adversarial training methods.
Defending Against Person Hiding Adversarial Patch Attack with a Universal White Frame
Apr 27, 2022

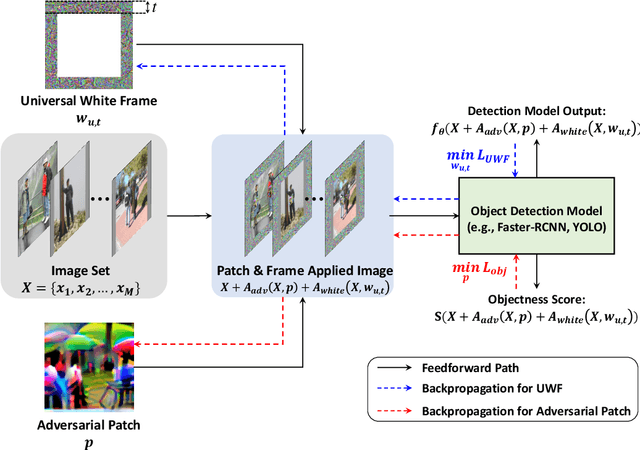
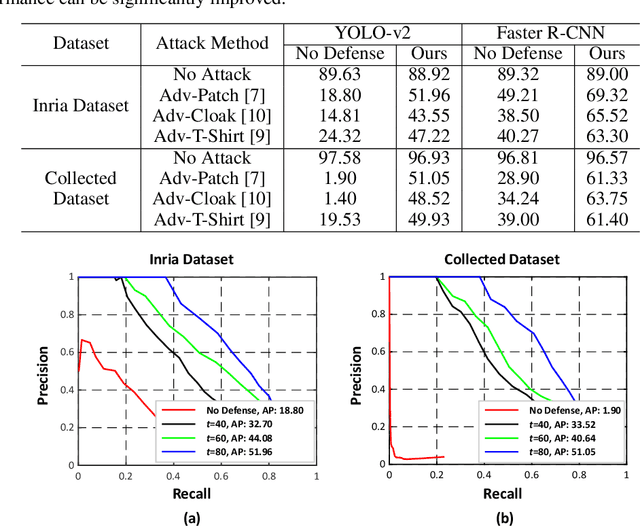
Object detection has attracted great attention in the computer vision area and has emerged as an indispensable component in many vision systems. In the era of deep learning, many high-performance object detection networks have been proposed. Although these detection networks show high performance, they are vulnerable to adversarial patch attacks. Changing the pixels in a restricted region can easily fool the detection network in the physical world. In particular, person-hiding attacks are emerging as a serious problem in many safety-critical applications such as autonomous driving and surveillance systems. Although it is necessary to defend against an adversarial patch attack, very few efforts have been dedicated to defending against person-hiding attacks. To tackle the problem, in this paper, we propose a novel defense strategy that mitigates a person-hiding attack by optimizing defense patterns, while previous methods optimize the model. In the proposed method, a frame-shaped pattern called a 'universal white frame' (UWF) is optimized and placed on the outside of the image. To defend against adversarial patch attacks, UWF should have three properties (i) suppressing the effect of the adversarial patch, (ii) maintaining its original prediction, and (iii) applicable regardless of images. To satisfy the aforementioned properties, we propose a novel pattern optimization algorithm that can defend against the adversarial patch. Through comprehensive experiments, we demonstrate that the proposed method effectively defends against the adversarial patch attack.
Efficient Ensemble Model Generation for Uncertainty Estimation with Bayesian Approximation in Segmentation
May 22, 2020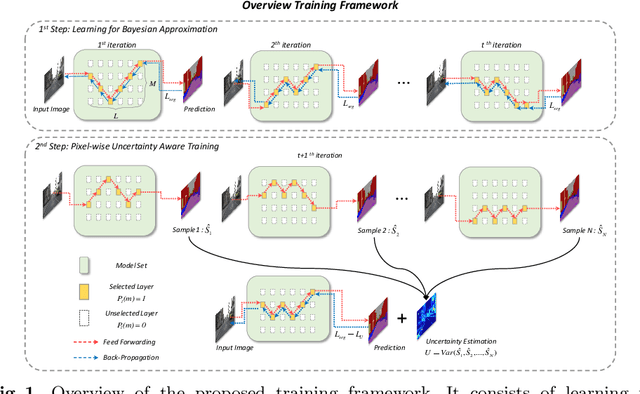
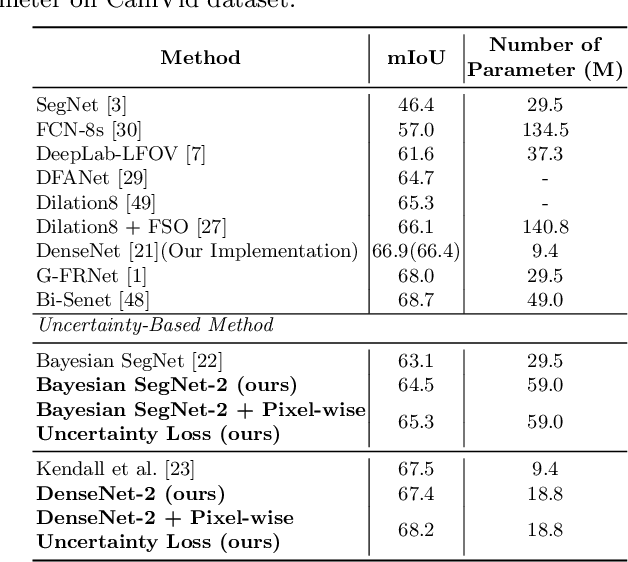
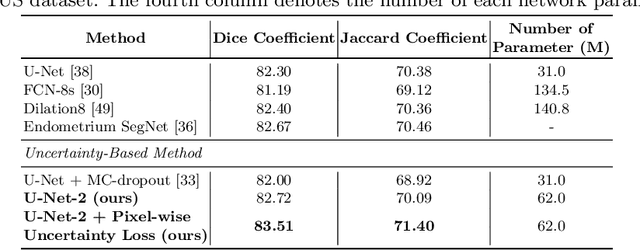
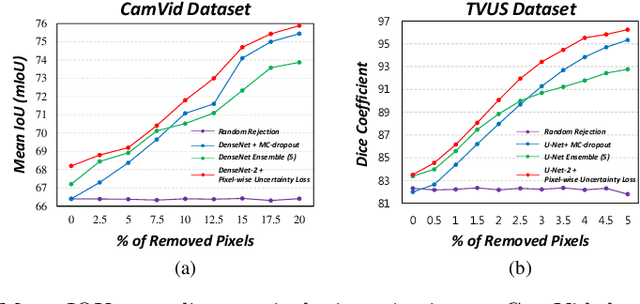
Recent studies have shown that ensemble approaches could not only improve accuracy and but also estimate model uncertainty in deep learning. However, it requires a large number of parameters according to the increase of ensemble models for better prediction and uncertainty estimation. To address this issue, a generic and efficient segmentation framework to construct ensemble segmentation models is devised in this paper. In the proposed method, ensemble models can be efficiently generated by using the stochastic layer selection method. The ensemble models are trained to estimate uncertainty through Bayesian approximation. Moreover, to overcome its limitation from uncertain instances, we devise a new pixel-wise uncertainty loss, which improves the predictive performance. To evaluate our method, comprehensive and comparative experiments have been conducted on two datasets. Experimental results show that the proposed method could provide useful uncertainty information by Bayesian approximation with the efficient ensemble model generation and improve the predictive performance.
Investigating Vulnerability to Adversarial Examples on Multimodal Data Fusion in Deep Learning
May 22, 2020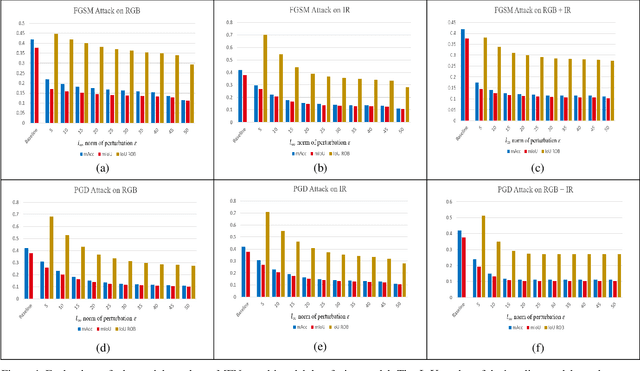
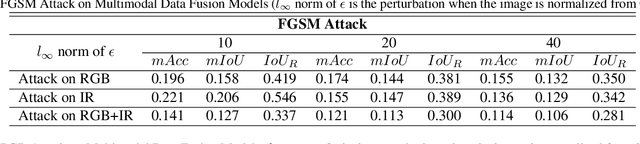

The success of multimodal data fusion in deep learning appears to be attributed to the use of complementary in-formation between multiple input data. Compared to their predictive performance, relatively less attention has been devoted to the robustness of multimodal fusion models. In this paper, we investigated whether the current multimodal fusion model utilizes the complementary intelligence to defend against adversarial attacks. We applied gradient based white-box attacks such as FGSM and PGD on MFNet, which is a major multispectral (RGB, Thermal) fusion deep learning model for semantic segmentation. We verified that the multimodal fusion model optimized for better prediction is still vulnerable to adversarial attack, even if only one of the sensors is attacked. Thus, it is hard to say that existing multimodal data fusion models are fully utilizing complementary relationships between multiple modalities in terms of adversarial robustness. We believe that our observations open a new horizon for adversarial attack research on multimodal data fusion.
Robust Ensemble Model Training via Random Layer Sampling Against Adversarial Attack
May 21, 2020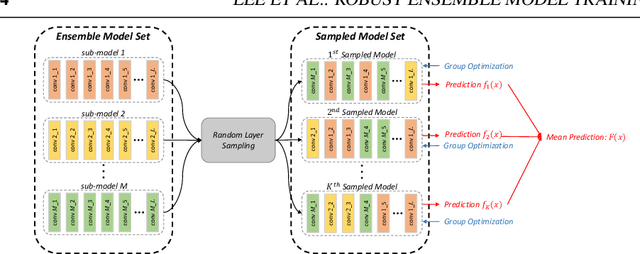
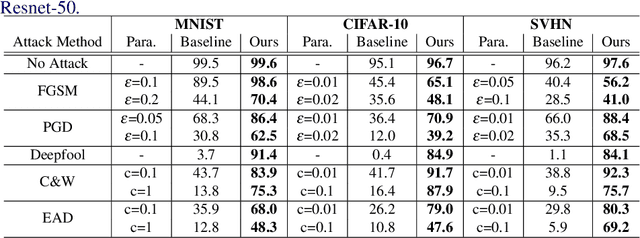
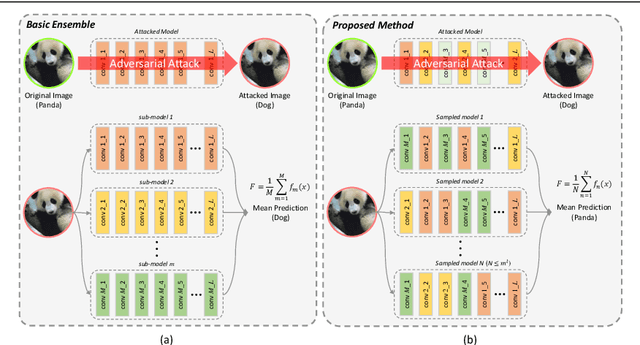
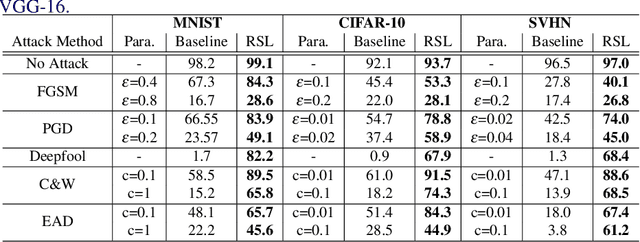
Deep neural networks have achieved substantial achievements in several computer vision areas, but have vulnerabilities that are often fooled by adversarial examples that are not recognized by humans. This is an important issue for security or medical applications. In this paper, we propose an ensemble model training framework with random layer sampling to improve the robustness of deep neural networks. In the proposed training framework, we generate various sampled model through the random layer sampling and update the weight of the sampled model. After the ensemble models are trained, it can hide the gradient efficiently and avoid the gradient-based attack by the random layer sampling method. To evaluate our proposed method, comprehensive and comparative experiments have been conducted on three datasets. Experimental results show that the proposed method improves the adversarial robustness.