 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Similarity to Structure: Training-free LLM Context Compression with Hybrid Graph Priors
Apr 25, 2026Long-context large language models remain computationally expensive to run and often fail to reliably process very long inputs, which makes context compression an important component of many systems. Existing compression approaches typically rely on trained compressors, dense retrieval-style selection, or heuristic trimming, and they often struggle to jointly preserve task relevance, topic coverage, and cross-sentence coherence under a strict token budget. To address this, we propose a training-free and model-agnostic compression framework that selects a compact set of sentences guided by structural graph priors. Our method constructs a sparse hybrid sentence graph that combines mutual k-NN semantic edges with short-range sequential edges, extracts a topic skeleton via clustering, and ranks sentences using an interpretable score that integrates task relevance, cluster representativeness, bridge centrality, and a cycle coverage cue. A budgeted greedy selection with redundancy suppression then produces a readable compressed context in original order. Experimental results on four datasets show that our approach is competitive with strong extractive and abstractive baselines, demonstrating larger gains on long-document benchmarks.
DASH-KV: Accelerating Long-Context LLM Inference via Asymmetric KV Cache Hashing
Apr 22, 2026The quadratic computational complexity of the standard attention mechanism constitutes a fundamental bottleneck for large language models in long-context inference. While existing KV cache compression methods alleviate memory pressure, they often sacrifice generation quality and fail to address the high overhead of floating-point arithmetic. This paper introduces DASH-KV, an innovative acceleration framework that reformulates attention as approximate nearest-neighbor search via asymmetric deep hashing. Under this paradigm, we design an asymmetric encoding architecture that differentially maps queries and keys to account for their distinctions in precision and reuse characteristics. To balance efficiency and accuracy, we further introduce a dynamic mixed-precision mechanism that adaptively retains full-precision computation for critical tokens. Extensive experiments on LongBench demonstrate that DASH-KV significantly outperforms state-of-the-art baseline methods while matching the performance of full attention, all while reducing inference complexity from O(N^2) to linear O(N). The code is available at https://github.com/Zhihan-Zh/DASH-KV
Lightweight LLM Agent Memory with Small Language Models
Apr 09, 2026Although LLM agents can leverage tools for complex tasks, they still need memory to maintain cross-turn consistency and accumulate reusable information in long-horizon interactions. However, retrieval-based external memory systems incur low online overhead but suffer from unstable accuracy due to limited query construction and candidate filtering. In contrast, many systems use repeated large-model calls for online memory operations, improving accuracy but accumulating latency over long interactions. We propose LightMem, a lightweight memory system for better agent memory driven by Small Language Models (SLMs). LightMem modularizes memory retrieval, writing, and long-term consolidation, and separates online processing from offline consolidation to enable efficient memory invocation under bounded compute. We organize memory into short-term memory (STM) for immediate conversational context, mid-term memory (MTM) for reusable interaction summaries, and long-term memory (LTM) for consolidated knowledge, and uses user identifiers to support independent retrieval and incremental maintenance in multi-user settings. Online, LightMem operates under a fixed retrieval budget and selects memories via a two-stage procedure: vector-based coarse retrieval followed by semantic consistency re-ranking. Offline, it abstracts reusable interaction evidence and incrementally integrates it into LTM. Experiments show gains across model scales, with an average F1 improvement of about 2.5 on LoCoMo, more effective and low median latency (83 ms retrieval; 581 ms end-to-end).
Experience Transfer for Multimodal LLM Agents in Minecraft Game
Apr 07, 2026Multimodal LLM agents operating in complex game environments must continually reuse past experience to solve new tasks efficiently. In this work, we propose Echo, a transfer-oriented memory framework that enables agents to derive actionable knowledge from prior interactions rather than treating memory as a passive repository of static records. To make transfer explicit, Echo decomposes reusable knowledge into five dimensions: structure, attribute, process, function, and interaction. This formulation allows the agent to identify recurring patterns shared across different tasks and infer what prior experience remains applicable in new situations. Building on this formulation, Echo leverages In-Context Analogy Learning (ICAL) to retrieve relevant experiences and adapt them to unseen tasks through contextual examples. Experiments in Minecraft show that, under a from-scratch learning setting, Echo achieves a 1.3x to 1.7x speed-up on object-unlocking tasks. Moreover, Echo exhibits a burst-like chain-unlocking phenomenon, rapidly unlocking multiple similar items within a short time interval after acquiring transferable experience. These results suggest that experience transfer is a promising direction for improving the efficiency and adaptability of multimodal LLM agents in complex interactive environments.
Efficient and Interpretable Multi-Agent LLM Routing via Ant Colony Optimization
Mar 13, 2026Large Language Model (LLM)-driven Multi-Agent Systems (MAS) have demonstrated strong capability in complex reasoning and tool use, and heterogeneous agent pools further broaden the quality--cost trade-off space. Despite these advances, real-world deployment is often constrained by high inference cost, latency, and limited transparency, which hinders scalable and efficient routing. Existing routing strategies typically rely on expensive LLM-based selectors or static policies, and offer limited controllability for semantic-aware routing under dynamic loads and mixed intents, often resulting in unstable performance and inefficient resource utilization. To address these limitations, we propose AMRO-S, an efficient and interpretable routing framework for Multi-Agent Systems (MAS). AMRO-S models MAS routing as a semantic-conditioned path selection problem, enhancing routing performance through three key mechanisms: First, it leverages a supervised fine-tuned (SFT) small language model for intent inference, providing a low-overhead semantic interface for each query; second, it decomposes routing memory into task-specific pheromone specialists, reducing cross-task interference and optimizing path selection under mixed workloads; finally, it employs a quality-gated asynchronous update mechanism to decouple inference from learning, optimizing routing without increasing latency. Extensive experiments on five public benchmarks and high-concurrency stress tests demonstrate that AMRO-S consistently improves the quality--cost trade-off over strong routing baselines, while providing traceable routing evidence through structured pheromone patterns.
Text summarization via global structure awareness
Feb 11, 2026Text summarization is a fundamental task in natural language processing (NLP), and the information explosion has made long-document processing increasingly demanding, making summarization essential. Existing research mainly focuses on model improvements and sentence-level pruning, but often overlooks global structure, leading to disrupted coherence and weakened downstream performance. Some studies employ large language models (LLMs), which achieve higher accuracy but incur substantial resource and time costs. To address these issues, we introduce GloSA-sum, the first summarization approach that achieves global structure awareness via topological data analysis (TDA). GloSA-sum summarizes text efficiently while preserving semantic cores and logical dependencies. Specifically, we construct a semantic-weighted graph from sentence embeddings, where persistent homology identifies core semantics and logical structures, preserved in a ``protection pool'' as the backbone for summarization. We design a topology-guided iterative strategy, where lightweight proxy metrics approximate sentence importance to avoid repeated high-cost computations, thus preserving structural integrity while improving efficiency. To further enhance long-text processing, we propose a hierarchical strategy that integrates segment-level and global summarization. Experiments on multiple datasets demonstrate that GloSA-sum reduces redundancy while preserving semantic and logical integrity, striking a balance between accuracy and efficiency, and further benefits LLM downstream tasks by shortening contexts while retaining essential reasoning chains.
Understanding Chain-of-Thought in Large Language Models via Topological Data Analysis
Dec 22, 2025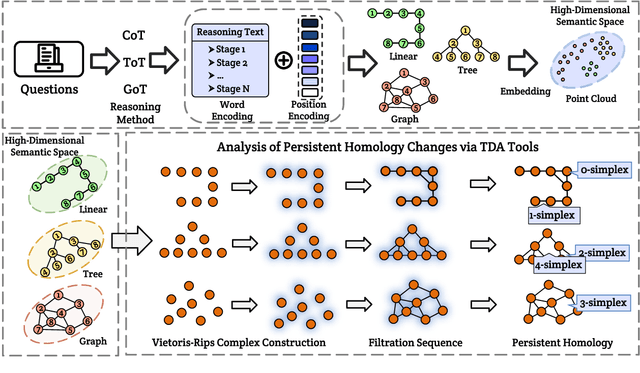
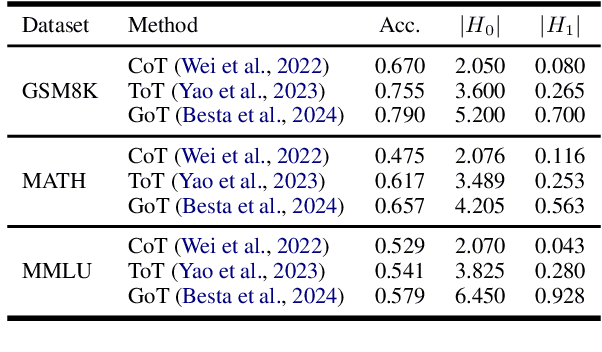
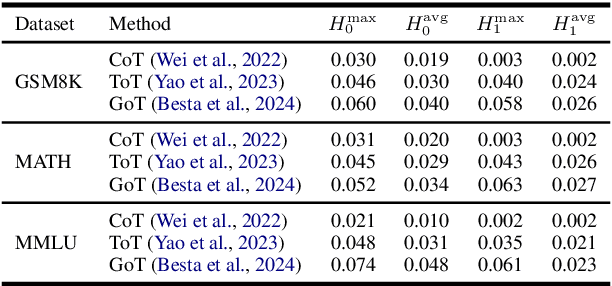
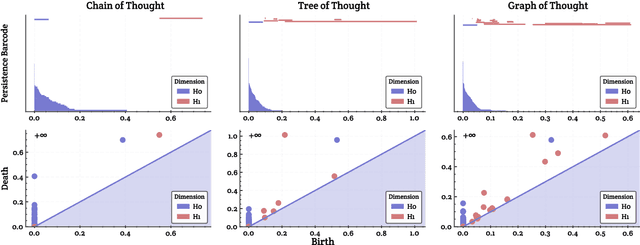
With the development of large language models (LLMs), particularly with the introduction of the long reasoning chain technique, the reasoning ability of LLMs in complex problem-solving has been significantly enhanced. While acknowledging the power of long reasoning chains, we cannot help but wonder: Why do different reasoning chains perform differently in reasoning? What components of the reasoning chains play a key role? Existing studies mainly focus on evaluating reasoning chains from a functional perspective, with little attention paid to their structural mechanisms. To address this gap, this work is the first to analyze and evaluate the quality of the reasoning chain from a structural perspective. We apply persistent homology from Topological Data Analysis (TDA) to map reasoning steps into semantic space, extract topological features, and analyze structural changes. These changes reveal semantic coherence, logical redundancy, and identify logical breaks and gaps. By calculating homology groups, we assess connectivity and redundancy at various scales, using barcode and persistence diagrams to quantify stability and consistency. Our results show that the topological structural complexity of reasoning chains correlates positively with accuracy. More complex chains identify correct answers sooner, while successful reasoning exhibits simpler topologies, reducing redundancy and cycles, enhancing efficiency and interpretability. This work provides a new perspective on reasoning chain quality assessment and offers guidance for future optimization.
SUCCESS-GS: Survey of Compactness and Compression for Efficient Static and Dynamic Gaussian Splatting
Dec 08, 2025



3D Gaussian Splatting (3DGS) has emerged as a powerful explicit representation enabling real-time, high-fidelity 3D reconstruction and novel view synthesis. However, its practical use is hindered by the massive memory and computational demands required to store and render millions of Gaussians. These challenges become even more severe in 4D dynamic scenes. To address these issues, the field of Efficient Gaussian Splatting has rapidly evolved, proposing methods that reduce redundancy while preserving reconstruction quality. This survey provides the first unified overview of efficient 3D and 4D Gaussian Splatting techniques. For both 3D and 4D settings, we systematically categorize existing methods into two major directions, Parameter Compression and Restructuring Compression, and comprehensively summarize the core ideas and methodological trends within each category. We further cover widely used datasets, evaluation metrics, and representative benchmark comparisons. Finally, we discuss current limitations and outline promising research directions toward scalable, compact, and real-time Gaussian Splatting for both static and dynamic 3D scene representation.
I-INR: Iterative Implicit Neural Representations
Apr 24, 2025Implicit Neural Representations (INRs) have revolutionized signal processing and computer vision by modeling signals as continuous, differentiable functions parameterized by neural networks. However, their inherent formulation as a regression problem makes them prone to regression to the mean, limiting their ability to capture fine details, retain high-frequency information, and handle noise effectively. To address these challenges, we propose Iterative Implicit Neural Representations (I-INRs) a novel plug-and-play framework that enhances signal reconstruction through an iterative refinement process. I-INRs effectively recover high-frequency details, improve robustness to noise, and achieve superior reconstruction quality. Our framework seamlessly integrates with existing INR architectures, delivering substantial performance gains across various tasks. Extensive experiments show that I-INRs outperform baseline methods, including WIRE, SIREN, and Gauss, in diverse computer vision applications such as image restoration, image denoising, and object occupancy prediction.
ELMGS: Enhancing memory and computation scaLability through coMpression for 3D Gaussian Splatting
Oct 30, 2024



3D models have recently been popularized by the potentiality of end-to-end training offered first by Neural Radiance Fields and most recently by 3D Gaussian Splatting models. The latter has the big advantage of naturally providing fast training convergence and high editability. However, as the research around these is still in its infancy, there is still a gap in the literature regarding the model's scalability. In this work, we propose an approach enabling both memory and computation scalability of such models. More specifically, we propose an iterative pruning strategy that removes redundant information encoded in the model. We also enhance compressibility for the model by including in the optimization strategy a differentiable quantization and entropy coding estimator. Our results on popular benchmarks showcase the effectiveness of the proposed approach and open the road to the broad deployability of such a solution even on resource-constrained devices.