 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandVQA: Diagnosing and Improving Fine-Grained Spatial Reasoning about Hands in Vision-Language Models
Mar 27, 2026Understanding the fine-grained articulation of human hands is critical in high-stakes settings such as robot-assisted surgery, chip manufacturing, and AR/VR-based human-AI interaction. Despite achieving near-human performance on general vision-language benchmarks, current vision-language models (VLMs) struggle with fine-grained spatial reasoning, especially in interpreting complex and articulated hand poses. We introduce HandVQA, a large-scale diagnostic benchmark designed to evaluate VLMs' understanding of detailed hand anatomy through visual question answering. Built upon high-quality 3D hand datasets (FreiHAND, InterHand2.6M, FPHA), our benchmark includes over 1.6M controlled multiple-choice questions that probe spatial relationships between hand joints, such as angles, distances, and relative positions. We evaluate several state-of-the-art VLMs (LLaVA, DeepSeek and Qwen-VL) in both base and fine-tuned settings, using lightweight fine-tuning via LoRA. Our findings reveal systematic limitations in current models, including hallucinated finger parts, incorrect geometric interpretations, and poor generalization. HandVQA not only exposes these critical reasoning gaps but provides a validated path to improvement. We demonstrate that the 3D-grounded spatial knowledge learned from our benchmark transfers in a zero-shot setting, significantly improving accuracy of model on novel downstream tasks like hand gesture recognition (+10.33%) and hand-object interaction (+2.63%).
I-INR: Iterative Implicit Neural Representations
Apr 24, 2025Implicit Neural Representations (INRs) have revolutionized signal processing and computer vision by modeling signals as continuous, differentiable functions parameterized by neural networks. However, their inherent formulation as a regression problem makes them prone to regression to the mean, limiting their ability to capture fine details, retain high-frequency information, and handle noise effectively. To address these challenges, we propose Iterative Implicit Neural Representations (I-INRs) a novel plug-and-play framework that enhances signal reconstruction through an iterative refinement process. I-INRs effectively recover high-frequency details, improve robustness to noise, and achieve superior reconstruction quality. Our framework seamlessly integrates with existing INR architectures, delivering substantial performance gains across various tasks. Extensive experiments show that I-INRs outperform baseline methods, including WIRE, SIREN, and Gauss, in diverse computer vision applications such as image restoration, image denoising, and object occupancy prediction.
ELMGS: Enhancing memory and computation scaLability through coMpression for 3D Gaussian Splatting
Oct 30, 2024



3D models have recently been popularized by the potentiality of end-to-end training offered first by Neural Radiance Fields and most recently by 3D Gaussian Splatting models. The latter has the big advantage of naturally providing fast training convergence and high editability. However, as the research around these is still in its infancy, there is still a gap in the literature regarding the model's scalability. In this work, we propose an approach enabling both memory and computation scalability of such models. More specifically, we propose an iterative pruning strategy that removes redundant information encoded in the model. We also enhance compressibility for the model by including in the optimization strategy a differentiable quantization and entropy coding estimator. Our results on popular benchmarks showcase the effectiveness of the proposed approach and open the road to the broad deployability of such a solution even on resource-constrained devices.
A Deep Features-Based Approach Using Modified ResNet50 and Gradient Boosting for Visual Sentiments Classification
Aug 15, 2024The versatile nature of Visual Sentiment Analysis (VSA) is one reason for its rising profile. It isn't easy to efficiently manage social media data with visual information since previous research has concentrated on Sentiment Analysis (SA) of single modalities, like textual. In addition, most visual sentiment studies need to adequately classify sentiment because they are mainly focused on simply merging modal attributes without investigating their intricate relationships. This prompted the suggestion of developing a fusion of deep learning and machine learning algorithms. In this research, a deep feature-based method for multiclass classification has been used to extract deep features from modified ResNet50. Furthermore, gradient boosting algorithm has been used to classify photos containing emotional content. The approach is thoroughly evaluated on two benchmarked datasets, CrowdFlower and GAPED. Finally, cutting-edge deep learning and machine learning models were used to compare the proposed strategy. When compared to state-of-the-art approaches, the proposed method demonstrates exceptional performance on the datasets presented.
Trimming the Fat: Efficient Compression of 3D Gaussian Splats through Pruning
Jun 26, 2024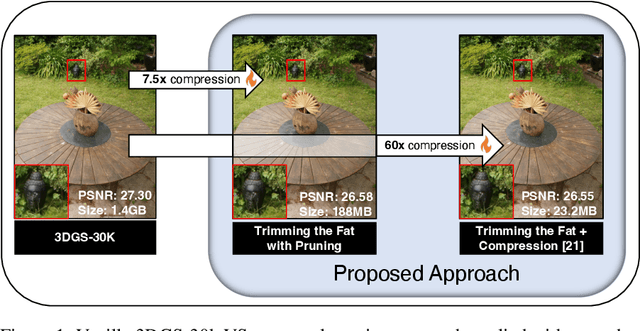
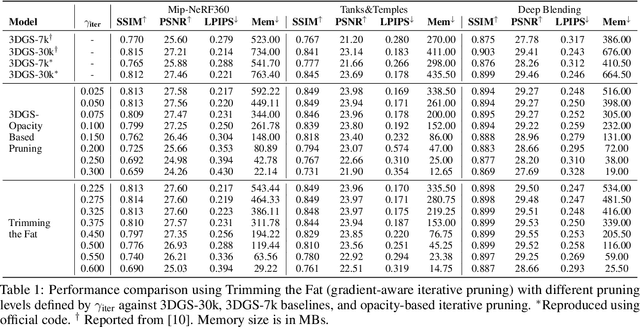
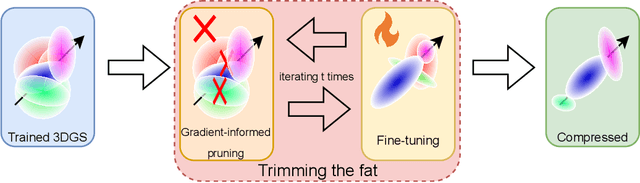
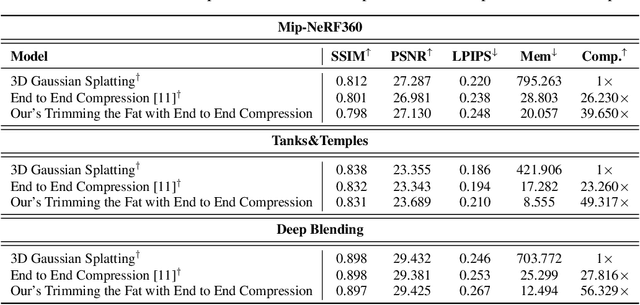
In recent times, the utilization of 3D models has gained traction, owing to the capacity for end-to-end training initially offered by Neural Radiance Fields and more recently by 3D Gaussian Splatting (3DGS) models. The latter holds a significant advantage by inherently easing rapid convergence during training and offering extensive editability. However, despite rapid advancements, the literature still lives in its infancy regarding the scalability of these models. In this study, we take some initial steps in addressing this gap, showing an approach that enables both the memory and computational scalability of such models. Specifically, we propose "Trimming the fat", a post-hoc gradient-informed iterative pruning technique to eliminate redundant information encoded in the model. Our experimental findings on widely acknowledged benchmarks attest to the effectiveness of our approach, revealing that up to 75% of the Gaussians can be removed while maintaining or even improving upon baseline performance. Our approach achieves around 50$\times$ compression while preserving performance similar to the baseline model, and is able to speed-up computation up to 600~FPS.