 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrimming the Fat: Efficient Compression of 3D Gaussian Splats through Pruning
Paper and Code
Jun 26, 2024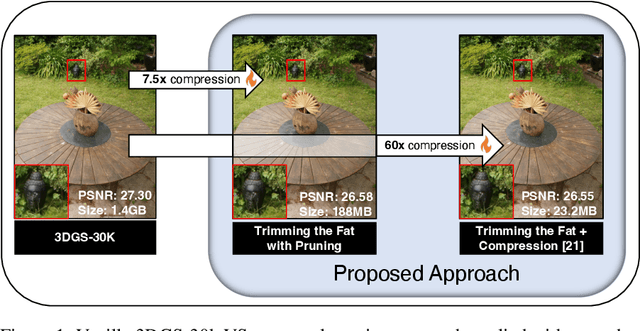
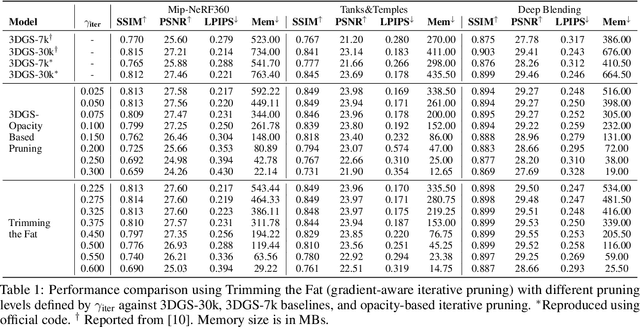
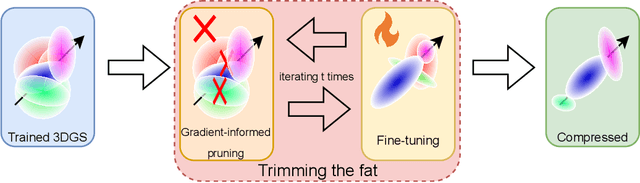
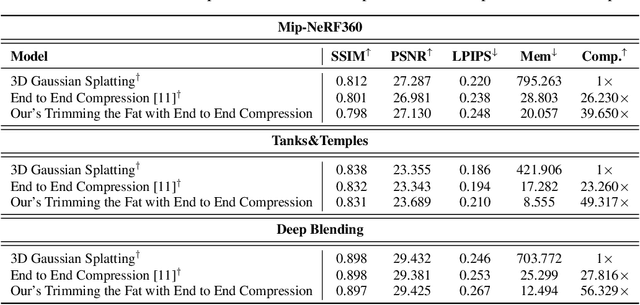
In recent times, the utilization of 3D models has gained traction, owing to the capacity for end-to-end training initially offered by Neural Radiance Fields and more recently by 3D Gaussian Splatting (3DGS) models. The latter holds a significant advantage by inherently easing rapid convergence during training and offering extensive editability. However, despite rapid advancements, the literature still lives in its infancy regarding the scalability of these models. In this study, we take some initial steps in addressing this gap, showing an approach that enables both the memory and computational scalability of such models. Specifically, we propose "Trimming the fat", a post-hoc gradient-informed iterative pruning technique to eliminate redundant information encoded in the model. Our experimental findings on widely acknowledged benchmarks attest to the effectiveness of our approach, revealing that up to 75% of the Gaussians can be removed while maintaining or even improving upon baseline performance. Our approach achieves around 50$\times$ compression while preserving performance similar to the baseline model, and is able to speed-up computation up to 600~FPS.