 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-based Preference Optimization for Test-time Adaptation
May 26, 2025Test-Time Adaptation (TTA) enhances model robustness by enabling adaptation to target distributions that differ from training distributions, improving real-world generalizability. Existing TTA approaches focus on adjusting the conditional distribution; however these methods often depend on uncertain predictions in the absence of label information, leading to unreliable performance. Energy-based frameworks suggest a promising alternative to address distribution shifts without relying on uncertain predictions, instead computing the marginal distribution of target data. However, they involve the critical challenge of requiring extensive SGLD sampling, which is impractical for test-time scenarios requiring immediate adaptation. In this work, we propose Energy-based Preference Optimization for Test-time Adaptation (EPOTTA), which is based on a sampling free strategy. We first parameterize the target model using a pretrained model and residual energy function, enabling marginal likelihood maximization of target data without sampling. Building on the observation that the parameterization is mathematically equivalent to DPO objective, we then directly adapt the model to a target distribution without explicitly training the residual. Our experiments verify that EPOTTA is well-calibrated and performant while achieving computational efficiency.
Descanning: From Scanned to the Original Images with a Color Correction Diffusion Model
Feb 08, 2024
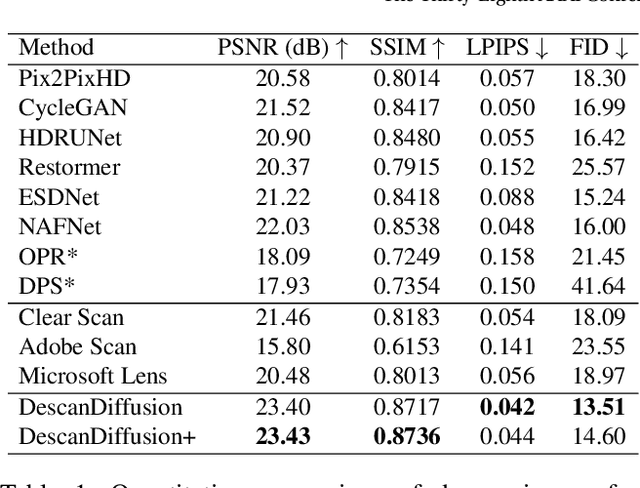

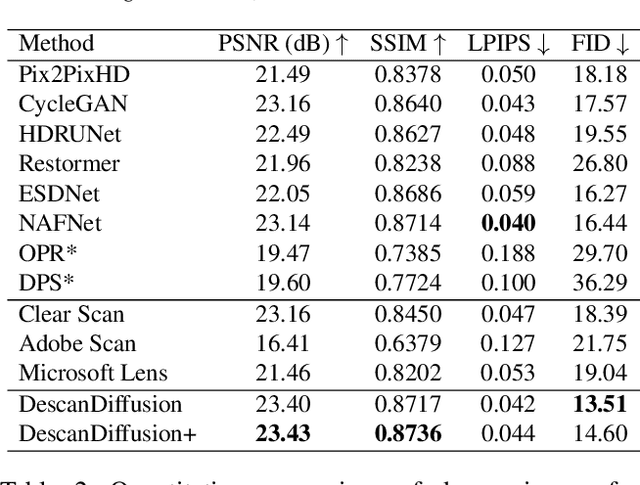
A significant volume of analog information, i.e., documents and images, have been digitized in the form of scanned copies for storing, sharing, and/or analyzing in the digital world. However, the quality of such contents is severely degraded by various distortions caused by printing, storing, and scanning processes in the physical world. Although restoring high-quality content from scanned copies has become an indispensable task for many products, it has not been systematically explored, and to the best of our knowledge, no public datasets are available. In this paper, we define this problem as Descanning and introduce a new high-quality and large-scale dataset named DESCAN-18K. It contains 18K pairs of original and scanned images collected in the wild containing multiple complex degradations. In order to eliminate such complex degradations, we propose a new image restoration model called DescanDiffusion consisting of a color encoder that corrects the global color degradation and a conditional denoising diffusion probabilistic model (DDPM) that removes local degradations. To further improve the generalization ability of DescanDiffusion, we also design a synthetic data generation scheme by reproducing prominent degradations in scanned images. We demonstrate that our DescanDiffusion outperforms other baselines including commercial restoration products, objectively and subjectively, via comprehensive experiments and analyses.
Flexible Cross-Modal Steganography via Implicit Representations
Dec 12, 2023
We present INRSteg, an innovative lossless steganography framework based on a novel data form Implicit Neural Representations (INR) that is modal-agnostic. Our framework is considered for effectively hiding multiple data without altering the original INR ensuring high-quality stego data. The neural representations of secret data are first concatenated to have independent paths that do not overlap, then weight freezing techniques are applied to the diagonal blocks of the weight matrices for the concatenated network to preserve the weights of secret data while additional free weights in the off-diagonal blocks of weight matrices are fitted to the cover data. Our framework can perform unexplored cross-modal steganography for various modalities including image, audio, video, and 3D shapes, and it achieves state-of-the-art performance compared to previous intra-modal steganographic methods.
PGA: Personalizing Grasping Agents with Single Human-Robot Interaction
Oct 19, 2023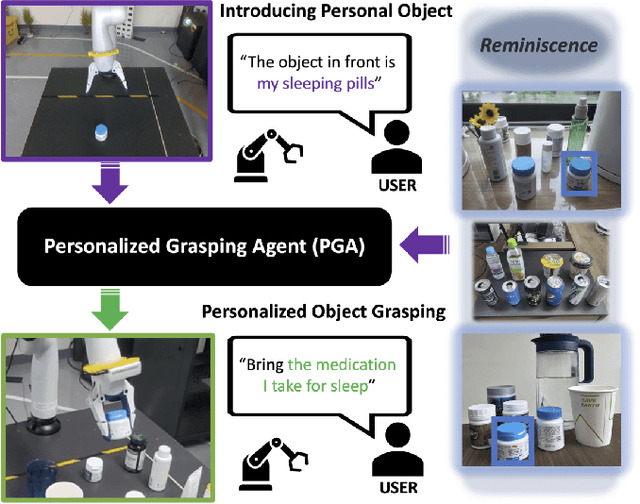
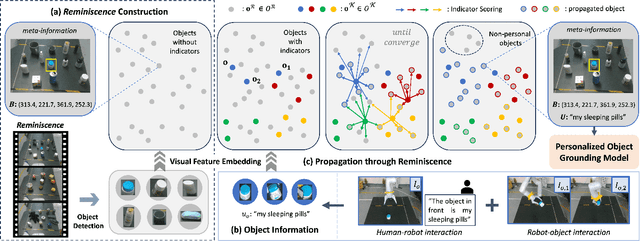
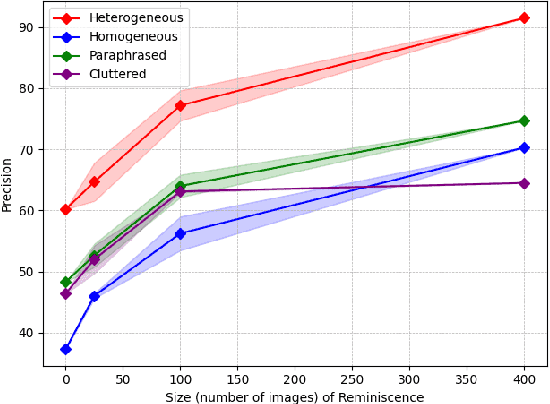
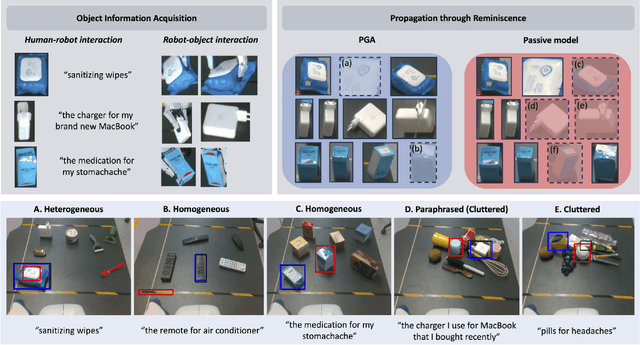
Language-Conditioned Robotic Grasping (LCRG) aims to develop robots that ground and grasp objects based on natural language instructions. While robots capable of recognizing personal objects like "my wallet" can interact more naturally with non-expert users, current LCRG systems primarily limit robots to understanding only generic expressions. To this end, we introduce a task scenario GraspMine with a novel dataset that aims to locate and grasp personal objects given personal indicators via learning from a single human-robot interaction. To address GraspMine, we propose Personalized Grasping Agent (PGA), that learns personal objects by propagating user-given information through a Reminiscence-a collection of raw images from the user's environment. Specifically, PGA acquires personal object information by a user presenting a personal object with its associated indicator, followed by PGA inspecting the object by rotating it. Based on the acquired information, PGA pseudo-labels objects in the Reminiscence by our proposed label propagation algorithm. Harnessing the information acquired from the interactions and the pseudo-labeled objects in the Reminiscence, PGA adapts the object grounding model to grasp personal objects. Experiments on GraspMine show that PGA significantly outperforms baseline methods both in offline and online settings, signifying its effectiveness and personalization applicability on real-world scenarios. Finally, qualitative analysis shows the effectiveness of PGA through a detailed investigation of results in each phase.