 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoGround: Self-Evolving Video Agents for Video Temporal Grounding
May 13, 2026Video temporal grounding (VTG) takes an untrimmed video and a natural-language query as input and localizes the temporal moment that best matches the query. Existing methods rely on large, task-specific datasets requiring costly manual annotation. We introduce EvoGround, a framework of two coupled self-evolving agents, a proposer and a solver, that learn temporal grounding from raw videos without any human-labeled data. The proposer generates query--moment pairs from raw videos, while the solver learns to ground them and feeds back signals that improve the proposer in return. Through this self-reinforcing reinforcement-learning loop, the two agents are initialized from the same backbone and mutually improve across iterations. Trained on 2.5K unlabeled videos, EvoGround matches or surpasses fully supervised models across multiple VTG benchmarks, while emerging as a state-of-the-art fine-grained video captioner without manual labels.
EgoExo-Con: Exploring View-Invariant Video Temporal Understanding
Oct 30, 2025Can Video-LLMs achieve consistent temporal understanding when videos capture the same event from different viewpoints? To study this, we introduce EgoExo-Con (Consistency), a benchmark of comprehensively synchronized egocentric and exocentric video pairs with human-refined queries in natural language. EgoExo-Con emphasizes two temporal understanding tasks: Temporal Verification and Temporal Grounding. It evaluates not only correctness but consistency across viewpoints. Our analysis reveals two critical limitations of existing Video-LLMs: (1) models often fail to maintain consistency, with results far worse than their single-view performances. (2) When naively finetuned with synchronized videos of both viewpoints, the models show improved consistency but often underperform those trained on a single view. For improvements, we propose View-GRPO, a novel reinforcement learning framework that effectively strengthens view-specific temporal reasoning while encouraging consistent comprehension across viewpoints. Our method demonstrates its superiority over naive SFT and GRPO, especially for improving cross-view consistency. All resources will be made publicly available.
Exploring Ordinal Bias in Action Recognition for Instructional Videos
Apr 09, 2025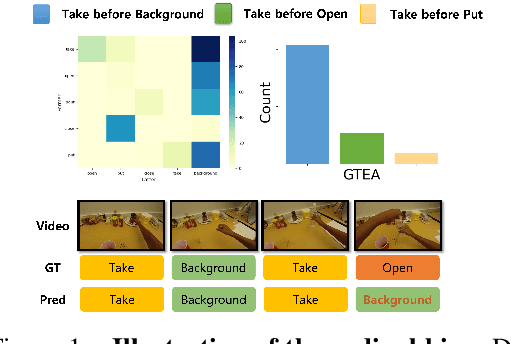

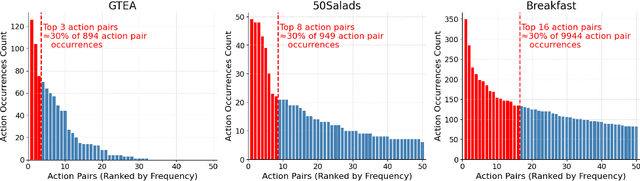

Action recognition models have achieved promising results in understanding instructional videos. However, they often rely on dominant, dataset-specific action sequences rather than true video comprehension, a problem that we define as ordinal bias. To address this issue, we propose two effective video manipulation methods: Action Masking, which masks frames of frequently co-occurring actions, and Sequence Shuffling, which randomizes the order of action segments. Through comprehensive experiments, we demonstrate that current models exhibit significant performance drops when confronted with nonstandard action sequences, underscoring their vulnerability to ordinal bias. Our findings emphasize the importance of rethinking evaluation strategies and developing models capable of generalizing beyond fixed action patterns in diverse instructional videos.
On the Consistency of Video Large Language Models in Temporal Comprehension
Nov 20, 2024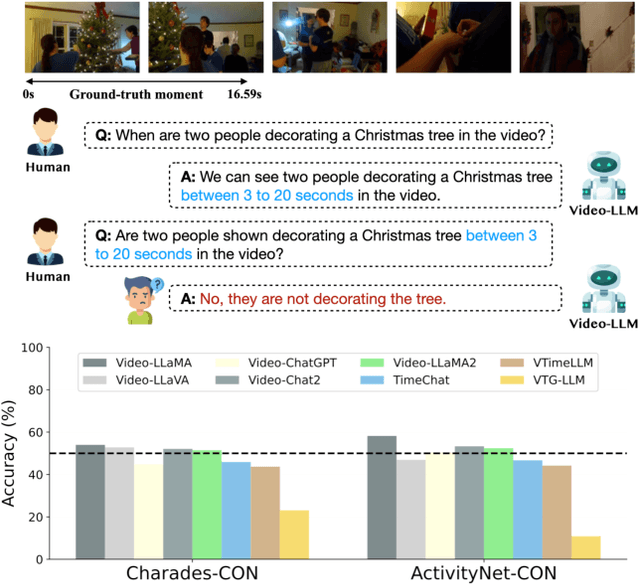
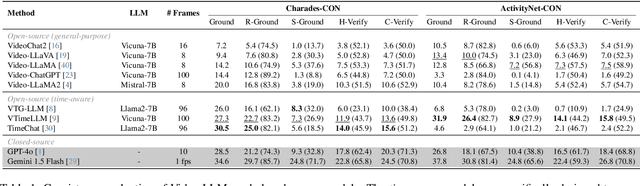

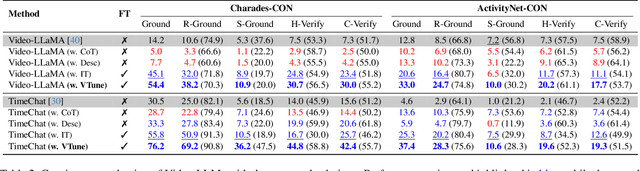
Video large language models (Video-LLMs) can temporally ground language queries and retrieve video moments. Yet, such temporal comprehension capabilities are neither well-studied nor understood. So we conduct a study on prediction consistency -- a key indicator for robustness and trustworthiness of temporal grounding. After the model identifies an initial moment within the video content, we apply a series of probes to check if the model's responses align with this initial grounding as an indicator of reliable comprehension. Our results reveal that current Video-LLMs are sensitive to variations in video contents, language queries, and task settings, unveiling severe deficiencies in maintaining consistency. We further explore common prompting and instruction-tuning methods as potential solutions, but find that their improvements are often unstable. To that end, we propose event temporal verification tuning that explicitly accounts for consistency, and demonstrate significant improvements for both grounding and consistency. Our data and code will be available at https://github.com/minjoong507/Consistency-of-Video-LLM.
PGA: Personalizing Grasping Agents with Single Human-Robot Interaction
Oct 19, 2023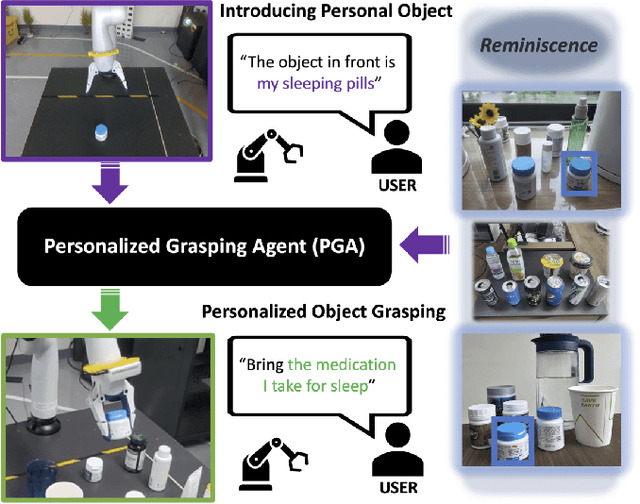
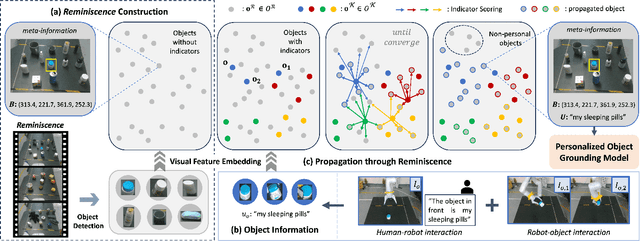
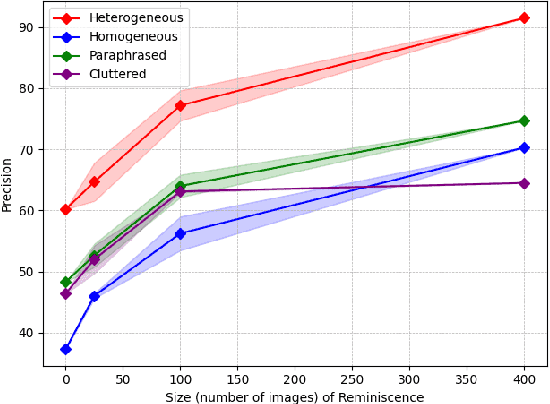
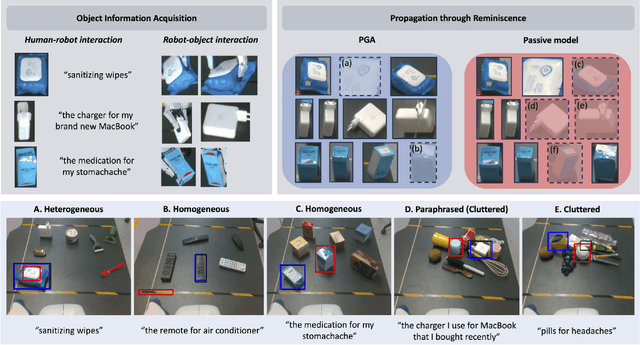
Language-Conditioned Robotic Grasping (LCRG) aims to develop robots that ground and grasp objects based on natural language instructions. While robots capable of recognizing personal objects like "my wallet" can interact more naturally with non-expert users, current LCRG systems primarily limit robots to understanding only generic expressions. To this end, we introduce a task scenario GraspMine with a novel dataset that aims to locate and grasp personal objects given personal indicators via learning from a single human-robot interaction. To address GraspMine, we propose Personalized Grasping Agent (PGA), that learns personal objects by propagating user-given information through a Reminiscence-a collection of raw images from the user's environment. Specifically, PGA acquires personal object information by a user presenting a personal object with its associated indicator, followed by PGA inspecting the object by rotating it. Based on the acquired information, PGA pseudo-labels objects in the Reminiscence by our proposed label propagation algorithm. Harnessing the information acquired from the interactions and the pseudo-labeled objects in the Reminiscence, PGA adapts the object grounding model to grasp personal objects. Experiments on GraspMine show that PGA significantly outperforms baseline methods both in offline and online settings, signifying its effectiveness and personalization applicability on real-world scenarios. Finally, qualitative analysis shows the effectiveness of PGA through a detailed investigation of results in each phase.
Overcoming Weak Visual-Textual Alignment for Video Moment Retrieval
Jun 05, 2023
Video moment retrieval (VMR) aims to identify the specific moment in an untrimmed video for a given natural language query. However, this task is prone to suffer the weak visual-textual alignment problem from query ambiguity, potentially limiting further performance gains and generalization capability. Due to the complex multimodal interactions in videos, a query may not fully cover the relevant details of the corresponding moment, and the moment may contain misaligned and irrelevant frames. To tackle this problem, we propose a straightforward yet effective model, called Background-aware Moment DEtection TRansformer (BM-DETR). Given a target query and its moment, BM-DETR also takes negative queries corresponding to different moments. Specifically, our model learns to predict the target moment from the joint probability of the given query and the complement of negative queries for each candidate frame. In this way, it leverages the surrounding background to consider relative importance, improving moment sensitivity. Extensive experiments on Charades-STA and QVHighlights demonstrate the effectiveness of our model. Moreover, we show that BM-DETR can perform robustly in three challenging VMR scenarios, such as several out-of-distribution test cases, demonstrating superior generalization ability.
Modal-specific Pseudo Query Generation for Video Corpus Moment Retrieval
Oct 23, 2022Video corpus moment retrieval (VCMR) is the task to retrieve the most relevant video moment from a large video corpus using a natural language query. For narrative videos, e.g., dramas or movies, the holistic understanding of temporal dynamics and multimodal reasoning is crucial. Previous works have shown promising results; however, they relied on the expensive query annotations for VCMR, i.e., the corresponding moment intervals. To overcome this problem, we propose a self-supervised learning framework: Modal-specific Pseudo Query Generation Network (MPGN). First, MPGN selects candidate temporal moments via subtitle-based moment sampling. Then, it generates pseudo queries exploiting both visual and textual information from the selected temporal moments. Through the multimodal information in the pseudo queries, we show that MPGN successfully learns to localize the video corpus moment without any explicit annotation. We validate the effectiveness of MPGN on the TVR dataset, showing competitive results compared with both supervised models and unsupervised setting models.
Toward a Human-Level Video Understanding Intelligence
Oct 18, 2021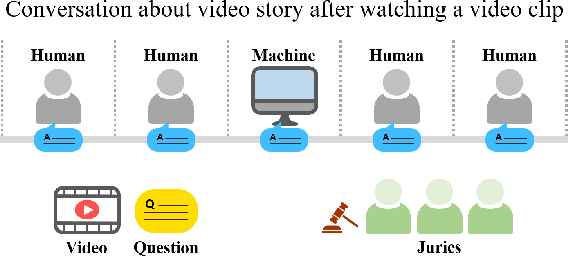

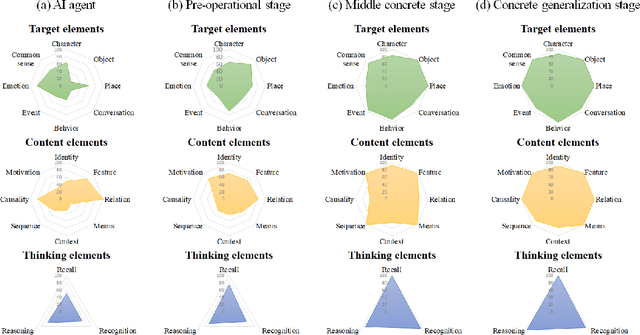
We aim to develop an AI agent that can watch video clips and have a conversation with human about the video story. Developing video understanding intelligence is a significantly challenging task, and evaluation methods for adequately measuring and analyzing the progress of AI agent are lacking as well. In this paper, we propose the Video Turing Test to provide effective and practical assessments of video understanding intelligence as well as human-likeness evaluation of AI agents. We define a general format and procedure of the Video Turing Test and present a case study to confirm the effectiveness and usefulness of the proposed test.