 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGRAM: Improving Scene Graph Parsing via Abstract Meaning Representation
Oct 17, 2022

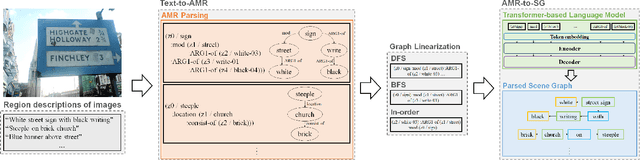
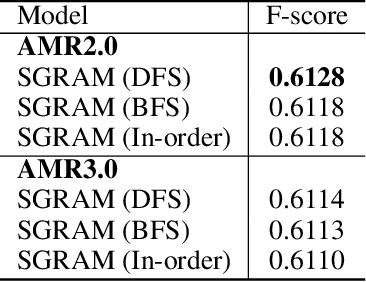
Scene graph is structured semantic representation that can be modeled as a form of graph from images and texts. Image-based scene graph generation research has been actively conducted until recently, whereas text-based scene graph generation research has not. In this paper, we focus on the problem of scene graph parsing from textual description of a visual scene. The core idea is to use abstract meaning representation (AMR) instead of the dependency parsing mainly used in previous studies. AMR is a graph-based semantic formalism of natural language which abstracts concepts of words in a sentence contrary to the dependency parsing which considers dependency relationships on all words in a sentence. To this end, we design a simple yet effective two-stage scene graph parsing framework utilizing abstract meaning representation, SGRAM (Scene GRaph parsing via Abstract Meaning representation): 1) transforming a textual description of an image into an AMR graph (Text-to-AMR) and 2) encoding the AMR graph into a Transformer-based language model to generate a scene graph (AMR-to-SG). Experimental results show the scene graphs generated by our framework outperforms the dependency parsing-based model by 11.61\% and the previous state-of-the-art model using a pre-trained Transformer language model by 3.78\%. Furthermore, we apply SGRAM to image retrieval task which is one of downstream tasks for scene graph, and confirm the effectiveness of scene graphs generated by our framework.
Hypergraph Transformer: Weakly-supervised Multi-hop Reasoning for Knowledge-based Visual Question Answering
Apr 22, 2022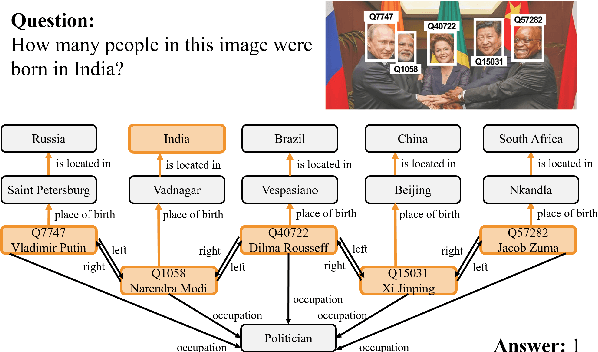
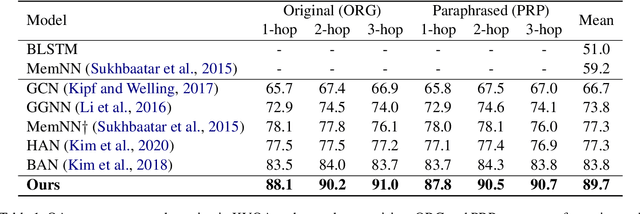
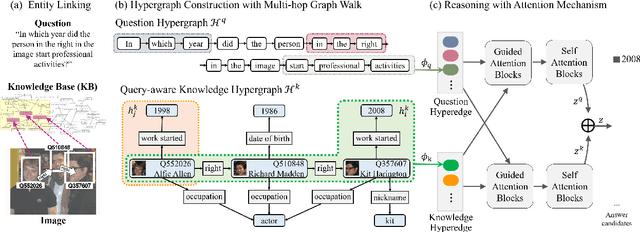
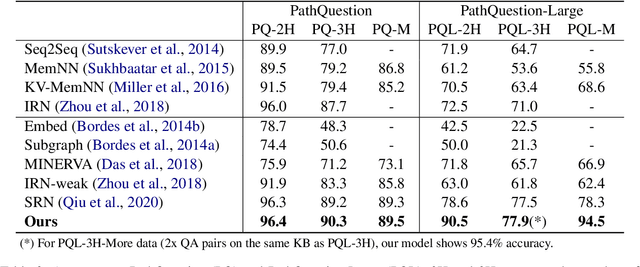
Knowledge-based visual question answering (QA) aims to answer a question which requires visually-grounded external knowledge beyond image content itself. Answering complex questions that require multi-hop reasoning under weak supervision is considered as a challenging problem since i) no supervision is given to the reasoning process and ii) high-order semantics of multi-hop knowledge facts need to be captured. In this paper, we introduce a concept of hypergraph to encode high-level semantics of a question and a knowledge base, and to learn high-order associations between them. The proposed model, Hypergraph Transformer, constructs a question hypergraph and a query-aware knowledge hypergraph, and infers an answer by encoding inter-associations between two hypergraphs and intra-associations in both hypergraph itself. Extensive experiments on two knowledge-based visual QA and two knowledge-based textual QA demonstrate the effectiveness of our method, especially for multi-hop reasoning problem. Our source code is available at https://github.com/yujungheo/kbvqa-public.
Toward a Human-Level Video Understanding Intelligence
Oct 18, 2021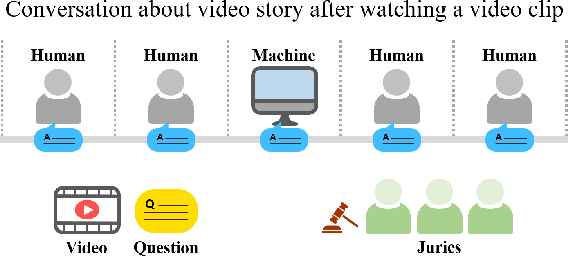

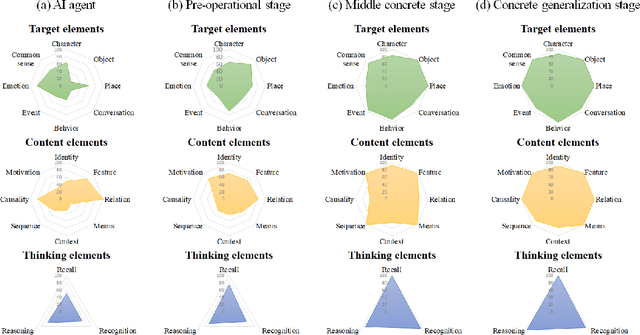
We aim to develop an AI agent that can watch video clips and have a conversation with human about the video story. Developing video understanding intelligence is a significantly challenging task, and evaluation methods for adequately measuring and analyzing the progress of AI agent are lacking as well. In this paper, we propose the Video Turing Test to provide effective and practical assessments of video understanding intelligence as well as human-likeness evaluation of AI agents. We define a general format and procedure of the Video Turing Test and present a case study to confirm the effectiveness and usefulness of the proposed test.