 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"There Is No Such Thing as a Dumb Question," But There Are Good Ones
May 15, 2025Questioning has become increasingly crucial for both humans and artificial intelligence, yet there remains limited research comprehensively assessing question quality. In response, this study defines good questions and presents a systematic evaluation framework. We propose two key evaluation dimensions: appropriateness (sociolinguistic competence in context) and effectiveness (strategic competence in goal achievement). Based on these foundational dimensions, a rubric-based scoring system was developed. By incorporating dynamic contextual variables, our evaluation framework achieves structure and flexibility through semi-adaptive criteria. The methodology was validated using the CAUS and SQUARE datasets, demonstrating the ability of the framework to access both well-formed and problematic questions while adapting to varied contexts. As we establish a flexible and comprehensive framework for question evaluation, this study takes a significant step toward integrating questioning behavior with structured analytical methods grounded in the intrinsic nature of questioning.
CAUS: A Dataset for Question Generation based on Human Cognition Leveraging Large Language Models
Apr 18, 2024



We introduce the CAUS (Curious About Uncertain Scene) dataset, designed to enable Large Language Models, specifically GPT-4, to emulate human cognitive processes for resolving uncertainties. Leveraging this dataset, we investigate the potential of LLMs to engage in questioning effectively. Our approach involves providing scene descriptions embedded with uncertainties to stimulate the generation of reasoning and queries. The queries are then classified according to multi-dimensional criteria. All procedures are facilitated by a collaborative system involving both LLMs and human researchers. Our results demonstrate that GPT-4 can effectively generate pertinent questions and grasp their nuances, particularly when given appropriate context and instructions. The study suggests that incorporating human-like questioning into AI models improves their ability to manage uncertainties, paving the way for future advancements in Artificial Intelligence (AI).
Toward a Human-Level Video Understanding Intelligence
Oct 18, 2021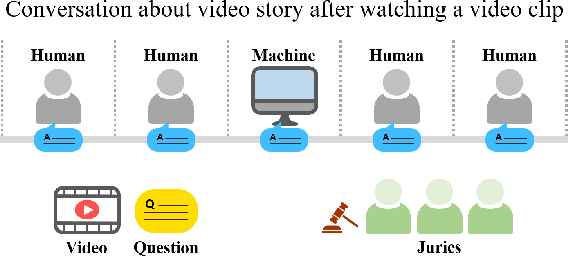

We aim to develop an AI agent that can watch video clips and have a conversation with human about the video story. Developing video understanding intelligence is a significantly challenging task, and evaluation methods for adequately measuring and analyzing the progress of AI agent are lacking as well. In this paper, we propose the Video Turing Test to provide effective and practical assessments of video understanding intelligence as well as human-likeness evaluation of AI agents. We define a general format and procedure of the Video Turing Test and present a case study to confirm the effectiveness and usefulness of the proposed test.
CogME: A Novel Evaluation Metric for Video Understanding Intelligence
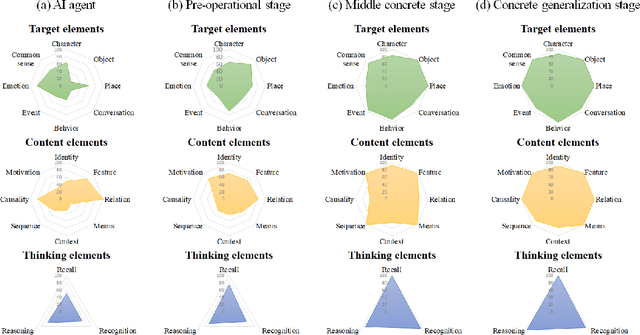
Jul 21, 2021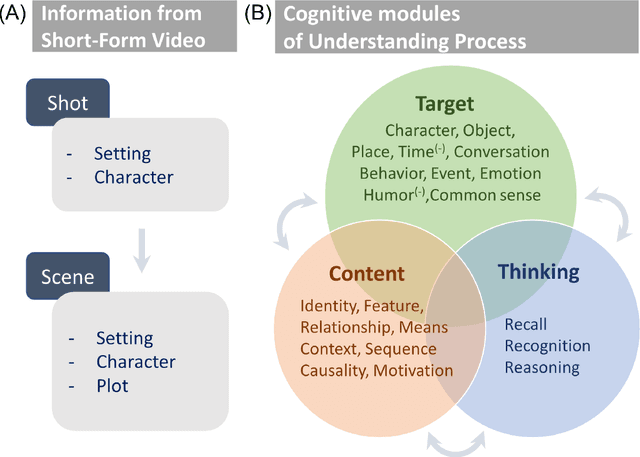
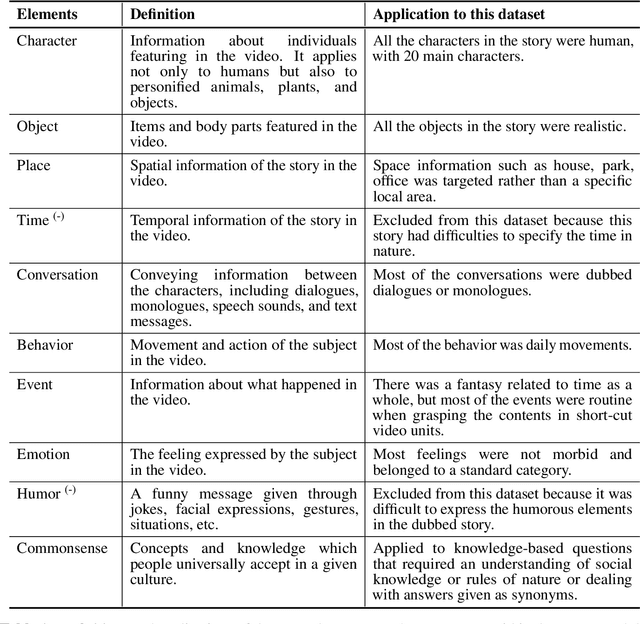
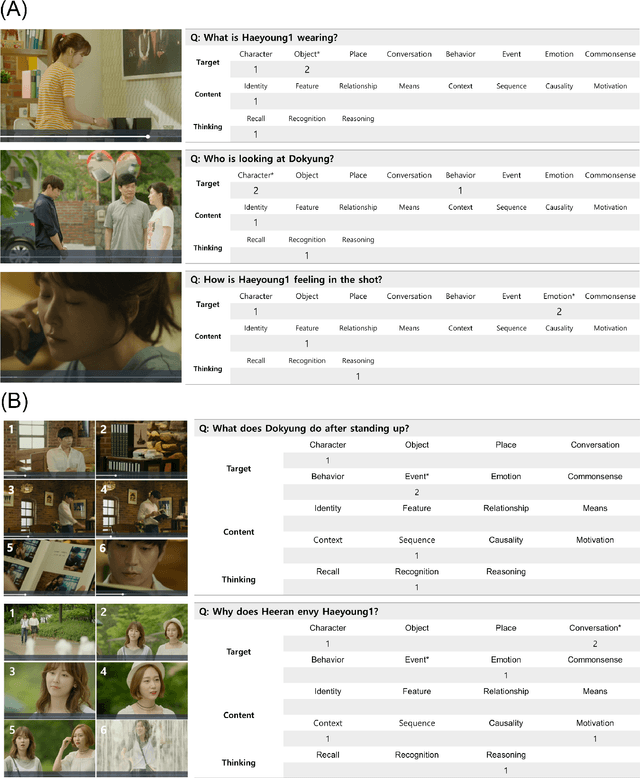
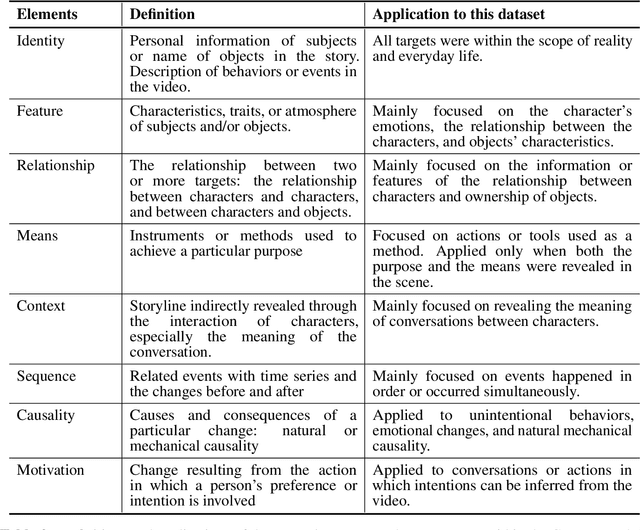
Developing video understanding intelligence is quite challenging because it requires holistic integration of images, scripts, and sounds based on natural language processing, temporal dependency, and reasoning. Recently, substantial attempts have been made on several video datasets with associated question answering (QA) on a large scale. However, existing evaluation metrics for video question answering (VideoQA) do not provide meaningful analysis. To make progress, we argue that a well-made framework, established on the way humans understand, is required to explain and evaluate the performance of understanding in detail. Then we propose a top-down evaluation system for VideoQA, based on the cognitive process of humans and story elements: Cognitive Modules for Evaluation (CogME). CogME is composed of three cognitive modules: targets, contents, and thinking. The interaction among the modules in the understanding procedure can be expressed in one sentence as follows: "I understand the CONTENT of the TARGET through a way of THINKING." Each module has sub-components derived from the story elements. We can specify the required aspects of understanding by annotating the sub-components to individual questions. CogME thus provides a framework for an elaborated specification of VideoQA datasets. To examine the suitability of a VideoQA dataset for validating video understanding intelligence, we evaluated the baseline model of the DramaQA dataset by applying CogME. The evaluation reveals that story elements are unevenly reflected in the existing dataset, and the model based on the dataset may cause biased predictions. Although this study has only been able to grasp a narrow range of stories, we expect that it offers the first step in considering the cognitive process of humans on the video understanding intelligence of humans and AI.
Gentlemen on the Road: Effect of Yielding Behavior of Autonomous Vehicle on Pedestrian Head Orientation
May 16, 2020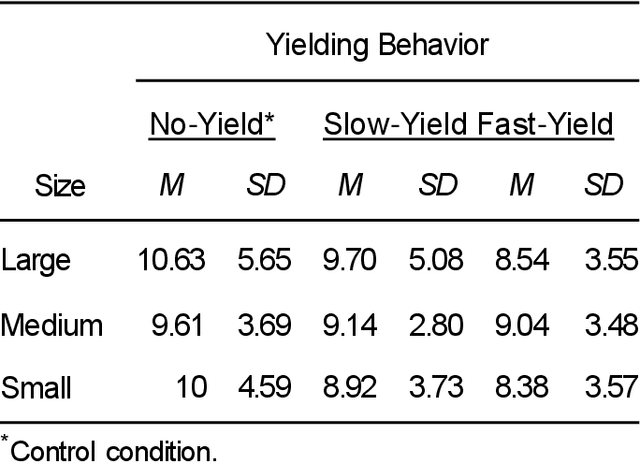

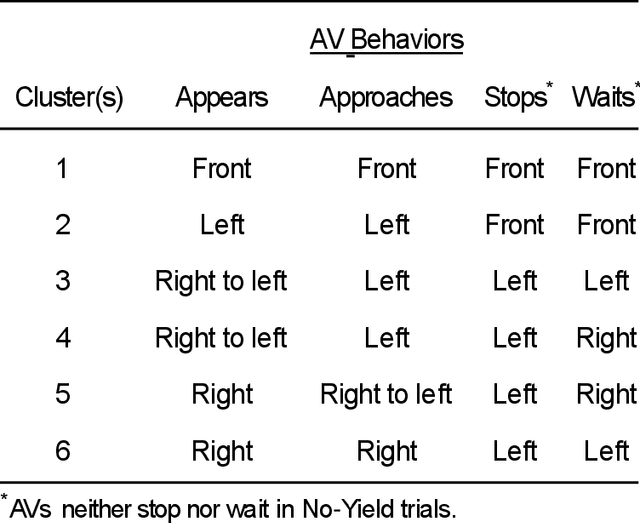
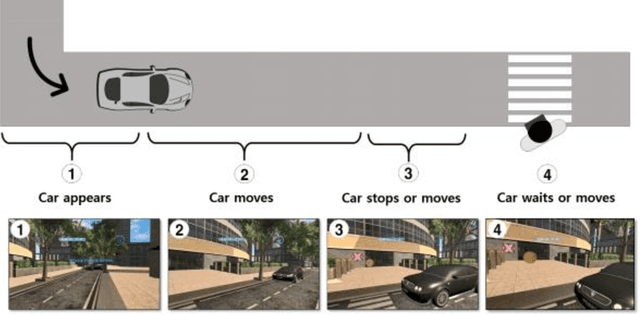
Autonomous vehicles can improve pedestrian safety by learning human-like social behaviors (e.g., yielding). We conducted a virtual reality experiment with 39 participants and measured crossing times (seconds) and head orientation (yaw degrees). We manipulated AV yielding behavior (no-yield, slow-yield, and fast-yield) and the AV size (small, medium, and large). Using Dynamic time warping and K-means clustering, we classified the head orientation change of pedestrians by time into 6 clusters of patterns. Results indicate that head orientation change of pedestrians was influenced by AV yielding behavior as well as the size of the AV. Participants fixated on the front most of the time even when the car approached near. Participants changed head orientation most frequently when a large size AV did not yield (no-yield). In post-experiment interviews, participants reported that yielding behavior and size affected their decision to cross and perceived safety. For autonomous vehicles to be perceived as more safe and trustful, vehicle-specific factors such as size and yielding behavior should be considered in the designing process.
Constructing Hierarchical Q&A Datasets for Video Story Understanding
Apr 01, 2019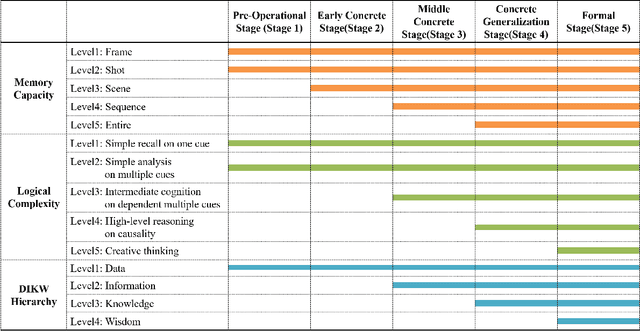
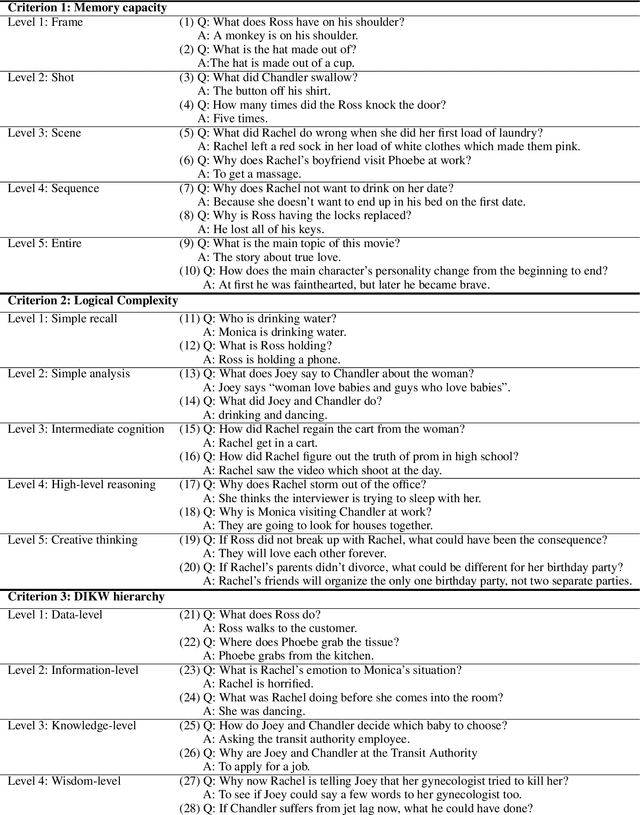
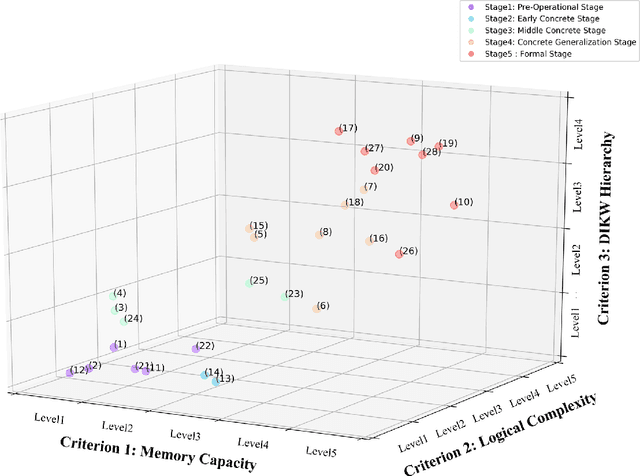
Video understanding is emerging as a new paradigm for studying human-like AI. Question-and-Answering (Q&A) is used as a general benchmark to measure the level of intelligence for video understanding. While several previous studies have suggested datasets for video Q&A tasks, they did not really incorporate story-level understanding, resulting in highly-biased and lack of variance in degree of question difficulty. In this paper, we propose a hierarchical method for building Q&A datasets, i.e. hierarchical difficulty levels. We introduce three criteria for video story understanding, i.e. memory capacity, logical complexity, and DIKW (Data-Information-Knowledge-Wisdom) pyramid. We discuss how three-dimensional map constructed from these criteria can be used as a metric for evaluating the levels of intelligence relating to video story understanding.