 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogME: A Novel Evaluation Metric for Video Understanding Intelligence
Paper and Code
Jul 21, 2021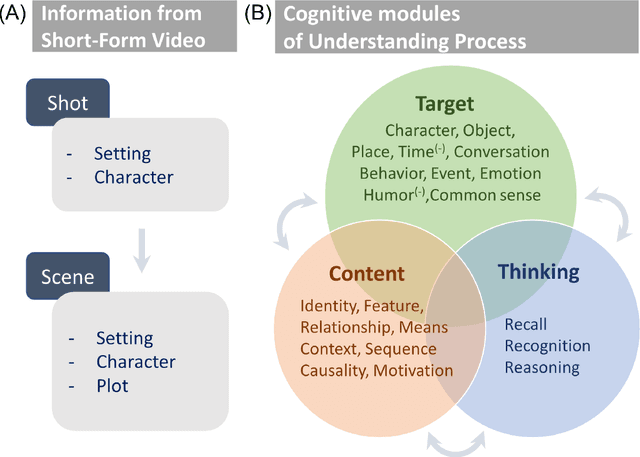
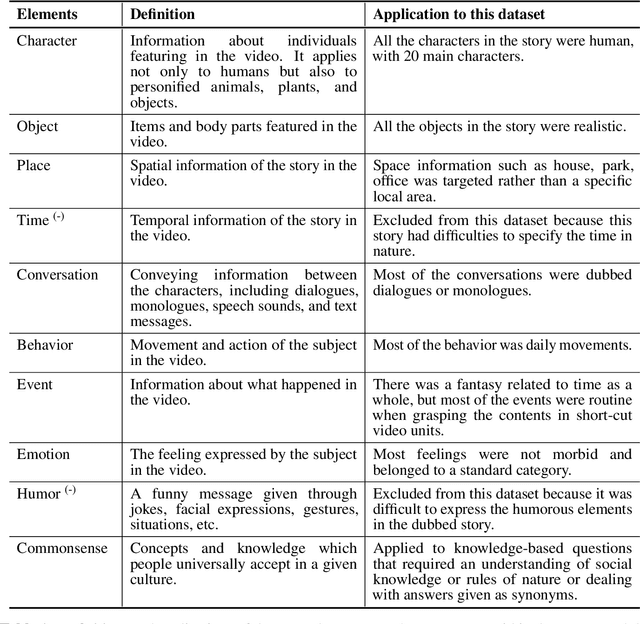
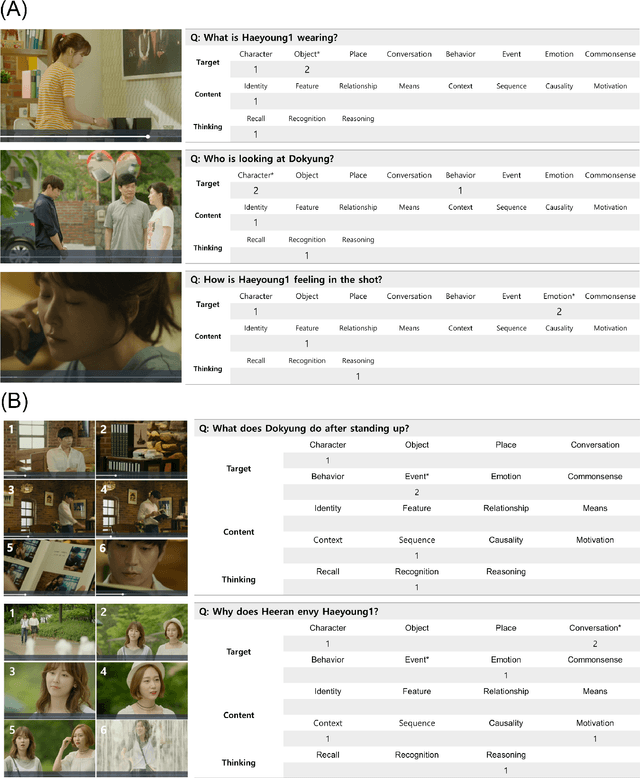
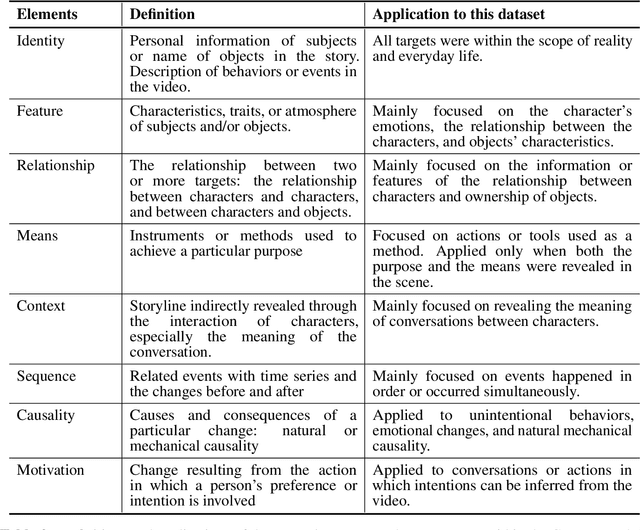
Developing video understanding intelligence is quite challenging because it requires holistic integration of images, scripts, and sounds based on natural language processing, temporal dependency, and reasoning. Recently, substantial attempts have been made on several video datasets with associated question answering (QA) on a large scale. However, existing evaluation metrics for video question answering (VideoQA) do not provide meaningful analysis. To make progress, we argue that a well-made framework, established on the way humans understand, is required to explain and evaluate the performance of understanding in detail. Then we propose a top-down evaluation system for VideoQA, based on the cognitive process of humans and story elements: Cognitive Modules for Evaluation (CogME). CogME is composed of three cognitive modules: targets, contents, and thinking. The interaction among the modules in the understanding procedure can be expressed in one sentence as follows: "I understand the CONTENT of the TARGET through a way of THINKING." Each module has sub-components derived from the story elements. We can specify the required aspects of understanding by annotating the sub-components to individual questions. CogME thus provides a framework for an elaborated specification of VideoQA datasets. To examine the suitability of a VideoQA dataset for validating video understanding intelligence, we evaluated the baseline model of the DramaQA dataset by applying CogME. The evaluation reveals that story elements are unevenly reflected in the existing dataset, and the model based on the dataset may cause biased predictions. Although this study has only been able to grasp a narrow range of stories, we expect that it offers the first step in considering the cognitive process of humans on the video understanding intelligence of humans and AI.