 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Coordinate-based Convolutional Kernels for Continuous SE(3) Equivariant and Efficient Point Cloud Analysis
Mar 18, 2026A symmetry on rigid motion is one of the salient factors in efficient learning of 3D point cloud problems. Group convolution has been a representative method to extract equivariant features, but its realizations have struggled to retain both rigorous symmetry and scalability simultaneously. We advocate utilizing the intertwiner framework to resolve this trade-off, but previous works on it, which did not achieve complete SE(3) symmetry or scalability to large-scale problems, necessitate a more advanced kernel architecture. We present Equivariant Coordinate-based Kernel Convolution, or ECKConv. It acquires SE(3) equivariance from the kernel domain defined in a double coset space, and its explicit kernel design using coordinate-based networks enhances its learning capability and memory efficiency. The experiments on diverse point cloud tasks, e.g., classification, pose registration, part segmentation, and large-scale semantic segmentation, validate the rigid equivariance, memory scalability, and outstanding performance of ECKConv compared to state-of-the-art equivariant methods.
Voronoi-based Second-order Descriptor with Whitened Metric in LiDAR Place Recognition
Mar 16, 2026The pooling layer plays a vital role in aggregating local descriptors into the metrizable global descriptor in the LiDAR Place Recognition (LPR). In particular, the second-order pooling is capable of capturing higher-order interactions among local descriptors. However, its existing methods in the LPR adhere to conventional implementations and post-normalization, and incur the descriptor unsuitable for Euclidean distancing. Based on the recent interpretation that associates NetVLAD with the second-order statistics, we propose to integrate second-order pooling with the inductive bias from Voronoi cells. Our novel pooling method aggregates local descriptors to form the second-order matrix and whitens the global descriptor to implicitly measure the Mahalanobis distance while conserving the cluster property from Voronoi cells, addressing its numerical instability during learning with diverse techniques. We demonstrate its performance gains through the experiments conducted on the Oxford Robotcar and Wild-Places benchmarks and analyze the numerical effect of the proposed whitening algorithm.
ESPADA: Execution Speedup via Semantics Aware Demonstration Data Downsampling for Imitation Learning
Dec 15, 2025Behavior-cloning based visuomotor policies enable precise manipulation but often inherit the slow, cautious tempo of human demonstrations, limiting practical deployment. However, prior studies on acceleration methods mainly rely on statistical or heuristic cues that ignore task semantics and can fail across diverse manipulation settings. We present ESPADA, a semantic and spatially aware framework that segments demonstrations using a VLM-LLM pipeline with 3D gripper-object relations, enabling aggressive downsampling only in non-critical segments while preserving precision-critical phases, without requiring extra data or architectural modifications, or any form of retraining. To scale from a single annotated episode to the full dataset, ESPADA propagates segment labels via Dynamic Time Warping (DTW) on dynamics-only features. Across both simulation and real-world experiments with ACT and DP baselines, ESPADA achieves approximately a 2x speed-up while maintaining success rates, narrowing the gap between human demonstrations and efficient robot control.
EgoExo-Con: Exploring View-Invariant Video Temporal Understanding
Oct 30, 2025Can Video-LLMs achieve consistent temporal understanding when videos capture the same event from different viewpoints? To study this, we introduce EgoExo-Con (Consistency), a benchmark of comprehensively synchronized egocentric and exocentric video pairs with human-refined queries in natural language. EgoExo-Con emphasizes two temporal understanding tasks: Temporal Verification and Temporal Grounding. It evaluates not only correctness but consistency across viewpoints. Our analysis reveals two critical limitations of existing Video-LLMs: (1) models often fail to maintain consistency, with results far worse than their single-view performances. (2) When naively finetuned with synchronized videos of both viewpoints, the models show improved consistency but often underperform those trained on a single view. For improvements, we propose View-GRPO, a novel reinforcement learning framework that effectively strengthens view-specific temporal reasoning while encouraging consistent comprehension across viewpoints. Our method demonstrates its superiority over naive SFT and GRPO, especially for improving cross-view consistency. All resources will be made publicly available.
Locality-aware Concept Bottleneck Model
Aug 20, 2025Concept bottleneck models (CBMs) are inherently interpretable models that make predictions based on human-understandable visual cues, referred to as concepts. As obtaining dense concept annotations with human labeling is demanding and costly, recent approaches utilize foundation models to determine the concepts existing in the images. However, such label-free CBMs often fail to localize concepts in relevant regions, attending to visually unrelated regions when predicting concept presence. To this end, we propose a framework, coined Locality-aware Concept Bottleneck Model (LCBM), which utilizes rich information from foundation models and adopts prototype learning to ensure accurate spatial localization of the concepts. Specifically, we assign one prototype to each concept, promoted to represent a prototypical image feature of that concept. These prototypes are learned by encouraging them to encode similar local regions, leveraging foundation models to assure the relevance of each prototype to its associated concept. Then we use the prototypes to facilitate the learning process of identifying the proper local region from which each concept should be predicted. Experimental results demonstrate that LCBM effectively identifies present concepts in the images and exhibits improved localization while maintaining comparable classification performance.
Towards Spatially Consistent Image Generation: On Incorporating Intrinsic Scene Properties into Diffusion Models
Aug 14, 2025Image generation models trained on large datasets can synthesize high-quality images but often produce spatially inconsistent and distorted images due to limited information about the underlying structures and spatial layouts. In this work, we leverage intrinsic scene properties (e.g., depth, segmentation maps) that provide rich information about the underlying scene, unlike prior approaches that solely rely on image-text pairs or use intrinsics as conditional inputs. Our approach aims to co-generate both images and their corresponding intrinsics, enabling the model to implicitly capture the underlying scene structure and generate more spatially consistent and realistic images. Specifically, we first extract rich intrinsic scene properties from a large image dataset with pre-trained estimators, eliminating the need for additional scene information or explicit 3D representations. We then aggregate various intrinsic scene properties into a single latent variable using an autoencoder. Building upon pre-trained large-scale Latent Diffusion Models (LDMs), our method simultaneously denoises the image and intrinsic domains by carefully sharing mutual information so that the image and intrinsic reflect each other without degrading image quality. Experimental results demonstrate that our method corrects spatial inconsistencies and produces a more natural layout of scenes while maintaining the fidelity and textual alignment of the base model (e.g., Stable Diffusion).
DBMovi-GS: Dynamic View Synthesis from Blurry Monocular Video via Sparse-Controlled Gaussian Splatting
Jun 26, 2025Novel view synthesis is a task of generating scenes from unseen perspectives; however, synthesizing dynamic scenes from blurry monocular videos remains an unresolved challenge that has yet to be effectively addressed. Existing novel view synthesis methods are often constrained by their reliance on high-resolution images or strong assumptions about static geometry and rigid scene priors. Consequently, their approaches lack robustness in real-world environments with dynamic object and camera motion, leading to instability and degraded visual fidelity. To address this, we propose Motion-aware Dynamic View Synthesis from Blurry Monocular Video via Sparse-Controlled Gaussian Splatting (DBMovi-GS), a method designed for dynamic view synthesis from blurry monocular videos. Our model generates dense 3D Gaussians, restoring sharpness from blurry videos and reconstructing detailed 3D geometry of the scene affected by dynamic motion variations. Our model achieves robust performance in novel view synthesis under dynamic blurry scenes and sets a new benchmark in realistic novel view synthesis for blurry monocular video inputs.
OV-MAP : Open-Vocabulary Zero-Shot 3D Instance Segmentation Map for Robots
Jun 13, 2025



We introduce OV-MAP, a novel approach to open-world 3D mapping for mobile robots by integrating open-features into 3D maps to enhance object recognition capabilities. A significant challenge arises when overlapping features from adjacent voxels reduce instance-level precision, as features spill over voxel boundaries, blending neighboring regions together. Our method overcomes this by employing a class-agnostic segmentation model to project 2D masks into 3D space, combined with a supplemented depth image created by merging raw and synthetic depth from point clouds. This approach, along with a 3D mask voting mechanism, enables accurate zero-shot 3D instance segmentation without relying on 3D supervised segmentation models. We assess the effectiveness of our method through comprehensive experiments on public datasets such as ScanNet200 and Replica, demonstrating superior zero-shot performance, robustness, and adaptability across diverse environments. Additionally, we conducted real-world experiments to demonstrate our method's adaptability and robustness when applied to diverse real-world environments.
Exploring Ordinal Bias in Action Recognition for Instructional Videos
Apr 09, 2025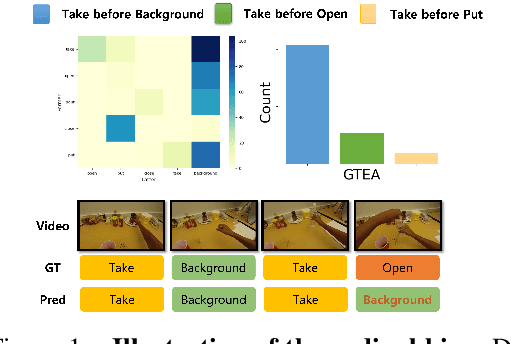

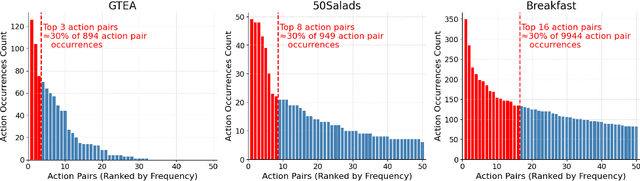

Action recognition models have achieved promising results in understanding instructional videos. However, they often rely on dominant, dataset-specific action sequences rather than true video comprehension, a problem that we define as ordinal bias. To address this issue, we propose two effective video manipulation methods: Action Masking, which masks frames of frequently co-occurring actions, and Sequence Shuffling, which randomizes the order of action segments. Through comprehensive experiments, we demonstrate that current models exhibit significant performance drops when confronted with nonstandard action sequences, underscoring their vulnerability to ordinal bias. Our findings emphasize the importance of rethinking evaluation strategies and developing models capable of generalizing beyond fixed action patterns in diverse instructional videos.
Variational Online Mirror Descent for Robust Learning in Schrödinger Bridge
Apr 03, 2025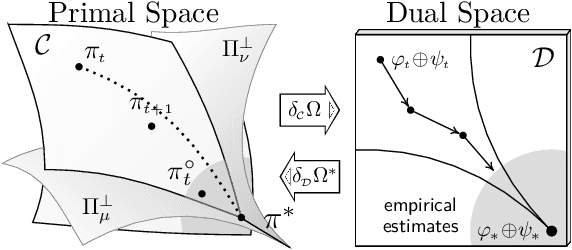

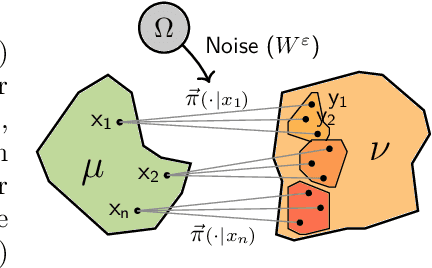
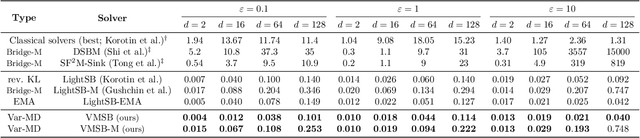
Sch\"odinger bridge (SB) has evolved into a universal class of probabilistic generative models. In practice, however, estimated learning signals are often uncertain, and the reliability promised by existing methods is often based on speculative optimal-case scenarios. Recent studies regarding the Sinkhorn algorithm through mirror descent (MD) have gained attention, revealing geometric insights into solution acquisition of the SB problems. In this paper, we propose a variational online MD (OMD) framework for the SB problems, which provides further stability to SB solvers. We formally prove convergence and a regret bound for the novel OMD formulation of SB acquisition. As a result, we propose a simulation-free SB algorithm called Variational Mirrored Schr\"odinger Bridge (VMSB) by utilizing the Wasserstein-Fisher-Rao geometry of the Gaussian mixture parameterization for Schr\"odinger potentials. Based on the Wasserstein gradient flow theory, the algorithm offers tractable learning dynamics that precisely approximate each OMD step. In experiments, we validate the performance of the proposed VMSB algorithm across an extensive suite of benchmarks. VMSB consistently outperforms contemporary SB solvers on a range of SB problems, demonstrating the robustness predicted by our theory.