 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Length Bias in RLHF through a Causal Lens
Nov 16, 2025Reinforcement learning from human feedback (RLHF) is widely used to align large language models (LLMs) with human preferences. However, RLHF-trained reward models often exhibit length bias -- a systematic tendency to favor longer responses by conflating verbosity with quality. We propose a causal framework for analyzing and mitigating length bias in RLHF reward modeling. Central to our approach is a counterfactual data augmentation method that generates response pairs designed to isolate content quality from verbosity. These counterfactual examples are then used to train the reward model, enabling it to assess responses based on content quality independently of verbosity. Specifically, we construct (1) length-divergent pairs with similar content and (2) content-divergent pairs of similar length. Empirical evaluations show that our method reduces length bias in reward assignment and leads to more concise, content-focused outputs from the policy model. These findings demonstrate that the proposed approach effectively reduces length bias and improves the robustness and content sensitivity of reward modeling in RLHF pipelines.
On Predicting Post-Click Conversion Rate via Counterfactual Inference
Oct 06, 2025
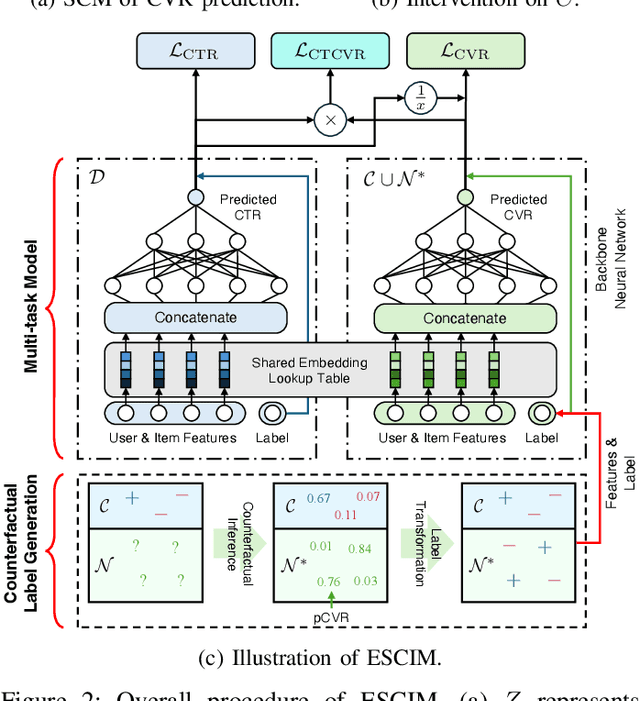
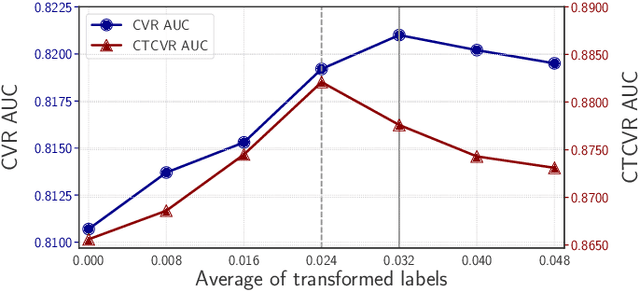
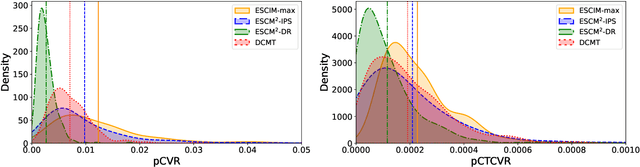
Accurately predicting conversion rate (CVR) is essential in various recommendation domains such as online advertising systems and e-commerce. These systems utilize user interaction logs, which consist of exposures, clicks, and conversions. CVR prediction models are typically trained solely based on clicked samples, as conversions can only be determined following clicks. However, the sparsity of clicked instances necessitates the collection of a substantial amount of logs for effective model training. Recent works address this issue by devising frameworks that leverage non-clicked samples. While these frameworks aim to reduce biases caused by the discrepancy between clicked and non-clicked samples, they often rely on heuristics. Against this background, we propose a method to counterfactually generate conversion labels for non-clicked samples by using causality as a guiding principle, attempting to answer the question, "Would the user have converted if he or she had clicked the recommended item?" Our approach is named the Entire Space Counterfactual Inference Multi-task Model (ESCIM). We initially train a structural causal model (SCM) of user sequential behaviors and conduct a hypothetical intervention (i.e., click) on non-clicked items to infer counterfactual CVRs. We then introduce several approaches to transform predicted counterfactual CVRs into binary counterfactual conversion labels for the non-clicked samples. Finally, the generated samples are incorporated into the training process. Extensive experiments on public datasets illustrate the superiority of the proposed algorithm. Online A/B testing further empirically validates the effectiveness of our proposed algorithm in real-world scenarios. In addition, we demonstrate the improved performance of the proposed method on latent conversion data, showcasing its robustness and superior generalization capabilities.
Locality-aware Concept Bottleneck Model
Aug 20, 2025Concept bottleneck models (CBMs) are inherently interpretable models that make predictions based on human-understandable visual cues, referred to as concepts. As obtaining dense concept annotations with human labeling is demanding and costly, recent approaches utilize foundation models to determine the concepts existing in the images. However, such label-free CBMs often fail to localize concepts in relevant regions, attending to visually unrelated regions when predicting concept presence. To this end, we propose a framework, coined Locality-aware Concept Bottleneck Model (LCBM), which utilizes rich information from foundation models and adopts prototype learning to ensure accurate spatial localization of the concepts. Specifically, we assign one prototype to each concept, promoted to represent a prototypical image feature of that concept. These prototypes are learned by encouraging them to encode similar local regions, leveraging foundation models to assure the relevance of each prototype to its associated concept. Then we use the prototypes to facilitate the learning process of identifying the proper local region from which each concept should be predicted. Experimental results demonstrate that LCBM effectively identifies present concepts in the images and exhibits improved localization while maintaining comparable classification performance.
PEER pressure: Model-to-Model Regularization for Single Source Domain Generalization
May 19, 2025Data augmentation is a popular tool for single source domain generalization, which expands the source domain by generating simulated ones, improving generalization on unseen target domains. In this work, we show that the performance of such augmentation-based methods in the target domains universally fluctuates during training, posing challenges in model selection under realistic scenarios. We argue that the fluctuation stems from the inability of the model to accumulate the knowledge learned from diverse augmentations, exacerbating feature distortion during training. Based on this observation, we propose a novel generalization method, coined Parameter-Space Ensemble with Entropy Regularization (PEER), that uses a proxy model to learn the augmented data on behalf of the main model. The main model is updated by averaging its parameters with the proxy model, progressively accumulating knowledge over the training steps. Maximizing the mutual information between the output representations of the two models guides the learning process of the proxy model, mitigating feature distortion during training. Experimental results demonstrate the effectiveness of PEER in reducing the OOD performance fluctuation and enhancing generalization across various datasets, including PACS, Digits, Office-Home, and VLCS. Notably, our method with simple random augmentation achieves state-of-the-art performance, surpassing prior approaches on sDG that utilize complex data augmentation strategies.
Fine-Grained Causal Dynamics Learning with Quantization for Improving Robustness in Reinforcement Learning
Jun 05, 2024Causal dynamics learning has recently emerged as a promising approach to enhancing robustness in reinforcement learning (RL). Typically, the goal is to build a dynamics model that makes predictions based on the causal relationships among the entities. Despite the fact that causal connections often manifest only under certain contexts, existing approaches overlook such fine-grained relationships and lack a detailed understanding of the dynamics. In this work, we propose a novel dynamics model that infers fine-grained causal structures and employs them for prediction, leading to improved robustness in RL. The key idea is to jointly learn the dynamics model with a discrete latent variable that quantizes the state-action space into subgroups. This leads to recognizing meaningful context that displays sparse dependencies, where causal structures are learned for each subgroup throughout the training. Experimental results demonstrate the robustness of our method to unseen states and locally spurious correlations in downstream tasks where fine-grained causal reasoning is crucial. We further illustrate the effectiveness of our subgroup-based approach with quantization in discovering fine-grained causal relationships compared to prior methods.
Efficient Monte Carlo Tree Search via On-the-Fly State-Conditioned Action Abstraction
Jun 02, 2024Monte Carlo Tree Search (MCTS) has showcased its efficacy across a broad spectrum of decision-making problems. However, its performance often degrades under vast combinatorial action space, especially where an action is composed of multiple sub-actions. In this work, we propose an action abstraction based on the compositional structure between a state and sub-actions for improving the efficiency of MCTS under a factored action space. Our method learns a latent dynamics model with an auxiliary network that captures sub-actions relevant to the transition on the current state, which we call state-conditioned action abstraction. Notably, it infers such compositional relationships from high-dimensional observations without the known environment model. During the tree traversal, our method constructs the state-conditioned action abstraction for each node on-the-fly, reducing the search space by discarding the exploration of redundant sub-actions. Experimental results demonstrate the superior sample efficiency of our method compared to vanilla MuZero, which suffers from expansive action space.
On Discovery of Local Independence over Continuous Variables via Neural Contextual Decomposition
May 12, 2024Conditional independence provides a way to understand causal relationships among the variables of interest. An underlying system may exhibit more fine-grained causal relationships especially between a variable and its parents, which will be called the local independence relationships. One of the most widely studied local relationships is Context-Specific Independence (CSI), which holds in a specific assignment of conditioned variables. However, its applicability is often limited since it does not allow continuous variables: data conditioned to the specific value of a continuous variable contains few instances, if not none, making it infeasible to test independence. In this work, we define and characterize the local independence relationship that holds in a specific set of joint assignments of parental variables, which we call context-set specific independence (CSSI). We then provide a canonical representation of CSSI and prove its fundamental properties. Based on our theoretical findings, we cast the problem of discovering multiple CSSI relationships in a system as finding a partition of the joint outcome space. Finally, we propose a novel method, coined neural contextual decomposition (NCD), which learns such partition by imposing each set to induce CSSI via modeling a conditional distribution. We empirically demonstrate that the proposed method successfully discovers the ground truth local independence relationships in both synthetic dataset and complex system reflecting the real-world physical dynamics.
Can We Utilize Pre-trained Language Models within Causal Discovery Algorithms?
Nov 19, 2023Scaling laws have allowed Pre-trained Language Models (PLMs) into the field of causal reasoning. Causal reasoning of PLM relies solely on text-based descriptions, in contrast to causal discovery which aims to determine the causal relationships between variables utilizing data. Recently, there has been current research regarding a method that mimics causal discovery by aggregating the outcomes of repetitive causal reasoning, achieved through specifically designed prompts. It highlights the usefulness of PLMs in discovering cause and effect, which is often limited by a lack of data, especially when dealing with multiple variables. Conversely, the characteristics of PLMs which are that PLMs do not analyze data and they are highly dependent on prompt design leads to a crucial limitation for directly using PLMs in causal discovery. Accordingly, PLM-based causal reasoning deeply depends on the prompt design and carries out the risk of overconfidence and false predictions in determining causal relationships. In this paper, we empirically demonstrate the aforementioned limitations of PLM-based causal reasoning through experiments on physics-inspired synthetic data. Then, we propose a new framework that integrates prior knowledge obtained from PLM with a causal discovery algorithm. This is accomplished by initializing an adjacency matrix for causal discovery and incorporating regularization using prior knowledge. Our proposed framework not only demonstrates improved performance through the integration of PLM and causal discovery but also suggests how to leverage PLM-extracted prior knowledge with existing causal discovery algorithms.
Nested Counterfactual Identification from Arbitrary Surrogate Experiments
Jul 07, 2021



The Ladder of Causation describes three qualitatively different types of activities an agent may be interested in engaging in, namely, seeing (observational), doing (interventional), and imagining (counterfactual) (Pearl and Mackenzie, 2018). The inferential challenge imposed by the causal hierarchy is that data is collected by an agent observing or intervening in a system (layers 1 and 2), while its goal may be to understand what would have happened had it taken a different course of action, contrary to what factually ended up happening (layer 3). While there exists a solid understanding of the conditions under which cross-layer inferences are allowed from observations to interventions, the results are somewhat scarcer when targeting counterfactual quantities. In this paper, we study the identification of nested counterfactuals from an arbitrary combination of observations and experiments. Specifically, building on a more explicit definition of nested counterfactuals, we prove the counterfactual unnesting theorem (CUT), which allows one to map arbitrary nested counterfactuals to unnested ones. For instance, applications in mediation and fairness analysis usually evoke notions of direct, indirect, and spurious effects, which naturally require nesting. Second, we introduce a sufficient and necessary graphical condition for counterfactual identification from an arbitrary combination of observational and experimental distributions. Lastly, we develop an efficient and complete algorithm for identifying nested counterfactuals; failure of the algorithm returning an expression for a query implies it is not identifiable.
Towards Robust Relational Causal Discovery
Dec 05, 2019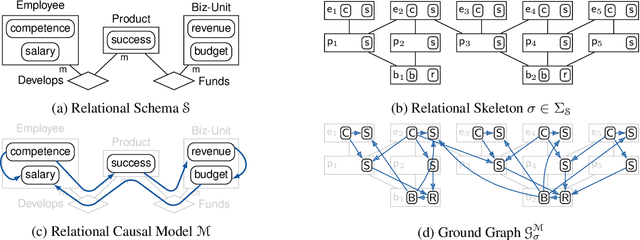
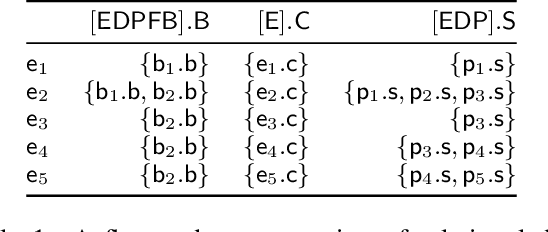

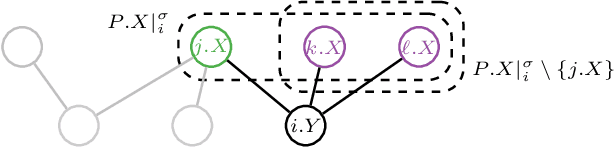
We consider the problem of learning causal relationships from relational data. Existing approaches rely on queries to a relational conditional independence (RCI) oracle to establish and orient causal relations in such a setting. In practice, queries to a RCI oracle have to be replaced by reliable tests for RCI against available data. Relational data present several unique challenges in testing for RCI. We study the conditions under which traditional iid-based conditional independence (CI) tests yield reliable answers to RCI queries against relational data. We show how to conduct CI tests against relational data to robustly recover the underlying relational causal structure. Results of our experiments demonstrate the effectiveness of our proposed approach.
* 14 pages