 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Monitoring and Robustness of In-Use Machine Learning Models: Quantifying Data Distribution Shifts Using Population Stability Index
Feb 01, 2023


Safety goes first. Meeting and maintaining industry safety standards for robustness of artificial intelligence (AI) and machine learning (ML) models require continuous monitoring for faults and performance drops. Deep learning models are widely used in industrial applications, e.g., computer vision, but the susceptibility of their performance to environment changes (e.g., noise) \emph{after deployment} on the product, are now well-known. A major challenge is detecting data distribution shifts that happen, comparing the following: {\bf (i)} development stage of AI and ML models, i.e., train/validation/test, to {\bf (ii)} deployment stage on the product (i.e., even after `testing') in the environment. We focus on a computer vision example related to autonomous driving and aim at detecting shifts that occur as a result of adding noise to images. We use the population stability index (PSI) as a measure of presence and intensity of shift and present results of our empirical experiments showing a promising potential for the PSI. We further discuss multiple aspects of model monitoring and robustness that need to be analyzed \emph{simultaneously} to achieve robustness for industry safety standards. We propose the need for and the research direction toward \emph{categorizations} of problem classes and examples where monitoring for robustness is required and present challenges and pointers for future work from a \emph{practical} perspective.
Commuting Network Spillovers and COVID-19 Deaths Across US Counties
Oct 02, 2020
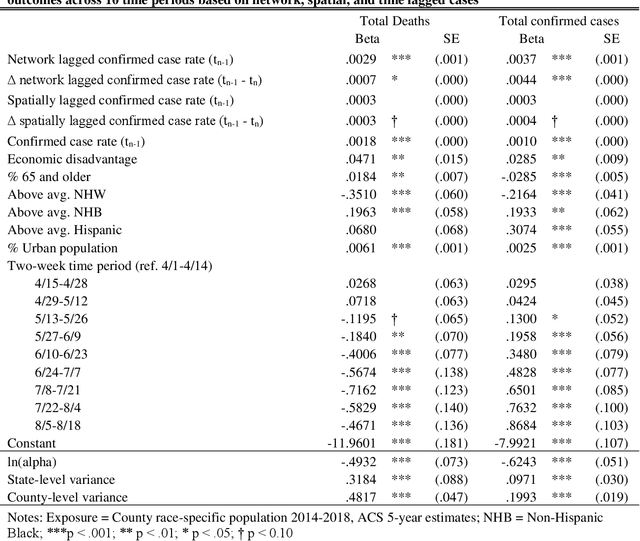
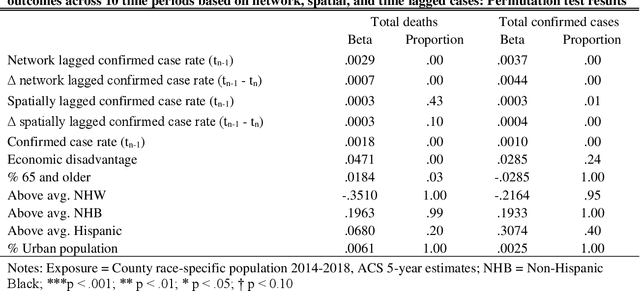
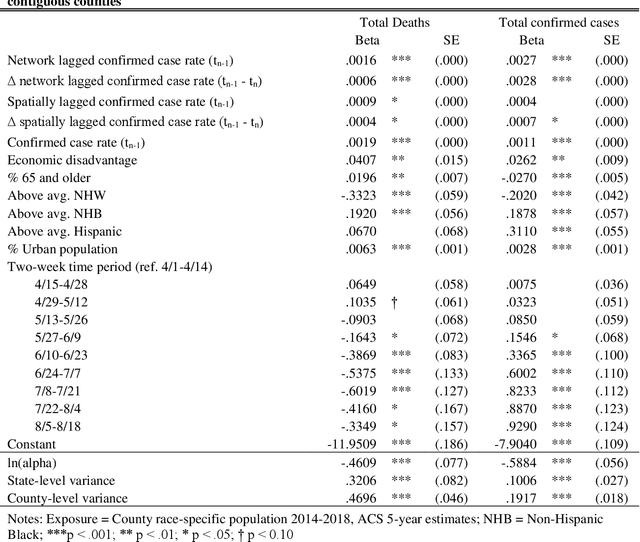
This study explored how population mobility flows form commuting networks across US counties and influence the spread of COVID-19. We utilized 3-level mixed effects negative binomial regression models to estimate the impact of network COVID-19 exposure on county confirmed cases and deaths over time. We also conducted weighting-based analyses to estimate the causal effect of network exposure. Results showed that commuting networks matter for COVID-19 deaths and cases, net of spatial proximity, socioeconomic, and demographic factors. Different local racial and ethnic concentrations are also associated with unequal outcomes. These findings suggest that commuting is an important causal mechanism in the spread of COVID-19 and highlight the significance of interconnected of communities. The results suggest that local level mitigation and prevention efforts are more effective when complemented by similar efforts in the network of connected places. Implications for research on inequality in health and flexible work arrangements are discussed.
A Causal Lens for Peeking into Black Box Predictive Models: Predictive Model Interpretation via Causal Attribution
Aug 01, 2020


With the increasing adoption of predictive models trained using machine learning across a wide range of high-stakes applications, e.g., health care, security, criminal justice, finance, and education, there is a growing need for effective techniques for explaining such models and their predictions. We aim to address this problem in settings where the predictive model is a black box; That is, we can only observe the response of the model to various inputs, but have no knowledge about the internal structure of the predictive model, its parameters, the objective function, and the algorithm used to optimize the model. We reduce the problem of interpreting a black box predictive model to that of estimating the causal effects of each of the model inputs on the model output, from observations of the model inputs and the corresponding outputs. We estimate the causal effects of model inputs on model output using variants of the Rubin Neyman potential outcomes framework for estimating causal effects from observational data. We show how the resulting causal attribution of responsibility for model output to the different model inputs can be used to interpret the predictive model and to explain its predictions. We present results of experiments that demonstrate the effectiveness of our approach to the interpretation of black box predictive models via causal attribution in the case of deep neural network models trained on one synthetic data set (where the input variables that impact the output variable are known by design) and two real-world data sets: Handwritten digit classification, and Parkinson's disease severity prediction. Because our approach does not require knowledge about the predictive model algorithm and is free of assumptions regarding the black box predictive model except that its input-output responses be observable, it can be applied, in principle, to any black box predictive model.
Algorithmic Bias in Recidivism Prediction: A Causal Perspective
Nov 24, 2019

ProPublica's analysis of recidivism predictions produced by Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) software tool for the task, has shown that the predictions were racially biased against African American defendants. We analyze the COMPAS data using a causal reformulation of the underlying algorithmic fairness problem. Specifically, we assess whether COMPAS exhibits racial bias against African American defendants using FACT, a recently introduced causality grounded measure of algorithmic fairness. We use the Neyman-Rubin potential outcomes framework for causal inference from observational data to estimate FACT from COMPAS data. Our analysis offers strong evidence that COMPAS exhibits racial bias against African American defendants. We further show that the FACT estimates from COMPAS data are robust in the presence of unmeasured confounding.
Fairness in Algorithmic Decision Making: An Excursion Through the Lens of Causality
Mar 27, 2019


As virtually all aspects of our lives are increasingly impacted by algorithmic decision making systems, it is incumbent upon us as a society to ensure such systems do not become instruments of unfair discrimination on the basis of gender, race, ethnicity, religion, etc. We consider the problem of determining whether the decisions made by such systems are discriminatory, through the lens of causal models. We introduce two definitions of group fairness grounded in causality: fair on average causal effect (FACE), and fair on average causal effect on the treated (FACT). We use the Rubin-Neyman potential outcomes framework for the analysis of cause-effect relationships to robustly estimate FACE and FACT. We demonstrate the effectiveness of our proposed approach on synthetic data. Our analyses of two real-world data sets, the Adult income data set from the UCI repository (with gender as the protected attribute), and the NYC Stop and Frisk data set (with race as the protected attribute), show that the evidence of discrimination obtained by FACE and FACT, or lack thereof, is often in agreement with the findings from other studies. We further show that FACT, being somewhat more nuanced compared to FACE, can yield findings of discrimination that differ from those obtained using FACE.