 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBMovi-GS: Dynamic View Synthesis from Blurry Monocular Video via Sparse-Controlled Gaussian Splatting
Jun 26, 2025Novel view synthesis is a task of generating scenes from unseen perspectives; however, synthesizing dynamic scenes from blurry monocular videos remains an unresolved challenge that has yet to be effectively addressed. Existing novel view synthesis methods are often constrained by their reliance on high-resolution images or strong assumptions about static geometry and rigid scene priors. Consequently, their approaches lack robustness in real-world environments with dynamic object and camera motion, leading to instability and degraded visual fidelity. To address this, we propose Motion-aware Dynamic View Synthesis from Blurry Monocular Video via Sparse-Controlled Gaussian Splatting (DBMovi-GS), a method designed for dynamic view synthesis from blurry monocular videos. Our model generates dense 3D Gaussians, restoring sharpness from blurry videos and reconstructing detailed 3D geometry of the scene affected by dynamic motion variations. Our model achieves robust performance in novel view synthesis under dynamic blurry scenes and sets a new benchmark in realistic novel view synthesis for blurry monocular video inputs.
Variational Online Mirror Descent for Robust Learning in Schrödinger Bridge
Apr 03, 2025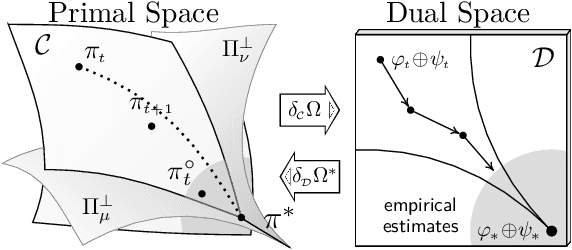

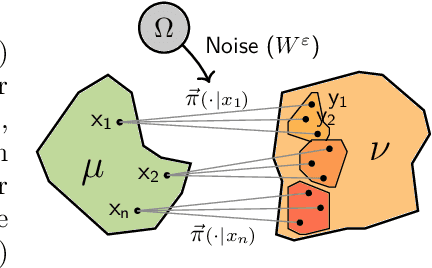
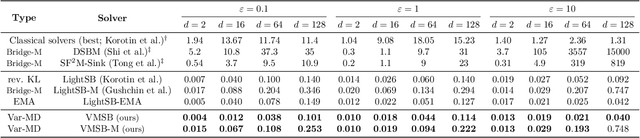
Sch\"odinger bridge (SB) has evolved into a universal class of probabilistic generative models. In practice, however, estimated learning signals are often uncertain, and the reliability promised by existing methods is often based on speculative optimal-case scenarios. Recent studies regarding the Sinkhorn algorithm through mirror descent (MD) have gained attention, revealing geometric insights into solution acquisition of the SB problems. In this paper, we propose a variational online MD (OMD) framework for the SB problems, which provides further stability to SB solvers. We formally prove convergence and a regret bound for the novel OMD formulation of SB acquisition. As a result, we propose a simulation-free SB algorithm called Variational Mirrored Schr\"odinger Bridge (VMSB) by utilizing the Wasserstein-Fisher-Rao geometry of the Gaussian mixture parameterization for Schr\"odinger potentials. Based on the Wasserstein gradient flow theory, the algorithm offers tractable learning dynamics that precisely approximate each OMD step. In experiments, we validate the performance of the proposed VMSB algorithm across an extensive suite of benchmarks. VMSB consistently outperforms contemporary SB solvers on a range of SB problems, demonstrating the robustness predicted by our theory.
Tool-Assisted Agent on SQL Inspection and Refinement in Real-World Scenarios
Aug 30, 2024Recent Text-to-SQL methods leverage large language models (LLMs) by incorporating feedback from the database management system. While these methods effectively address execution errors in SQL queries, they struggle with database mismatches -- errors that do not trigger execution exceptions. Database mismatches include issues such as condition mismatches and stricter constraint mismatches, both of which are more prevalent in real-world scenarios. To address these challenges, we propose a tool-assisted agent framework for SQL inspection and refinement, equipping the LLM-based agent with two specialized tools: a retriever and a detector, designed to diagnose and correct SQL queries with database mismatches. These tools enhance the capability of LLMs to handle real-world queries more effectively. We also introduce Spider-Mismatch, a new dataset specifically constructed to reflect the condition mismatch problems encountered in real-world scenarios. Experimental results demonstrate that our method achieves the highest performance on the averaged results of the Spider and Spider-Realistic datasets in few-shot settings, and it significantly outperforms baseline methods on the more realistic dataset, Spider-Mismatch.
Progressively Modality Freezing for Multi-Modal Entity Alignment
Jul 23, 2024



Multi-Modal Entity Alignment aims to discover identical entities across heterogeneous knowledge graphs. While recent studies have delved into fusion paradigms to represent entities holistically, the elimination of features irrelevant to alignment and modal inconsistencies is overlooked, which are caused by inherent differences in multi-modal features. To address these challenges, we propose a novel strategy of progressive modality freezing, called PMF, that focuses on alignmentrelevant features and enhances multi-modal feature fusion. Notably, our approach introduces a pioneering cross-modal association loss to foster modal consistency. Empirical evaluations across nine datasets confirm PMF's superiority, demonstrating stateof-the-art performance and the rationale for freezing modalities. Our code is available at https://github.com/ninibymilk/PMF-MMEA.
Unsupervised Dynamics Prediction with Object-Centric Kinematics
Apr 29, 2024Human perception involves discerning complex multi-object scenes into time-static object appearance (\ie, size, shape, color) and time-varying object motion (\ie, location, velocity, acceleration). This innate ability to unconsciously understand the environment is the motivation behind the success of dynamics modeling. Object-centric representations have emerged as a promising tool for dynamics prediction, yet they primarily focus on the objects' appearance, often overlooking other crucial attributes. In this paper, we propose Object-Centric Kinematics (OCK), a framework for dynamics prediction leveraging object-centric representations. Our model utilizes a novel component named object kinematics, which comprises low-level structured states of objects' position, velocity, and acceleration. The object kinematics are obtained via either implicit or explicit approaches, enabling comprehensive spatiotemporal object reasoning, and integrated through various transformer mechanisms, facilitating effective object-centric dynamics modeling. Our model demonstrates superior performance when handling objects and backgrounds in complex scenes characterized by a wide range of object attributes and dynamic movements. Moreover, our model demonstrates generalization capabilities across diverse synthetic environments, highlighting its potential for broad applicability in vision-related tasks.
Anaphor Assisted Document-Level Relation Extraction
Oct 28, 2023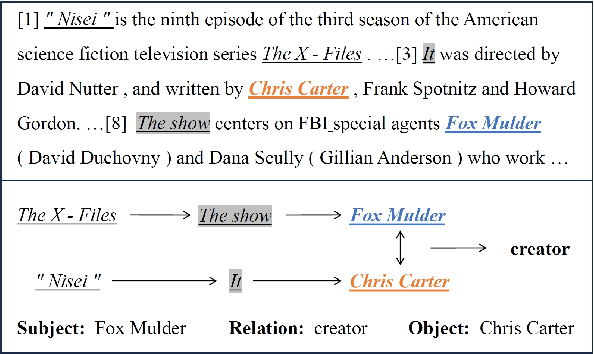
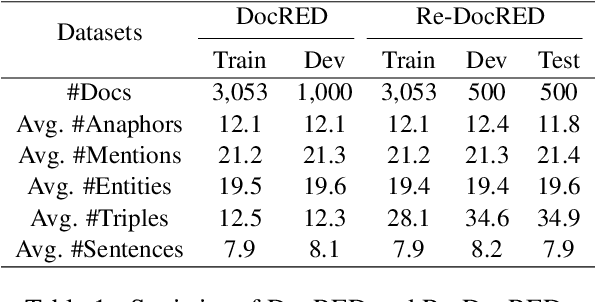

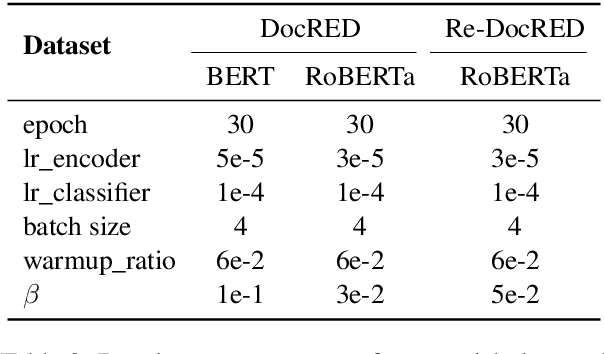
Document-level relation extraction (DocRE) involves identifying relations between entities distributed in multiple sentences within a document. Existing methods focus on building a heterogeneous document graph to model the internal structure of an entity and the external interaction between entities. However, there are two drawbacks in existing methods. On one hand, anaphor plays an important role in reasoning to identify relations between entities but is ignored by these methods. On the other hand, these methods achieve cross-sentence entity interactions implicitly by utilizing a document or sentences as intermediate nodes. Such an approach has difficulties in learning fine-grained interactions between entities across different sentences, resulting in sub-optimal performance. To address these issues, we propose an Anaphor-Assisted (AA) framework for DocRE tasks. Experimental results on the widely-used datasets demonstrate that our model achieves a new state-of-the-art performance.
PGA: Personalizing Grasping Agents with Single Human-Robot Interaction
Oct 19, 2023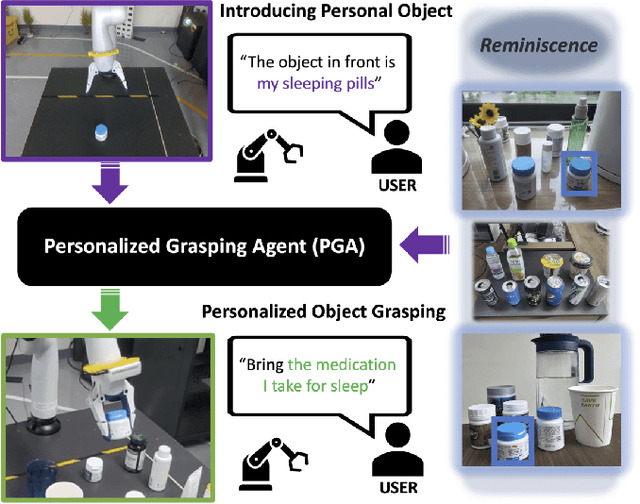
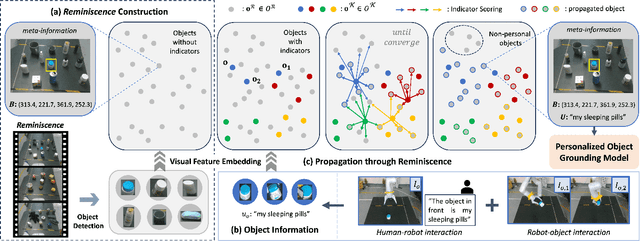
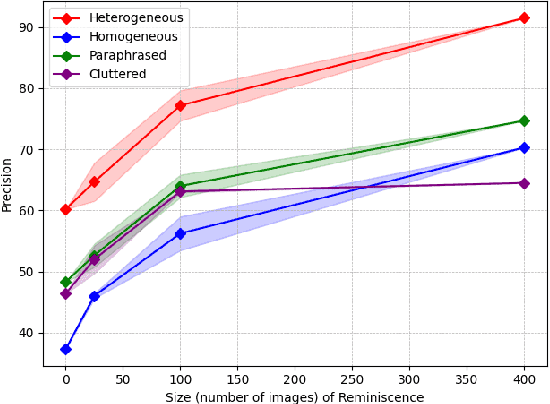
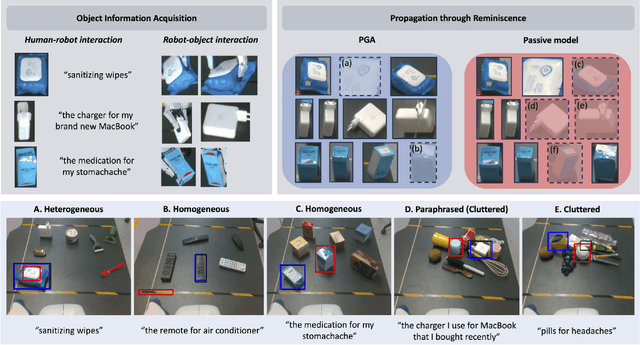
Language-Conditioned Robotic Grasping (LCRG) aims to develop robots that ground and grasp objects based on natural language instructions. While robots capable of recognizing personal objects like "my wallet" can interact more naturally with non-expert users, current LCRG systems primarily limit robots to understanding only generic expressions. To this end, we introduce a task scenario GraspMine with a novel dataset that aims to locate and grasp personal objects given personal indicators via learning from a single human-robot interaction. To address GraspMine, we propose Personalized Grasping Agent (PGA), that learns personal objects by propagating user-given information through a Reminiscence-a collection of raw images from the user's environment. Specifically, PGA acquires personal object information by a user presenting a personal object with its associated indicator, followed by PGA inspecting the object by rotating it. Based on the acquired information, PGA pseudo-labels objects in the Reminiscence by our proposed label propagation algorithm. Harnessing the information acquired from the interactions and the pseudo-labeled objects in the Reminiscence, PGA adapts the object grounding model to grasp personal objects. Experiments on GraspMine show that PGA significantly outperforms baseline methods both in offline and online settings, signifying its effectiveness and personalization applicability on real-world scenarios. Finally, qualitative analysis shows the effectiveness of PGA through a detailed investigation of results in each phase.
PROGrasp: Pragmatic Human-Robot Communication for Object Grasping
Sep 14, 2023



Interactive Object Grasping (IOG) is the task of identifying and grasping the desired object via human-robot natural language interaction. Current IOG systems assume that a human user initially specifies the target object's category (e.g., bottle). Inspired by pragmatics, where humans often convey their intentions by relying on context to achieve goals, we introduce a new IOG task, Pragmatic-IOG, and the corresponding dataset, Intention-oriented Multi-modal Dialogue (IM-Dial). In our proposed task scenario, an intention-oriented utterance (e.g., "I am thirsty") is initially given to the robot. The robot should then identify the target object by interacting with a human user. Based on the task setup, we propose a new robotic system that can interpret the user's intention and pick up the target object, Pragmatic Object Grasping (PROGrasp). PROGrasp performs Pragmatic-IOG by incorporating modules for visual grounding, question asking, object grasping, and most importantly, answer interpretation for pragmatic inference. Experimental results show that PROGrasp is effective in offline (i.e., target object discovery) and online (i.e., IOG with a physical robot arm) settings.
GVCCI: Lifelong Learning of Visual Grounding for Language-Guided Robotic Manipulation
Jul 12, 2023



Language-Guided Robotic Manipulation (LGRM) is a challenging task as it requires a robot to understand human instructions to manipulate everyday objects. Recent approaches in LGRM rely on pre-trained Visual Grounding (VG) models to detect objects without adapting to manipulation environments. This results in a performance drop due to a substantial domain gap between the pre-training and real-world data. A straightforward solution is to collect additional training data, but the cost of human-annotation is extortionate. In this paper, we propose Grounding Vision to Ceaselessly Created Instructions (GVCCI), a lifelong learning framework for LGRM, which continuously learns VG without human supervision. GVCCI iteratively generates synthetic instruction via object detection and trains the VG model with the generated data. We validate our framework in offline and online settings across diverse environments on different VG models. Experimental results show that accumulating synthetic data from GVCCI leads to a steady improvement in VG by up to 56.7% and improves resultant LGRM by up to 29.4%. Furthermore, the qualitative analysis shows that the unadapted VG model often fails to find correct objects due to a strong bias learned from the pre-training data. Finally, we introduce a novel VG dataset for LGRM, consisting of nearly 252k triplets of image-object-instruction from diverse manipulation environments.