 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Hardness of Unsupervised Domain Adaptation: Optimal Learners and Information-Theoretic Perspective
Jul 09, 2025



This paper studies the hardness of unsupervised domain adaptation (UDA) under covariate shift. We model the uncertainty that the learner faces by a distribution $\pi$ in the ground-truth triples $(p, q, f)$ -- which we call a UDA class -- where $(p, q)$ is the source -- target distribution pair and $f$ is the classifier. We define the performance of a learner as the overall target domain risk, averaged over the randomness of the ground-truth triple. This formulation couples the source distribution, the target distribution and the classifier in the ground truth, and deviates from the classical worst-case analyses, which pessimistically emphasize the impact of hard but rare UDA instances. In this formulation, we precisely characterize the optimal learner. The performance of the optimal learner then allows us to define the learning difficulty for the UDA class and for the observed sample. To quantify this difficulty, we introduce an information-theoretic quantity -- Posterior Target Label Uncertainty (PTLU) -- along with its empirical estimate (EPTLU) from the sample , which capture the uncertainty in the prediction for the target domain. Briefly, PTLU is the entropy of the predicted label in the target domain under the posterior distribution of ground-truth classifier given the observed source and target samples. By proving that such a quantity serves to lower-bound the risk of any learner, we suggest that these quantities can be used as proxies for evaluating the hardness of UDA learning. We provide several examples to demonstrate the advantage of PTLU, relative to the existing measures, in evaluating the difficulty of UDA learning.
Generalization in Federated Learning: A Conditional Mutual Information Framework
Mar 06, 2025


Federated Learning (FL) is a widely adopted privacy-preserving distributed learning framework, yet its generalization performance remains less explored compared to centralized learning. In FL, the generalization error consists of two components: the out-of-sample gap, which measures the gap between the empirical and true risk for participating clients, and the participation gap, which quantifies the risk difference between participating and non-participating clients. In this work, we apply an information-theoretic analysis via the conditional mutual information (CMI) framework to study FL's two-level generalization. Beyond the traditional supersample-based CMI framework, we introduce a superclient construction to accommodate the two-level generalization setting in FL. We derive multiple CMI-based bounds, including hypothesis-based CMI bounds, illustrating how privacy constraints in FL can imply generalization guarantees. Furthermore, we propose fast-rate evaluated CMI bounds that recover the best-known convergence rate for two-level FL generalization in the small empirical risk regime. For specific FL model aggregation strategies and structured loss functions, we refine our bounds to achieve improved convergence rates with respect to the number of participating clients. Empirical evaluations confirm that our evaluated CMI bounds are non-vacuous and accurately capture the generalization behavior of FL algorithms.
Distributional Information Embedding: A Framework for Multi-bit Watermarking
Jan 27, 2025

This paper introduces a novel problem, distributional information embedding, motivated by the practical demands of multi-bit watermarking for large language models (LLMs). Unlike traditional information embedding, which embeds information into a pre-existing host signal, LLM watermarking actively controls the text generation process--adjusting the token distribution--to embed a detectable signal. We develop an information-theoretic framework to analyze this distributional information embedding problem, characterizing the fundamental trade-offs among three critical performance metrics: text quality, detectability, and information rate. In the asymptotic regime, we demonstrate that the maximum achievable rate with vanishing error corresponds to the entropy of the LLM's output distribution and increases with higher allowable distortion. We also characterize the optimal watermarking scheme to achieve this rate. Extending the analysis to the finite-token case, we identify schemes that maximize detection probability while adhering to constraints on false alarm and distortion.
Generalization Bounds via Conditional $f$-Information
Oct 30, 2024
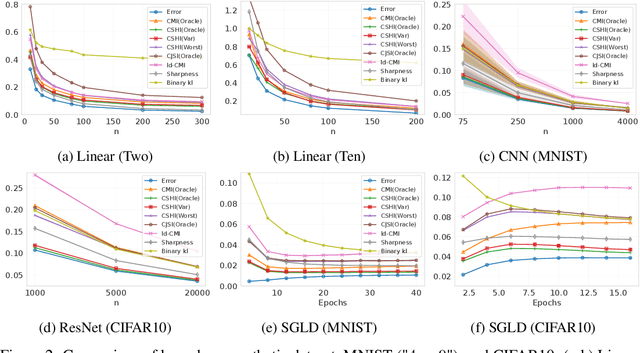
In this work, we introduce novel information-theoretic generalization bounds using the conditional $f$-information framework, an extension of the traditional conditional mutual information (MI) framework. We provide a generic approach to derive generalization bounds via $f$-information in the supersample setting, applicable to both bounded and unbounded loss functions. Unlike previous MI-based bounds, our proof strategy does not rely on upper bounding the cumulant-generating function (CGF) in the variational formula of MI. Instead, we set the CGF or its upper bound to zero by carefully selecting the measurable function invoked in the variational formula. Although some of our techniques are partially inspired by recent advances in the coin-betting framework (e.g., Jang et al. (2023)), our results are independent of any previous findings from regret guarantees of online gambling algorithms. Additionally, our newly derived MI-based bound recovers many previous results and improves our understanding of their potential limitations. Finally, we empirically compare various $f$-information measures for generalization, demonstrating the improvement of our new bounds over the previous bounds.
Universally Optimal Watermarking Schemes for LLMs: from Theory to Practice
Oct 03, 2024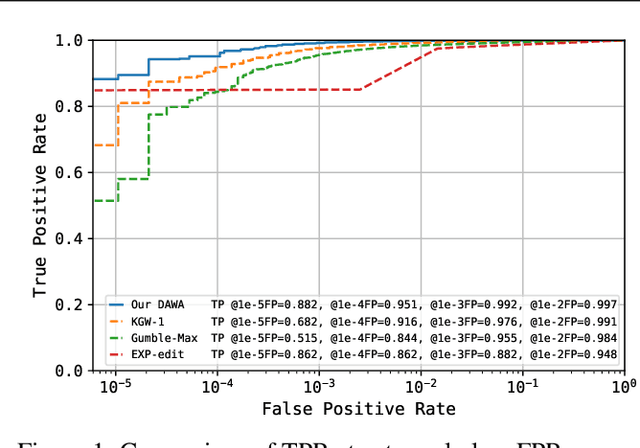
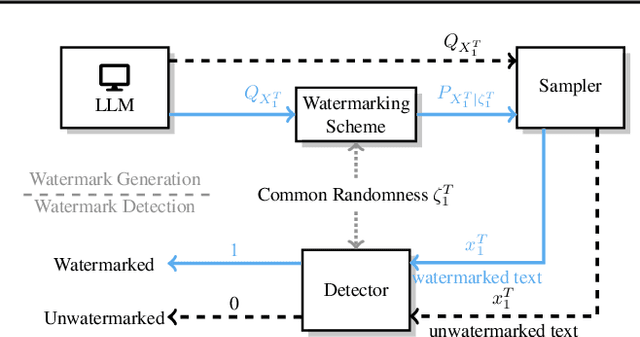

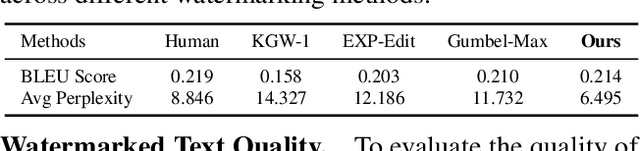
Large Language Models (LLMs) boosts human efficiency but also poses misuse risks, with watermarking serving as a reliable method to differentiate AI-generated content from human-created text. In this work, we propose a novel theoretical framework for watermarking LLMs. Particularly, we jointly optimize both the watermarking scheme and detector to maximize detection performance, while controlling the worst-case Type-I error and distortion in the watermarked text. Within our framework, we characterize the universally minimum Type-II error, showing a fundamental trade-off between detection performance and distortion. More importantly, we identify the optimal type of detectors and watermarking schemes. Building upon our theoretical analysis, we introduce a practical, model-agnostic and computationally efficient token-level watermarking algorithm that invokes a surrogate model and the Gumbel-max trick. Empirical results on Llama-13B and Mistral-8$\times$7B demonstrate the effectiveness of our method. Furthermore, we also explore how robustness can be integrated into our theoretical framework, which provides a foundation for designing future watermarking systems with improved resilience to adversarial attacks.
On f-Divergence Principled Domain Adaptation: An Improved Framework
Feb 02, 2024
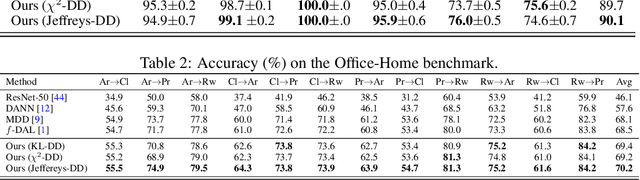
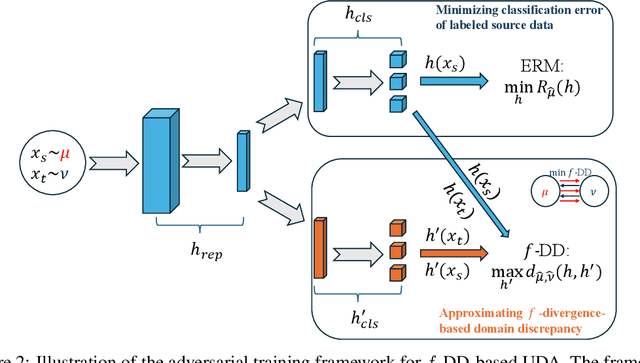
Unsupervised domain adaptation (UDA) plays a crucial role in addressing distribution shifts in machine learning. In this work, we improve the theoretical foundations of UDA proposed by Acuna et al. (2021) by refining their f-divergence-based discrepancy and additionally introducing a new measure, f-domain discrepancy (f-DD). By removing the absolute value function and incorporating a scaling parameter, f-DD yields novel target error and sample complexity bounds, allowing us to recover previous KL-based results and bridging the gap between algorithms and theory presented in Acuna et al. (2021). Leveraging a localization technique, we also develop a fast-rate generalization bound. Empirical results demonstrate the superior performance of f-DD-based domain learning algorithms over previous works in popular UDA benchmarks.
On robust overfitting: adversarial training induced distribution matters
Nov 28, 2023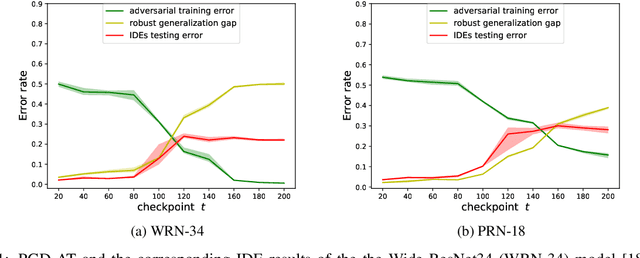

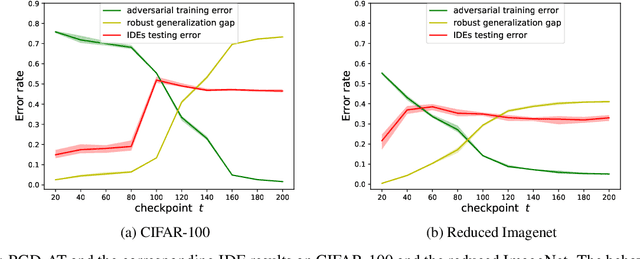
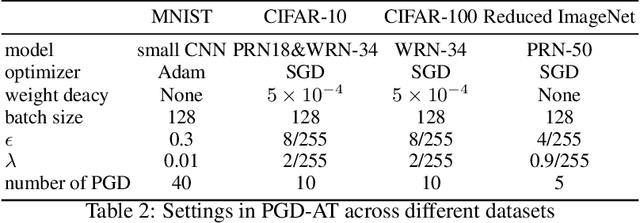
Adversarial training may be regarded as standard training with a modified loss function. But its generalization error appears much larger than standard training under standard loss. This phenomenon, known as robust overfitting, has attracted significant research attention and remains largely as a mystery. In this paper, we first show empirically that robust overfitting correlates with the increasing generalization difficulty of the perturbation-induced distributions along the trajectory of adversarial training (specifically PGD-based adversarial training). We then provide a novel upper bound for generalization error with respect to the perturbation-induced distributions, in which a notion of the perturbation operator, referred to "local dispersion", plays an important role.
Sample-Conditioned Hypothesis Stability Sharpens Information-Theoretic Generalization Bounds
Oct 31, 2023We present new information-theoretic generalization guarantees through the a novel construction of the "neighboring-hypothesis" matrix and a new family of stability notions termed sample-conditioned hypothesis (SCH) stability. Our approach yields sharper bounds that improve upon previous information-theoretic bounds in various learning scenarios. Notably, these bounds address the limitations of existing information-theoretic bounds in the context of stochastic convex optimization (SCO) problems, as explored in the recent work by Haghifam et al. (2023).
Anaphor Assisted Document-Level Relation Extraction
Oct 28, 2023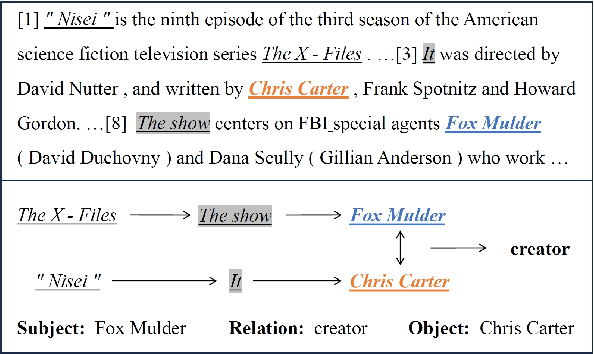
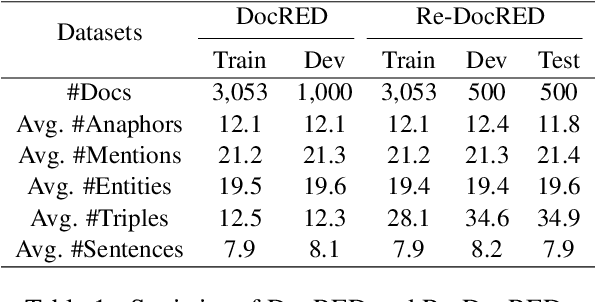

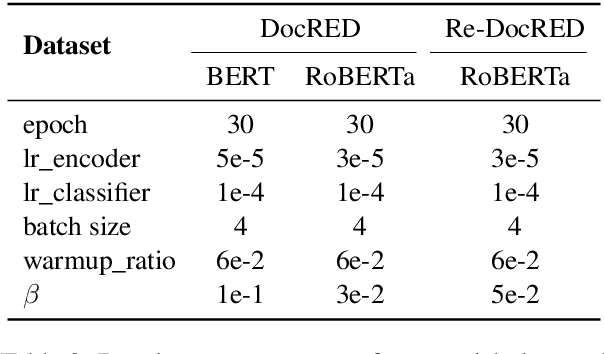
Document-level relation extraction (DocRE) involves identifying relations between entities distributed in multiple sentences within a document. Existing methods focus on building a heterogeneous document graph to model the internal structure of an entity and the external interaction between entities. However, there are two drawbacks in existing methods. On one hand, anaphor plays an important role in reasoning to identify relations between entities but is ignored by these methods. On the other hand, these methods achieve cross-sentence entity interactions implicitly by utilizing a document or sentences as intermediate nodes. Such an approach has difficulties in learning fine-grained interactions between entities across different sentences, resulting in sub-optimal performance. To address these issues, we propose an Anaphor-Assisted (AA) framework for DocRE tasks. Experimental results on the widely-used datasets demonstrate that our model achieves a new state-of-the-art performance.
Narrowing the Gap between Supervised and Unsupervised Sentence Representation Learning with Large Language Model
Sep 12, 2023Sentence Representation Learning (SRL) is a fundamental task in Natural Language Processing (NLP), with Contrastive learning of Sentence Embeddings (CSE) as the mainstream technique due to its superior performance. An intriguing phenomenon in CSE is the significant performance gap between supervised and unsupervised methods, even when their sentence encoder and loss function are the same. Previous works attribute this performance gap to differences in two representation properties (alignment and uniformity). However, alignment and uniformity only measure the results, which means they cannot answer "What happens during the training process that leads to the performance gap?" and "How can the performance gap be narrowed?". In this paper, we conduct empirical experiments to answer these "What" and "How" questions. We first answer the "What" question by thoroughly comparing the behavior of supervised and unsupervised CSE during their respective training processes. From the comparison, We observe a significant difference in fitting difficulty. Thus, we introduce a metric, called Fitting Difficulty Increment (FDI), to measure the fitting difficulty gap between the evaluation dataset and the held-out training dataset, and use the metric to answer the "What" question. Then, based on the insights gained from the "What" question, we tackle the "How" question by increasing the fitting difficulty of the training dataset. We achieve this by leveraging the In-Context Learning (ICL) capability of the Large Language Model (LLM) to generate data that simulates complex patterns. By utilizing the hierarchical patterns in the LLM-generated data, we effectively narrow the gap between supervised and unsupervised CSE.