 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversally Optimal Watermarking Schemes for LLMs: from Theory to Practice
Paper and Code
Oct 03, 2024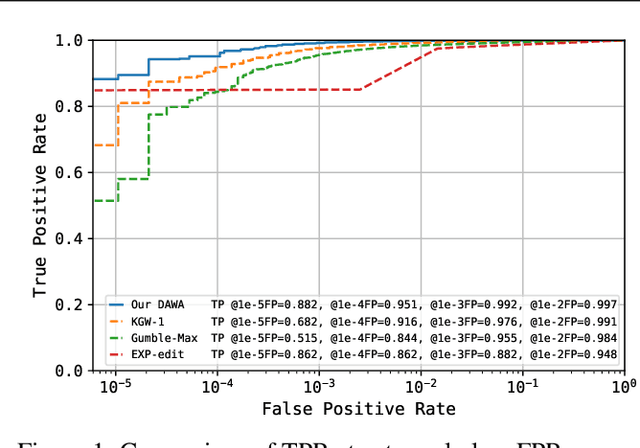
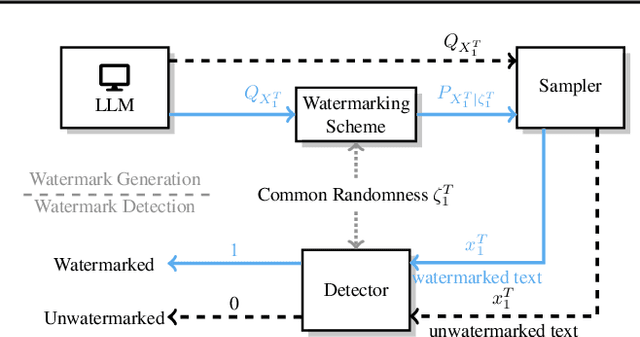

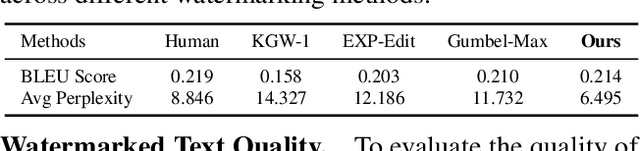
Large Language Models (LLMs) boosts human efficiency but also poses misuse risks, with watermarking serving as a reliable method to differentiate AI-generated content from human-created text. In this work, we propose a novel theoretical framework for watermarking LLMs. Particularly, we jointly optimize both the watermarking scheme and detector to maximize detection performance, while controlling the worst-case Type-I error and distortion in the watermarked text. Within our framework, we characterize the universally minimum Type-II error, showing a fundamental trade-off between detection performance and distortion. More importantly, we identify the optimal type of detectors and watermarking schemes. Building upon our theoretical analysis, we introduce a practical, model-agnostic and computationally efficient token-level watermarking algorithm that invokes a surrogate model and the Gumbel-max trick. Empirical results on Llama-13B and Mistral-8$\times$7B demonstrate the effectiveness of our method. Furthermore, we also explore how robustness can be integrated into our theoretical framework, which provides a foundation for designing future watermarking systems with improved resilience to adversarial attacks.