 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Blessing of Pre-training in Weak-to-Strong Generalization
May 07, 2026The paradigm of Weak-to-Strong Generalization (W2SG) suggests that a pre-trained strong model can surpass its weak supervisor, yet the decisive role of pre-training remains theoretically and empirically under-explored. In this work, we identify pre-training as the essential prerequisite for the emergence of W2SG. Theoretically, we formalize the W2SG problem within a high-dimensional single-index model framework using spiked Gaussian data, modeling pre-training as a spectral initialization step. Building upon prior impossibility results regarding the failure of learning under random initialization, we prove that W2SG is achievable when pre-training provides a geometric warm start that places the model within an "effective region" characterized by a perturbed strong-convexity geometry. Within this region, we derive a rigorous generalization bound that naturally captures the optimization dynamics: an initial performance improvement followed by a saturation bottleneck dictated by the weak supervisor's bias. Empirically, we first validate all our assumptions and theoretical insights through controlled synthetic simulations. Finally, through a massive-scale evaluation of hundreds of intermediate pre-training checkpoints from large language models, we demonstrate that W2SG is not an innate capability but emerges via a phase transition tightly coupled with the progression of pre-training.
Flexible and Foldable: Workspace Analysis and Object Manipulation Using a Soft, Interconnected, Origami-Inspired Actuator Array
Sep 17, 2025Object manipulation is a fundamental challenge in robotics, where systems must balance trade-offs among manipulation capabilities, system complexity, and throughput. Distributed manipulator systems (DMS) use the coordinated motion of actuator arrays to perform complex object manipulation tasks, seeing widespread exploration within the literature and in industry. However, existing DMS designs typically rely on high actuator densities and impose constraints on object-to-actuator scale ratios, limiting their adaptability. We present a novel DMS design utilizing an array of 3-DoF, origami-inspired robotic tiles interconnected by a compliant surface layer. Unlike conventional DMS, our approach enables manipulation not only at the actuator end effectors but also across a flexible surface connecting all actuators; creating a continuous, controllable manipulation surface. We analyse the combined workspace of such a system, derive simple motion primitives, and demonstrate its capabilities to translate simple geometric objects across an array of tiles. By leveraging the inter-tile connective material, our approach significantly reduces actuator density, increasing the area over which an object can be manipulated by x1.84 without an increase in the number of actuators. This design offers a lower cost and complexity alternative to traditional high-density arrays, and introduces new opportunities for manipulation strategies that leverage the flexibility of the interconnected surface.
On the Emergence of Weak-to-Strong Generalization: A Bias-Variance Perspective
May 30, 2025Weak-to-strong generalization (W2SG) refers to the phenomenon where a strong student model, trained on a dataset labeled by a weak teacher, ultimately outperforms the teacher on the target task. Recent studies attribute this performance gain to the prediction misfit between the student and teacher models. In this work, we theoretically investigate the emergence of W2SG through a generalized bias-variance decomposition of Bregman divergence. Specifically, we show that the expected population risk gap between the student and teacher is quantified by the expected misfit between the two models. While this aligns with previous results, our analysis removes several restrictive assumptions, most notably, the convexity of the student's hypothesis class, required in earlier works. Moreover, we show that W2SG is more likely to emerge when the student model approximates its posterior mean teacher, rather than mimicking an individual teacher. Using a concrete example, we demonstrate that if the student model has significantly larger capacity than the teacher, it can indeed converge to this posterior mean. Our analysis also suggests that avoiding overfitting to the teacher's supervision and reducing the entropy of student's prediction further facilitate W2SG. In addition, we show that the reverse cross-entropy loss, unlike the standard forward cross-entropy, is less sensitive to the predictive uncertainty of the teacher. Finally, we empirically verify our theoretical insights and demonstrate that incorporating the reverse cross-entropy loss consistently improves student performance.
REPA Works Until It Doesn't: Early-Stopped, Holistic Alignment Supercharges Diffusion Training
May 22, 2025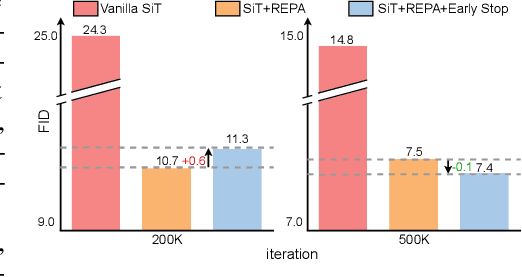
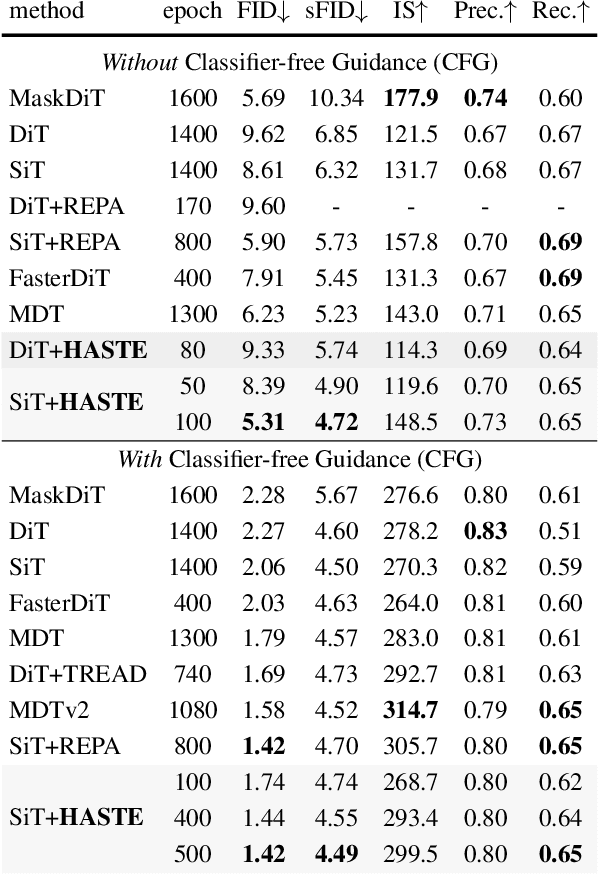

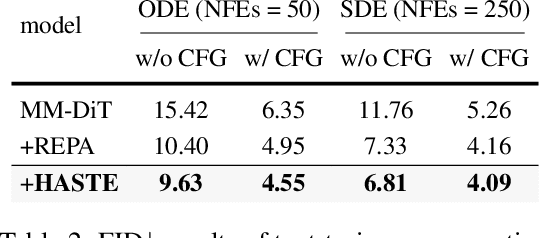
Diffusion Transformers (DiTs) deliver state-of-the-art image quality, yet their training remains notoriously slow. A recent remedy -- representation alignment (REPA) that matches DiT hidden features to those of a non-generative teacher (e.g. DINO) -- dramatically accelerates the early epochs but plateaus or even degrades performance later. We trace this failure to a capacity mismatch: once the generative student begins modelling the joint data distribution, the teacher's lower-dimensional embeddings and attention patterns become a straitjacket rather than a guide. We then introduce HASTE (Holistic Alignment with Stage-wise Termination for Efficient training), a two-phase schedule that keeps the help and drops the hindrance. Phase I applies a holistic alignment loss that simultaneously distills attention maps (relational priors) and feature projections (semantic anchors) from the teacher into mid-level layers of the DiT, yielding rapid convergence. Phase II then performs one-shot termination that deactivates the alignment loss, once a simple trigger such as a fixed iteration is hit, freeing the DiT to focus on denoising and exploit its generative capacity. HASTE speeds up training of diverse DiTs without architecture changes. On ImageNet 256X256, it reaches the vanilla SiT-XL/2 baseline FID in 50 epochs and matches REPA's best FID in 500 epochs, amounting to a 28X reduction in optimization steps. HASTE also improves text-to-image DiTs on MS-COCO, demonstrating to be a simple yet principled recipe for efficient diffusion training across various tasks. Our code is available at https://github.com/NUS-HPC-AI-Lab/HASTE .
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Ensemble Debiasing Across Class and Sample Levels for Fairer Prompting Accuracy
Mar 07, 2025



Language models are strong few-shot learners and achieve good overall accuracy in text classification tasks, masking the fact that their results suffer from great class accuracy imbalance. We believe that the pursuit of overall accuracy should not come from enriching the strong classes, but from raising up the weak ones. To address the imbalance, we propose a post-hoc nonlinear integer programming based debiasing method that ensembles weight correction and membership correction to enable flexible rectifications of class probabilities at both class and sample levels, enhancing the performance of LLMs directly from their outputs. Evaluations with Llama-2-13B on seven text classification benchmarks show that our approach achieves state-of-the-art overall accuracy gains with balanced class accuracies. The resulted probability correction scheme demonstrates that sample-level corrections are necessary to elevate weak classes. In addition, due to effectively correcting weak classes, our method also brings significant performance gains to Llama-2-70B, especially on a biomedical domain task, demonstrating its effectiveness across both small and large model variants.
Generalization in Federated Learning: A Conditional Mutual Information Framework
Mar 06, 2025


Federated Learning (FL) is a widely adopted privacy-preserving distributed learning framework, yet its generalization performance remains less explored compared to centralized learning. In FL, the generalization error consists of two components: the out-of-sample gap, which measures the gap between the empirical and true risk for participating clients, and the participation gap, which quantifies the risk difference between participating and non-participating clients. In this work, we apply an information-theoretic analysis via the conditional mutual information (CMI) framework to study FL's two-level generalization. Beyond the traditional supersample-based CMI framework, we introduce a superclient construction to accommodate the two-level generalization setting in FL. We derive multiple CMI-based bounds, including hypothesis-based CMI bounds, illustrating how privacy constraints in FL can imply generalization guarantees. Furthermore, we propose fast-rate evaluated CMI bounds that recover the best-known convergence rate for two-level FL generalization in the small empirical risk regime. For specific FL model aggregation strategies and structured loss functions, we refine our bounds to achieve improved convergence rates with respect to the number of participating clients. Empirical evaluations confirm that our evaluated CMI bounds are non-vacuous and accurately capture the generalization behavior of FL algorithms.
CPG-Based Manipulation with Multi-Module Origami Robot Surface
Feb 26, 2025



Robotic manipulators often face challenges in handling objects of different sizes and materials, limiting their effectiveness in practical applications. This issue is particularly pronounced when manipulating meter-scale objects or those with varying stiffness, as traditional gripping techniques and strategies frequently prove inadequate. In this letter, we introduce a novel surface-based multi-module robotic manipulation framework that utilizes a Central Pattern Generator (CPG)-based motion generator, combined with a simulation-based optimization method to determine the optimal manipulation parameters for a multi-module origami robotic surface (Ori-Pixel). This approach allows for the manipulation of objects ranging from centimeters to meters in size, with varying stiffness and shape. The optimized CPG parameters are tested through both dynamic simulations and a series of prototype experiments involving a wide range of objects differing in size, weight, shape, and material, demonstrating robust manipulation capabilities.
Surface-Based Manipulation
Feb 26, 2025



Intelligence lies not only in the brain but in the body. The shape of our bodies can influence how we think and interact with the physical world. In robotics research, interacting with the physical world is crucial as it allows robots to manipulate objects in various real-life scenarios. Conventional robotic manipulation strategies mainly rely on finger-shaped end effectors. However, achieving stable grasps on fragile, deformable, irregularly shaped, or slippery objects is challenging due to difficulties in establishing stable force or geometric constraints. Here, we present surface-based manipulation strategies that diverge from classical grasping approaches, using with flat surfaces as minimalist end-effectors. By changing the position and orientation of these surfaces, objects can be translated, rotated and even flipped across the surface using closed-loop control strategies. Since this method does not rely on stable grasp, it can adapt to objects of various shapes, sizes, and stiffness levels, even enabling the manipulation the shape of deformable objects. Our results provide a new perspective for solving complex manipulation problems.
Distributional Information Embedding: A Framework for Multi-bit Watermarking
Jan 27, 2025

This paper introduces a novel problem, distributional information embedding, motivated by the practical demands of multi-bit watermarking for large language models (LLMs). Unlike traditional information embedding, which embeds information into a pre-existing host signal, LLM watermarking actively controls the text generation process--adjusting the token distribution--to embed a detectable signal. We develop an information-theoretic framework to analyze this distributional information embedding problem, characterizing the fundamental trade-offs among three critical performance metrics: text quality, detectability, and information rate. In the asymptotic regime, we demonstrate that the maximum achievable rate with vanishing error corresponds to the entropy of the LLM's output distribution and increases with higher allowable distortion. We also characterize the optimal watermarking scheme to achieve this rate. Extending the analysis to the finite-token case, we identify schemes that maximize detection probability while adhering to constraints on false alarm and distortion.