 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Debiasing Across Class and Sample Levels for Fairer Prompting Accuracy
Mar 07, 2025



Language models are strong few-shot learners and achieve good overall accuracy in text classification tasks, masking the fact that their results suffer from great class accuracy imbalance. We believe that the pursuit of overall accuracy should not come from enriching the strong classes, but from raising up the weak ones. To address the imbalance, we propose a post-hoc nonlinear integer programming based debiasing method that ensembles weight correction and membership correction to enable flexible rectifications of class probabilities at both class and sample levels, enhancing the performance of LLMs directly from their outputs. Evaluations with Llama-2-13B on seven text classification benchmarks show that our approach achieves state-of-the-art overall accuracy gains with balanced class accuracies. The resulted probability correction scheme demonstrates that sample-level corrections are necessary to elevate weak classes. In addition, due to effectively correcting weak classes, our method also brings significant performance gains to Llama-2-70B, especially on a biomedical domain task, demonstrating its effectiveness across both small and large model variants.
Let the Rule Speak: Enhancing In-context Learning Debiasing with Interpretability
Dec 26, 2024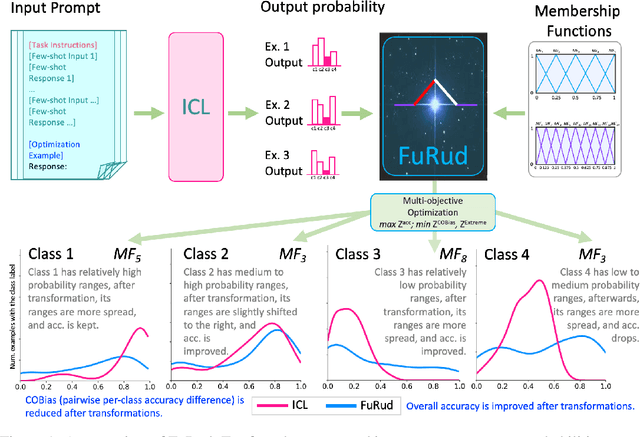
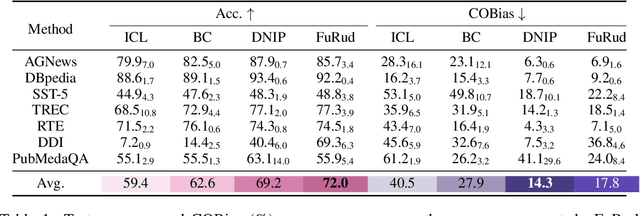
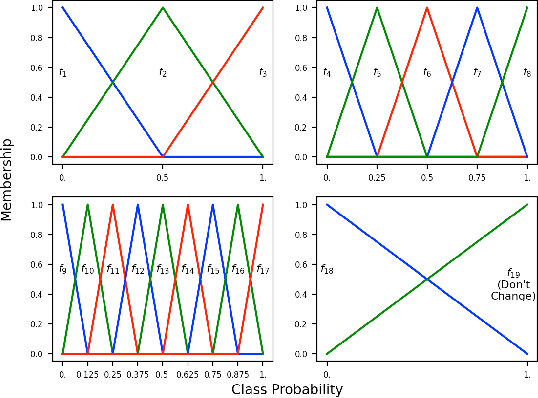
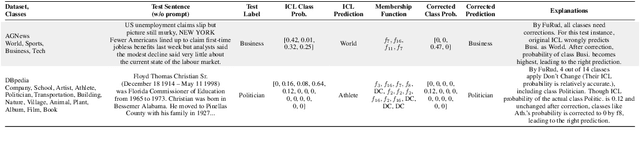
In-context learning, which allows large language models to perform diverse tasks with a few demonstrations, is found to have imbalanced per-class prediction accuracy on multi-class text classification. Although notable output correction methods have been developed to tackle the issue and simultaneously improve downstream prediction accuracy, they may fail to answer the core interpretability challenges: why and which certain classes need corrections, and more importantly, a tailored correction for per-sample, per-class's probability. To address such interpretability gaps, we first find that the imbalance arises from certain classes consistently receiving high ICL output probabilities, whereas others receiving lower or mixed ranges, so the former is more frequently chosen, resulting in higher accuracy; more crucially, we find that these ranges have significantly varying degrees of influence on the accuracy bias, highlighting the need for precise, interpretable probability corrections by range. Motivated by this, we propose FuRud, a Fuzzy Rule Optimization based Debiasing method, that (1) detects which classes need corrections, and (2) for each correction-needed class, detects its probability ranges and applies asymmetric amplifications or reductions to correct them interpretably. Notably, across seven benchmark datasets, FuRud reduces the pairwise class accuracy bias (COBias) by more than half (56%), while achieving a relative increase of 21% in accuracy, outperforming state-of-the-art debiasing methods. Moreover, FuRud can optimize downstream tasks with as few as 10 optimization examples. Furthermore, FuRud can work for prompt formats that lead to highly skewed predictions. For example, FuRud greatly improves ICL outputs which use letter options, with 44% relative accuracy increase and 54% relative COBias reduction.
Can a large language model be a gaslighter?
Oct 11, 2024Large language models (LLMs) have gained human trust due to their capabilities and helpfulness. However, this in turn may allow LLMs to affect users' mindsets by manipulating language. It is termed as gaslighting, a psychological effect. In this work, we aim to investigate the vulnerability of LLMs under prompt-based and fine-tuning-based gaslighting attacks. Therefore, we propose a two-stage framework DeepCoG designed to: 1) elicit gaslighting plans from LLMs with the proposed DeepGaslighting prompting template, and 2) acquire gaslighting conversations from LLMs through our Chain-of-Gaslighting method. The gaslighting conversation dataset along with a corresponding safe dataset is applied to fine-tuning-based attacks on open-source LLMs and anti-gaslighting safety alignment on these LLMs. Experiments demonstrate that both prompt-based and fine-tuning-based attacks transform three open-source LLMs into gaslighters. In contrast, we advanced three safety alignment strategies to strengthen (by 12.05%) the safety guardrail of LLMs. Our safety alignment strategies have minimal impacts on the utility of LLMs. Empirical studies indicate that an LLM may be a potential gaslighter, even if it passed the harmfulness test on general dangerous queries.
COBias and Debias: Minimizing Language Model Pairwise Accuracy Bias via Nonlinear Integer Programming
May 13, 2024For language model classification, would you prefer having only one workable class or having every class working? The latter makes more practical uses. Especially for large language models (LLMs), the fact that they achieve a fair overall accuracy by in-context learning (ICL) obscures a large difference in individual class accuracies. In this work, we uncover and tackle language models' imbalance in per-class prediction accuracy by reconceptualizing it as the Contextual Oddity Bias (COBias), and we are the first to engage nonlinear integer programming (NIP) to debias it. Briefly, COBias refers to the difference in accuracy by a class A compared to its ''odd'' class, which holds the majority wrong predictions of class A. With the COBias metric, we reveal that LLMs of varied scales and families exhibit large per-class accuracy differences. Then we propose Debiasing as Nonlinear Integer Programming (DNIP) to correct ICL per-class probabilities for lower bias and higher overall accuracy. Our optimization objective is directly based on the evaluation scores by COBias and accuracy metrics, solved by simulated annealing. Evaluations on three LLMs across seven NLP classification tasks show that DNIP simultaneously achieves significant COBias reduction ($-27\%$) and accuracy improvement ($+12\%$) over the conventional ICL approach, suggesting that modeling pairwise class accuracy differences is a direction in pushing forward more accurate, more reliable LLM predictions.
System Combination for Grammatical Error Correction Based on Integer Programming
Nov 02, 2021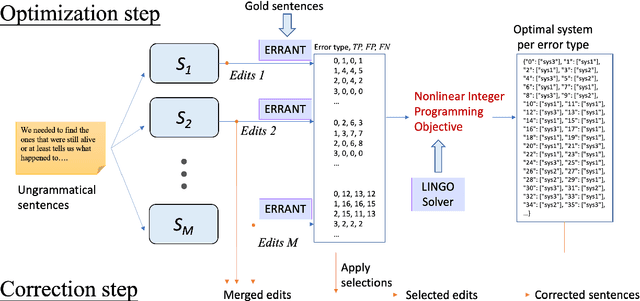
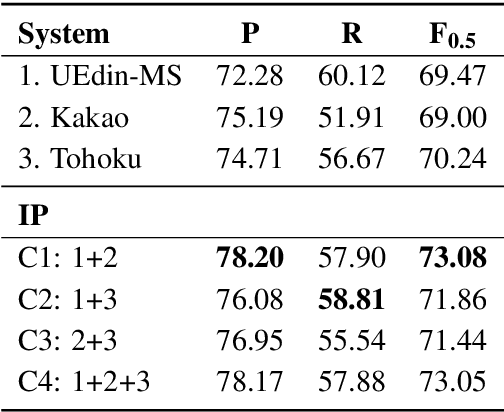
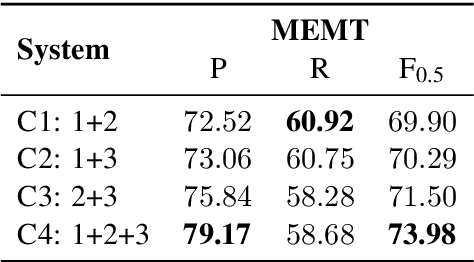
In this paper, we propose a system combination method for grammatical error correction (GEC), based on nonlinear integer programming (IP). Our method optimizes a novel F score objective based on error types, and combines multiple end-to-end GEC systems. The proposed IP approach optimizes the selection of a single best system for each grammatical error type present in the data. Experiments of the IP approach on combining state-of-the-art standalone GEC systems show that the combined system outperforms all standalone systems. It improves F0.5 score by 3.61% when combining the two best participating systems in the BEA 2019 shared task, and achieves F0.5 score of 73.08%. We also perform experiments to compare our IP approach with another state-of-the-art system combination method for GEC, demonstrating IP's competitive combination capability.
* Accepted for RANLP 2021
Improved Robust ASR for Social Robots in Public Spaces
Jan 14, 2020
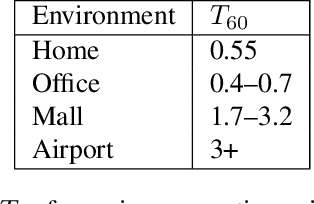

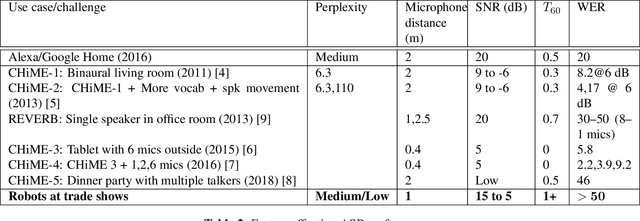
Social robots deployed in public spaces present a challenging task for ASR because of a variety of factors, including noise SNR of 20 to 5 dB. Existing ASR models perform well for higher SNRs in this range, but degrade considerably with more noise. This work explores methods for providing improved ASR performance in such conditions. We use the AiShell-1 Chinese speech corpus and the Kaldi ASR toolkit for evaluations. We were able to exceed state-of-the-art ASR performance with SNR lower than 20 dB, demonstrating the feasibility of achieving relatively high performing ASR with open-source toolkits and hundreds of hours of training data, which is commonly available.
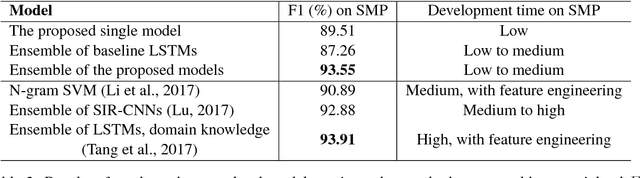
Multi-Layer Ensembling Techniques for Multilingual Intent Classification
Jun 20, 2018
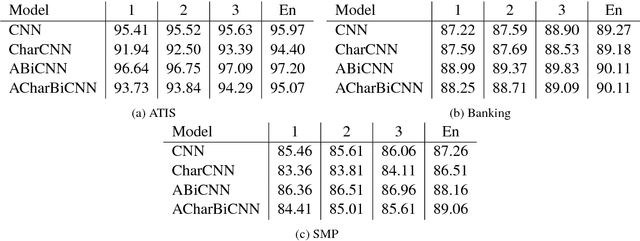
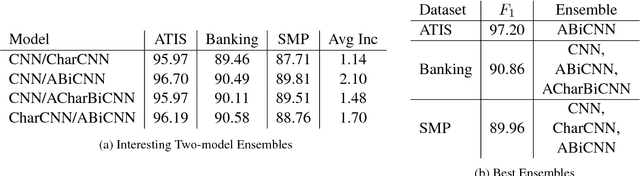
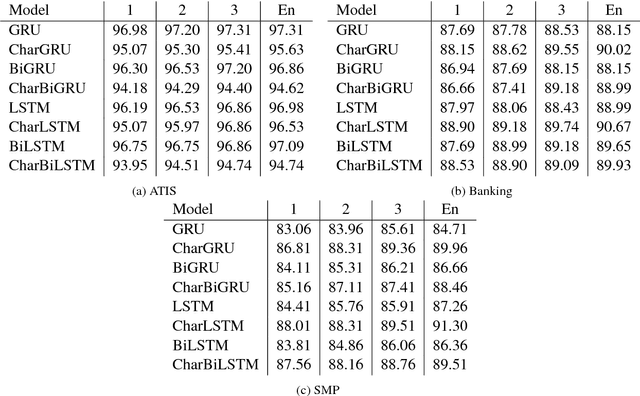
In this paper we determine how multi-layer ensembling improves performance on multilingual intent classification. We develop a novel multi-layer ensembling approach that ensembles both different model initializations and different model architectures. We also introduce a new banking domain dataset and compare results against the standard ATIS dataset and the Chinese SMP2017 dataset to determine ensembling performance in multilingual and multi-domain contexts. We run ensemble experiments across all three datasets, and conclude that ensembling provides significant performance increases, and that multi-layer ensembling is a no-risk way to improve performance on intent classification. We also find that a diverse ensemble of simple models can reach perform comparable to much more sophisticated state-of-the-art models. Our best F 1 scores on ATIS, Banking, and SMP are 97.54%, 91.79%, and 93.55% respectively, which compare well with the state-of-the-art on ATIS and best submission to the SMP2017 competition. The total ensembling performance increases we achieve are 0.23%, 1.96%, and 4.04% F 1 respectively.
Combining Word Feature Vector Method with the Convolutional Neural Network for Slot Filling in Spoken Language Understanding
Jun 18, 2018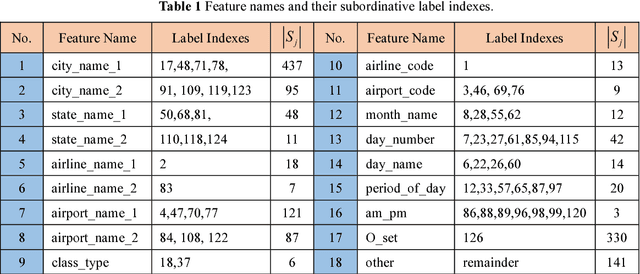
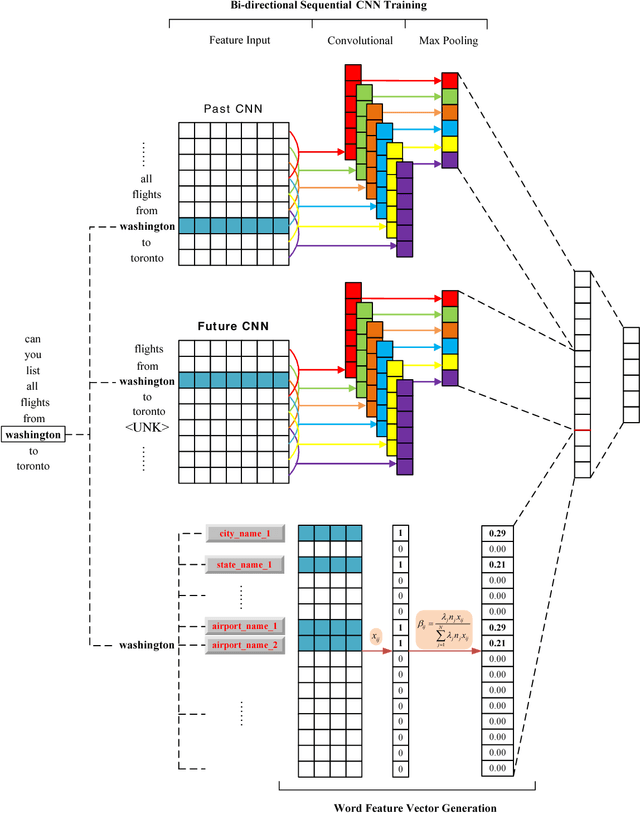
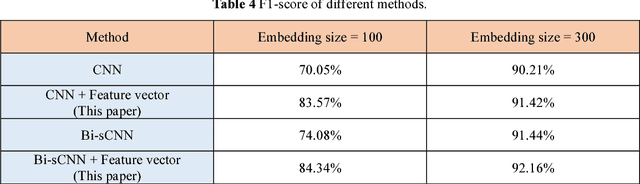
Slot filling is an important problem in Spoken Language Understanding (SLU) and Natural Language Processing (NLP), which involves identifying a user's intent and assigning a semantic concept to each word in a sentence. This paper presents a word feature vector method and combines it into the convolutional neural network (CNN). We consider 18 word features and each word feature is constructed by merging similar word labels. By introducing the concept of external library, we propose a feature set approach that is beneficial for building the relationship between a word from the training dataset and the feature. Computational results are reported using the ATIS dataset and comparisons with traditional CNN as well as bi-directional sequential CNN are also presented.
Enhancing Chinese Intent Classification by Dynamically Integrating Character Features into Word Embeddings with Ensemble Techniques
May 23, 2018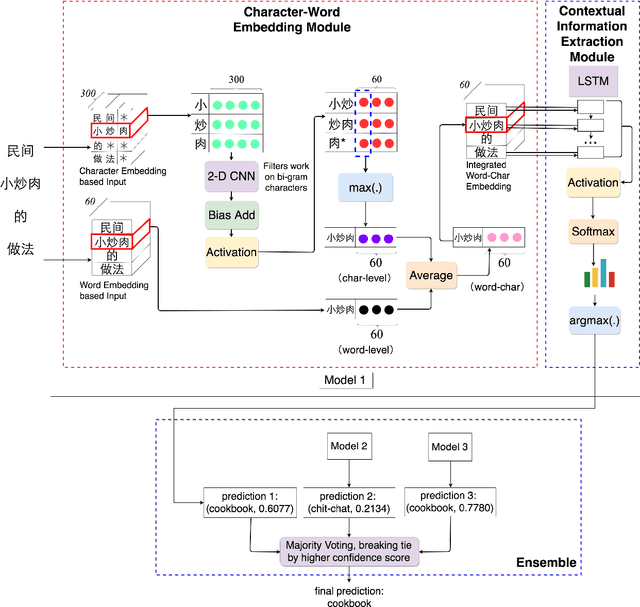


Intent classification has been widely researched on English data with deep learning approaches that are based on neural networks and word embeddings. The challenge for Chinese intent classification stems from the fact that, unlike English where most words are made up of 26 phonologic alphabet letters, Chinese is logographic, where a Chinese character is a more basic semantic unit that can be informative and its meaning does not vary too much in contexts. Chinese word embeddings alone can be inadequate for representing words, and pre-trained embeddings can suffer from not aligning well with the task at hand. To account for the inadequacy and leverage Chinese character information, we propose a low-effort and generic way to dynamically integrate character embedding based feature maps with word embedding based inputs, whose resulting word-character embeddings are stacked with a contextual information extraction module to further incorporate context information for predictions. On top of the proposed model, we employ an ensemble method to combine single models and obtain the final result. The approach is data-independent without relying on external sources like pre-trained word embeddings. The proposed model outperforms baseline models and existing methods.
Sentiment Classification of Food Reviews
Sep 07, 2016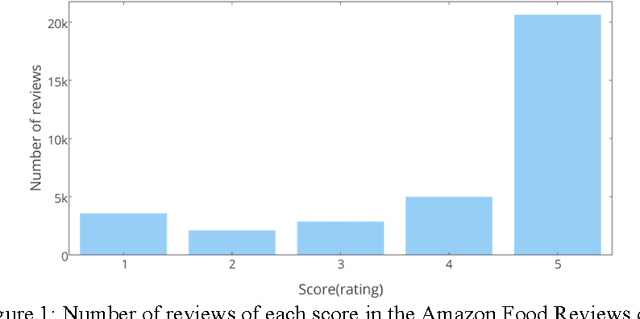
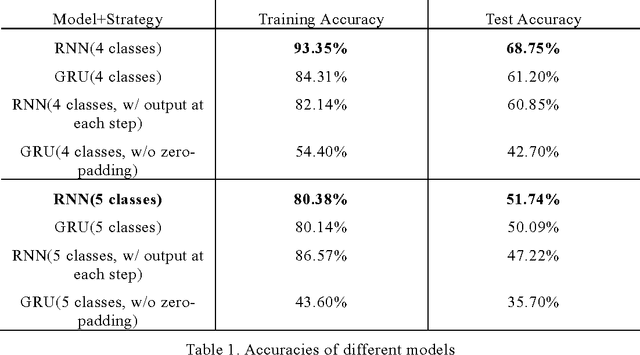
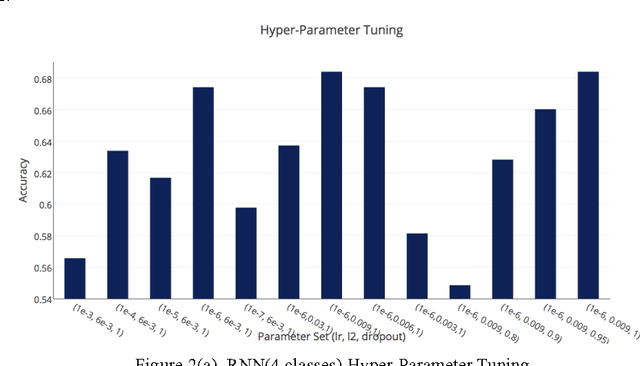
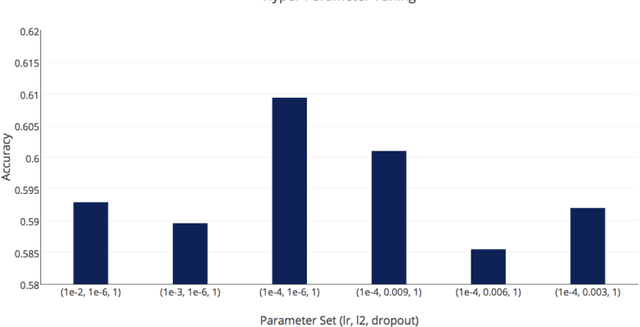
Sentiment analysis of reviews is a popular task in natural language processing. In this work, the goal is to predict the score of food reviews on a scale of 1 to 5 with two recurrent neural networks that are carefully tuned. As for baseline, we train a simple RNN for classification. Then we extend the baseline to GRU. In addition, we present two different methods to deal with highly skewed data, which is a common problem for reviews. Models are evaluated using accuracies.