 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Rule Speak: Enhancing In-context Learning Debiasing with Interpretability
Paper and Code
Dec 26, 2024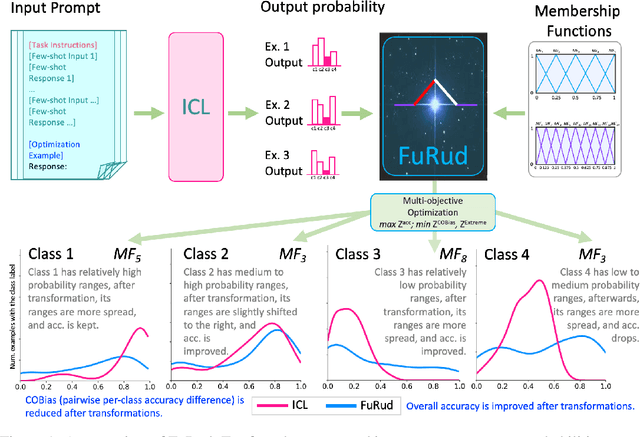
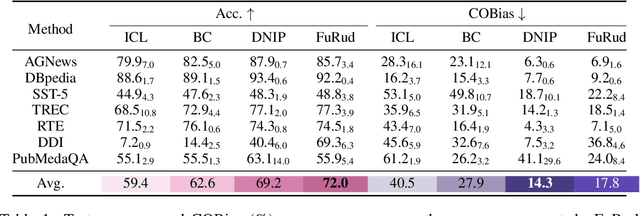
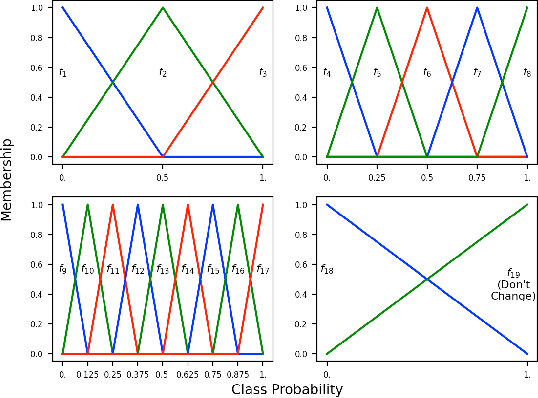
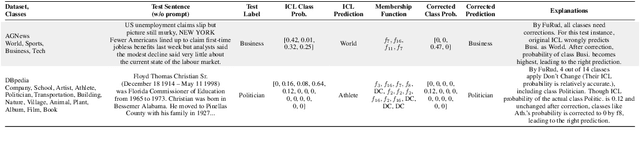
In-context learning, which allows large language models to perform diverse tasks with a few demonstrations, is found to have imbalanced per-class prediction accuracy on multi-class text classification. Although notable output correction methods have been developed to tackle the issue and simultaneously improve downstream prediction accuracy, they may fail to answer the core interpretability challenges: why and which certain classes need corrections, and more importantly, a tailored correction for per-sample, per-class's probability. To address such interpretability gaps, we first find that the imbalance arises from certain classes consistently receiving high ICL output probabilities, whereas others receiving lower or mixed ranges, so the former is more frequently chosen, resulting in higher accuracy; more crucially, we find that these ranges have significantly varying degrees of influence on the accuracy bias, highlighting the need for precise, interpretable probability corrections by range. Motivated by this, we propose FuRud, a Fuzzy Rule Optimization based Debiasing method, that (1) detects which classes need corrections, and (2) for each correction-needed class, detects its probability ranges and applies asymmetric amplifications or reductions to correct them interpretably. Notably, across seven benchmark datasets, FuRud reduces the pairwise class accuracy bias (COBias) by more than half (56%), while achieving a relative increase of 21% in accuracy, outperforming state-of-the-art debiasing methods. Moreover, FuRud can optimize downstream tasks with as few as 10 optimization examples. Furthermore, FuRud can work for prompt formats that lead to highly skewed predictions. For example, FuRud greatly improves ICL outputs which use letter options, with 44% relative accuracy increase and 54% relative COBias reduction.