 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Layer Ensembling Techniques for Multilingual Intent Classification
Jun 20, 2018
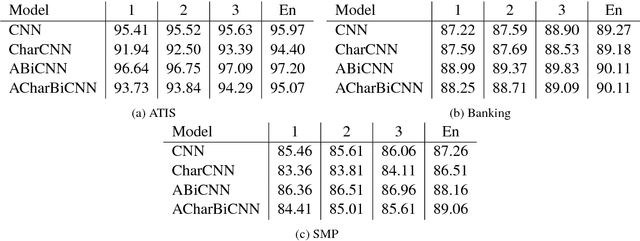
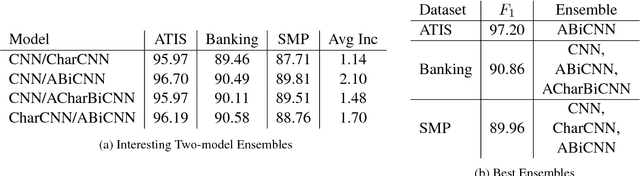
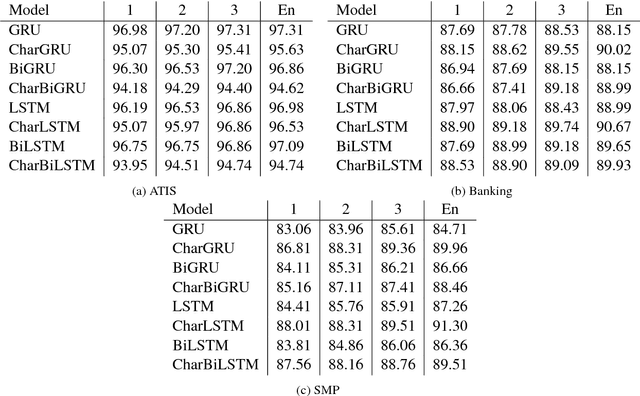
In this paper we determine how multi-layer ensembling improves performance on multilingual intent classification. We develop a novel multi-layer ensembling approach that ensembles both different model initializations and different model architectures. We also introduce a new banking domain dataset and compare results against the standard ATIS dataset and the Chinese SMP2017 dataset to determine ensembling performance in multilingual and multi-domain contexts. We run ensemble experiments across all three datasets, and conclude that ensembling provides significant performance increases, and that multi-layer ensembling is a no-risk way to improve performance on intent classification. We also find that a diverse ensemble of simple models can reach perform comparable to much more sophisticated state-of-the-art models. Our best F 1 scores on ATIS, Banking, and SMP are 97.54%, 91.79%, and 93.55% respectively, which compare well with the state-of-the-art on ATIS and best submission to the SMP2017 competition. The total ensembling performance increases we achieve are 0.23%, 1.96%, and 4.04% F 1 respectively.
Enhancing Chinese Intent Classification by Dynamically Integrating Character Features into Word Embeddings with Ensemble Techniques
May 23, 2018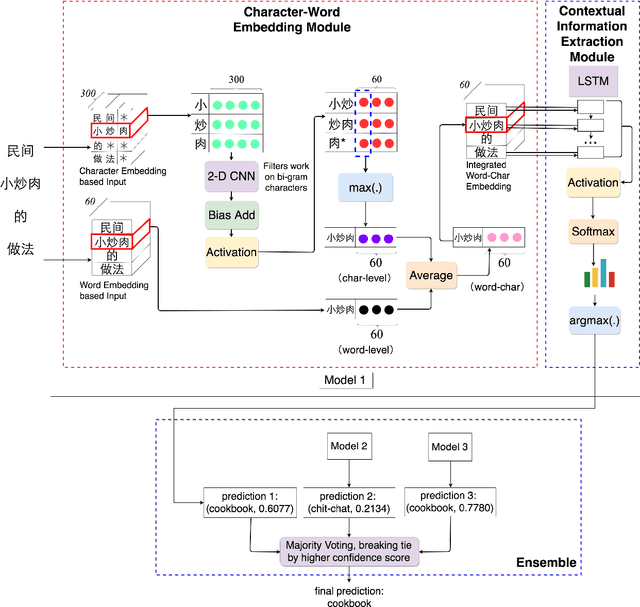


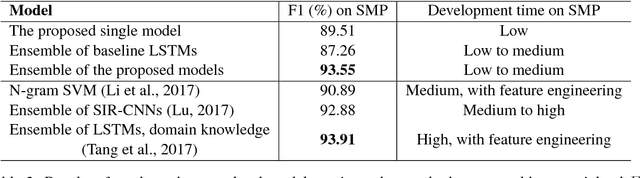
Intent classification has been widely researched on English data with deep learning approaches that are based on neural networks and word embeddings. The challenge for Chinese intent classification stems from the fact that, unlike English where most words are made up of 26 phonologic alphabet letters, Chinese is logographic, where a Chinese character is a more basic semantic unit that can be informative and its meaning does not vary too much in contexts. Chinese word embeddings alone can be inadequate for representing words, and pre-trained embeddings can suffer from not aligning well with the task at hand. To account for the inadequacy and leverage Chinese character information, we propose a low-effort and generic way to dynamically integrate character embedding based feature maps with word embedding based inputs, whose resulting word-character embeddings are stacked with a contextual information extraction module to further incorporate context information for predictions. On top of the proposed model, we employ an ensemble method to combine single models and obtain the final result. The approach is data-independent without relying on external sources like pre-trained word embeddings. The proposed model outperforms baseline models and existing methods.