 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Language Models as Symbolic Knowledge Graphs
Aug 25, 2023Symbolic knowledge graphs (KGs) play a pivotal role in knowledge-centric applications such as search, question answering and recommendation. As contemporary language models (LMs) trained on extensive textual data have gained prominence, researchers have extensively explored whether the parametric knowledge within these models can match up to that present in knowledge graphs. Various methodologies have indicated that enhancing the size of the model or the volume of training data enhances its capacity to retrieve symbolic knowledge, often with minimal or no human supervision. Despite these advancements, there is a void in comprehensively evaluating whether LMs can encompass the intricate topological and semantic attributes of KGs, attributes crucial for reasoning processes. In this work, we provide an exhaustive evaluation of language models of varying sizes and capabilities. We construct nine qualitative benchmarks that encompass a spectrum of attributes including symmetry, asymmetry, hierarchy, bidirectionality, compositionality, paths, entity-centricity, bias and ambiguity. Additionally, we propose novel evaluation metrics tailored for each of these attributes. Our extensive evaluation of various LMs shows that while these models exhibit considerable potential in recalling factual information, their ability to capture intricate topological and semantic traits of KGs remains significantly constrained. We note that our proposed evaluation metrics are more reliable in evaluating these abilities than the existing metrics. Lastly, some of our benchmarks challenge the common notion that larger LMs (e.g., GPT-4) universally outshine their smaller counterparts (e.g., BERT).
Improved Robust ASR for Social Robots in Public Spaces
Jan 14, 2020
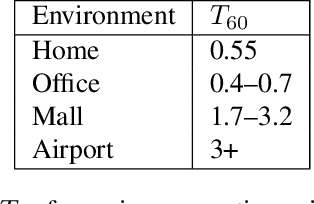

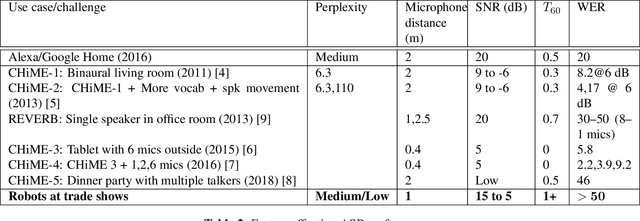
Social robots deployed in public spaces present a challenging task for ASR because of a variety of factors, including noise SNR of 20 to 5 dB. Existing ASR models perform well for higher SNRs in this range, but degrade considerably with more noise. This work explores methods for providing improved ASR performance in such conditions. We use the AiShell-1 Chinese speech corpus and the Kaldi ASR toolkit for evaluations. We were able to exceed state-of-the-art ASR performance with SNR lower than 20 dB, demonstrating the feasibility of achieving relatively high performing ASR with open-source toolkits and hundreds of hours of training data, which is commonly available.
Multi-Layer Ensembling Techniques for Multilingual Intent Classification
Jun 20, 2018
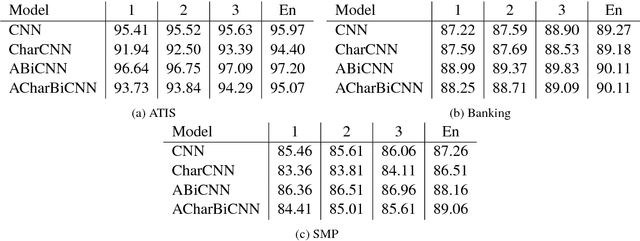
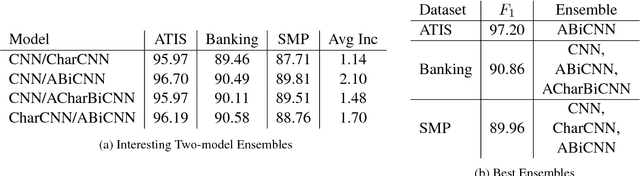
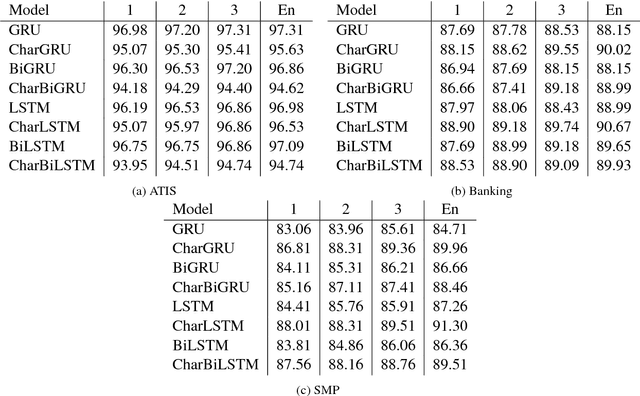
In this paper we determine how multi-layer ensembling improves performance on multilingual intent classification. We develop a novel multi-layer ensembling approach that ensembles both different model initializations and different model architectures. We also introduce a new banking domain dataset and compare results against the standard ATIS dataset and the Chinese SMP2017 dataset to determine ensembling performance in multilingual and multi-domain contexts. We run ensemble experiments across all three datasets, and conclude that ensembling provides significant performance increases, and that multi-layer ensembling is a no-risk way to improve performance on intent classification. We also find that a diverse ensemble of simple models can reach perform comparable to much more sophisticated state-of-the-art models. Our best F 1 scores on ATIS, Banking, and SMP are 97.54%, 91.79%, and 93.55% respectively, which compare well with the state-of-the-art on ATIS and best submission to the SMP2017 competition. The total ensembling performance increases we achieve are 0.23%, 1.96%, and 4.04% F 1 respectively.