 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Chinese Intent Classification by Dynamically Integrating Character Features into Word Embeddings with Ensemble Techniques
Paper and Code
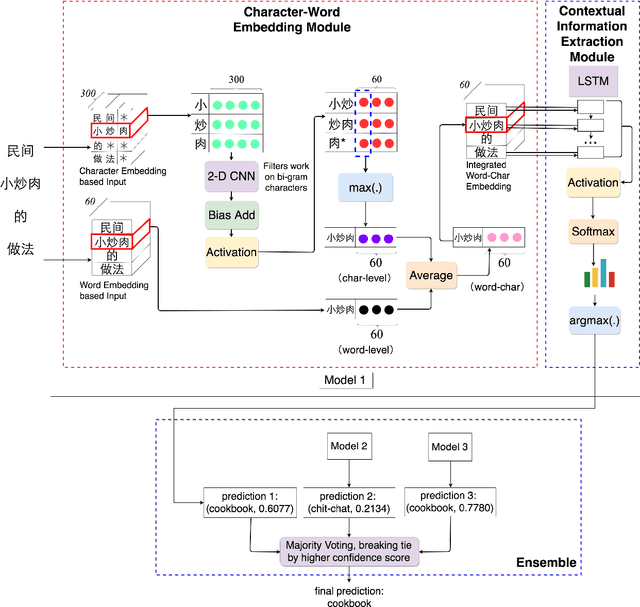


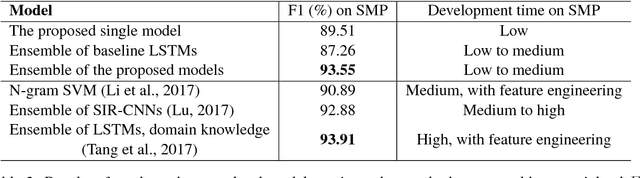
Intent classification has been widely researched on English data with deep learning approaches that are based on neural networks and word embeddings. The challenge for Chinese intent classification stems from the fact that, unlike English where most words are made up of 26 phonologic alphabet letters, Chinese is logographic, where a Chinese character is a more basic semantic unit that can be informative and its meaning does not vary too much in contexts. Chinese word embeddings alone can be inadequate for representing words, and pre-trained embeddings can suffer from not aligning well with the task at hand. To account for the inadequacy and leverage Chinese character information, we propose a low-effort and generic way to dynamically integrate character embedding based feature maps with word embedding based inputs, whose resulting word-character embeddings are stacked with a contextual information extraction module to further incorporate context information for predictions. On top of the proposed model, we employ an ensemble method to combine single models and obtain the final result. The approach is data-independent without relying on external sources like pre-trained word embeddings. The proposed model outperforms baseline models and existing methods.