 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREPA Works Until It Doesn't: Early-Stopped, Holistic Alignment Supercharges Diffusion Training
May 22, 2025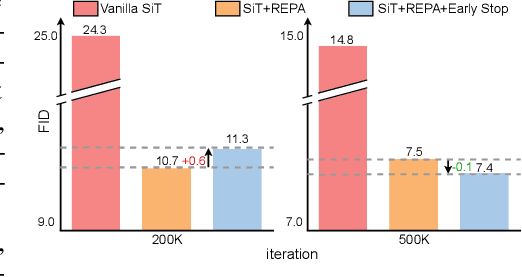
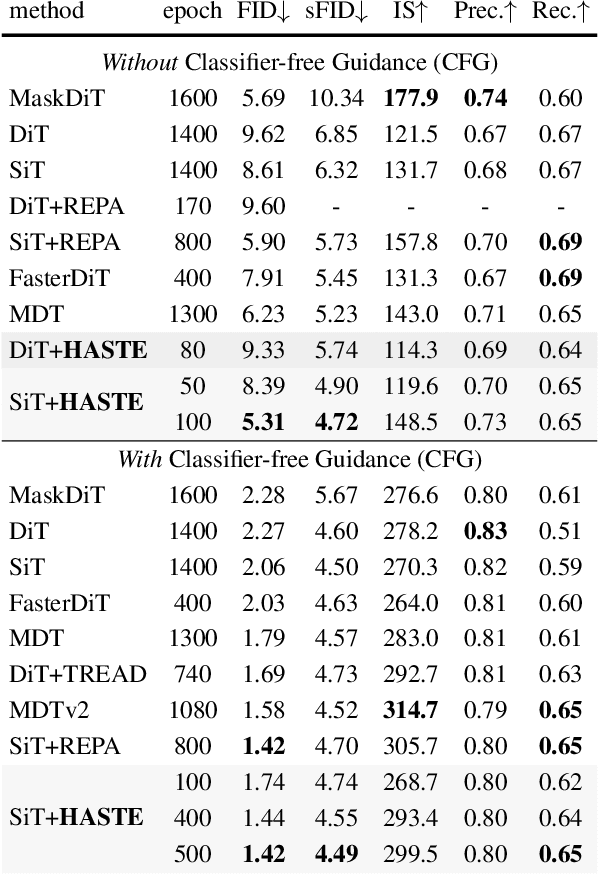

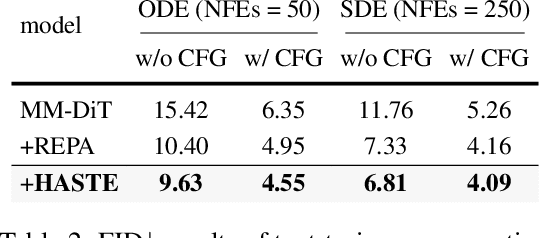
Diffusion Transformers (DiTs) deliver state-of-the-art image quality, yet their training remains notoriously slow. A recent remedy -- representation alignment (REPA) that matches DiT hidden features to those of a non-generative teacher (e.g. DINO) -- dramatically accelerates the early epochs but plateaus or even degrades performance later. We trace this failure to a capacity mismatch: once the generative student begins modelling the joint data distribution, the teacher's lower-dimensional embeddings and attention patterns become a straitjacket rather than a guide. We then introduce HASTE (Holistic Alignment with Stage-wise Termination for Efficient training), a two-phase schedule that keeps the help and drops the hindrance. Phase I applies a holistic alignment loss that simultaneously distills attention maps (relational priors) and feature projections (semantic anchors) from the teacher into mid-level layers of the DiT, yielding rapid convergence. Phase II then performs one-shot termination that deactivates the alignment loss, once a simple trigger such as a fixed iteration is hit, freeing the DiT to focus on denoising and exploit its generative capacity. HASTE speeds up training of diverse DiTs without architecture changes. On ImageNet 256X256, it reaches the vanilla SiT-XL/2 baseline FID in 50 epochs and matches REPA's best FID in 500 epochs, amounting to a 28X reduction in optimization steps. HASTE also improves text-to-image DiTs on MS-COCO, demonstrating to be a simple yet principled recipe for efficient diffusion training across various tasks. Our code is available at https://github.com/NUS-HPC-AI-Lab/HASTE .
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Dynamic Vision Mamba
Apr 07, 2025



Mamba-based vision models have gained extensive attention as a result of being computationally more efficient than attention-based models. However, spatial redundancy still exists in these models, represented by token and block redundancy. For token redundancy, we analytically find that early token pruning methods will result in inconsistency between training and inference or introduce extra computation for inference. Therefore, we customize token pruning to fit the Mamba structure by rearranging the pruned sequence before feeding it into the next Mamba block. For block redundancy, we allow each image to select SSM blocks dynamically based on an empirical observation that the inference speed of Mamba-based vision models is largely affected by the number of SSM blocks. Our proposed method, Dynamic Vision Mamba (DyVM), effectively reduces FLOPs with minor performance drops. We achieve a reduction of 35.2\% FLOPs with only a loss of accuracy of 1.7\% on Vim-S. It also generalizes well across different Mamba vision model architectures and different vision tasks. Our code will be made public.
Enhance-A-Video: Better Generated Video for Free
Feb 11, 2025



DiT-based video generation has achieved remarkable results, but research into enhancing existing models remains relatively unexplored. In this work, we introduce a training-free approach to enhance the coherence and quality of DiT-based generated videos, named Enhance-A-Video. The core idea is enhancing the cross-frame correlations based on non-diagonal temporal attention distributions. Thanks to its simple design, our approach can be easily applied to most DiT-based video generation frameworks without any retraining or fine-tuning. Across various DiT-based video generation models, our approach demonstrates promising improvements in both temporal consistency and visual quality. We hope this research can inspire future explorations in video generation enhancement.
Faster Vision Mamba is Rebuilt in Minutes via Merged Token Re-training
Dec 17, 2024



Vision Mamba (e.g., Vim) has successfully been integrated into computer vision, and token reduction has yielded promising outcomes in Vision Transformers (ViTs). However, token reduction performs less effectively on Vision Mamba compared to ViTs. Pruning informative tokens in Mamba leads to a high loss of key knowledge and bad performance. This makes it not a good solution for enhancing efficiency in Mamba. Token merging, which preserves more token information than pruning, has demonstrated commendable performance in ViTs. Nevertheless, vanilla merging performance decreases as the reduction ratio increases either, failing to maintain the key knowledge in Mamba. Re-training the token-reduced model enhances the performance of Mamba, by effectively rebuilding the key knowledge. Empirically, pruned Vims only drop up to 0.9% accuracy on ImageNet-1K, recovered by our proposed framework R-MeeTo in our main evaluation. We show how simple and effective the fast recovery can be achieved at minute-level, in particular, a 35.9% accuracy spike over 3 epochs of training on Vim-Ti. Moreover, Vim-Ti/S/B are re-trained within 5/7/17 minutes, and Vim-S only drop 1.3% with 1.2x (up to 1.5x) speed up in inference.
Real-Time Video Generation with Pyramid Attention Broadcast
Aug 22, 2024



We present Pyramid Attention Broadcast (PAB), a real-time, high quality and training-free approach for DiT-based video generation. Our method is founded on the observation that attention difference in the diffusion process exhibits a U-shaped pattern, indicating significant redundancy. We mitigate this by broadcasting attention outputs to subsequent steps in a pyramid style. It applies different broadcast strategies to each attention based on their variance for best efficiency. We further introduce broadcast sequence parallel for more efficient distributed inference. PAB demonstrates superior results across three models compared to baselines, achieving real-time generation for up to 720p videos. We anticipate that our simple yet effective method will serve as a robust baseline and facilitate future research and application for video generation.
DSP: Dynamic Sequence Parallelism for Multi-Dimensional Transformers
Mar 15, 2024



Scaling large models with long sequences across applications like language generation, video generation and multimodal tasks requires efficient sequence parallelism. However, existing sequence parallelism methods all assume a single sequence dimension and fail to adapt to multi-dimensional transformer architectures that perform attention calculations across different dimensions. This paper introduces Dynamic Sequence Parallelism (DSP), a novel approach to enable efficient sequence parallelism for multi-dimensional transformer models. The key idea is to dynamically switch the parallelism dimension according to the current computation stage, leveraging the potential characteristics of multi-dimensional attention. This dynamic dimension switching allows sequence parallelism with minimal communication overhead compared to applying traditional single-dimension parallelism to multi-dimensional models. Experiments show DSP improves end-to-end throughput by 42.0% to 216.8% over prior sequence parallelism methods.
AutoChunk: Automated Activation Chunk for Memory-Efficient Long Sequence Inference
Jan 19, 2024



Large deep learning models have achieved impressive performance across a range of applications. However, their large memory requirements, including parameter memory and activation memory, have become a significant challenge for their practical serving. While existing methods mainly address parameter memory, the importance of activation memory has been overlooked. Especially for long input sequences, activation memory is expected to experience a significant exponential growth as the length of sequences increases. In this approach, we propose AutoChunk, an automatic and adaptive compiler system that efficiently reduces activation memory for long sequence inference by chunk strategies. The proposed system generates chunk plans by optimizing through multiple stages. In each stage, the chunk search pass explores all possible chunk candidates and the chunk selection pass identifies the optimal one. At runtime, AutoChunk employs code generation to automatically apply chunk strategies. The experiments demonstrate that AutoChunk can reduce over 80\% of activation memory while maintaining speed loss within 10%, extend max sequence length by 3.2x to 11.7x, and outperform state-of-the-art methods by a large margin.