 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncated Proximal Policy Optimization
Jun 18, 2025



Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
LLM-BT: Performing Robotic Adaptive Tasks based on Large Language Models and Behavior Trees
Apr 08, 2024



Large Language Models (LLMs) have been widely utilized to perform complex robotic tasks. However, handling external disturbances during tasks is still an open challenge. This paper proposes a novel method to achieve robotic adaptive tasks based on LLMs and Behavior Trees (BTs). It utilizes ChatGPT to reason the descriptive steps of tasks. In order to enable ChatGPT to understand the environment, semantic maps are constructed by an object recognition algorithm. Then, we design a Parser module based on Bidirectional Encoder Representations from Transformers (BERT) to parse these steps into initial BTs. Subsequently, a BTs Update algorithm is proposed to expand the initial BTs dynamically to control robots to perform adaptive tasks. Different from other LLM-based methods for complex robotic tasks, our method outputs variable BTs that can add and execute new actions according to environmental changes, which is robust to external disturbances. Our method is validated with simulation in different practical scenarios.
AutoChunk: Automated Activation Chunk for Memory-Efficient Long Sequence Inference
Jan 19, 2024



Large deep learning models have achieved impressive performance across a range of applications. However, their large memory requirements, including parameter memory and activation memory, have become a significant challenge for their practical serving. While existing methods mainly address parameter memory, the importance of activation memory has been overlooked. Especially for long input sequences, activation memory is expected to experience a significant exponential growth as the length of sequences increases. In this approach, we propose AutoChunk, an automatic and adaptive compiler system that efficiently reduces activation memory for long sequence inference by chunk strategies. The proposed system generates chunk plans by optimizing through multiple stages. In each stage, the chunk search pass explores all possible chunk candidates and the chunk selection pass identifies the optimal one. At runtime, AutoChunk employs code generation to automatically apply chunk strategies. The experiments demonstrate that AutoChunk can reduce over 80\% of activation memory while maintaining speed loss within 10%, extend max sequence length by 3.2x to 11.7x, and outperform state-of-the-art methods by a large margin.
LoBaSS: Gauging Learnability in Supervised Fine-tuning Data
Oct 16, 2023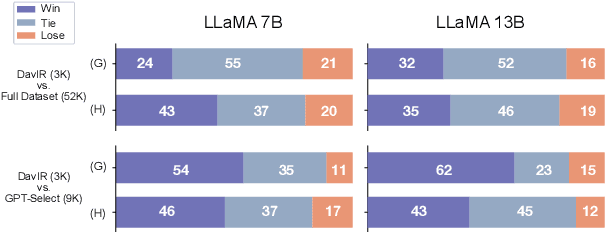
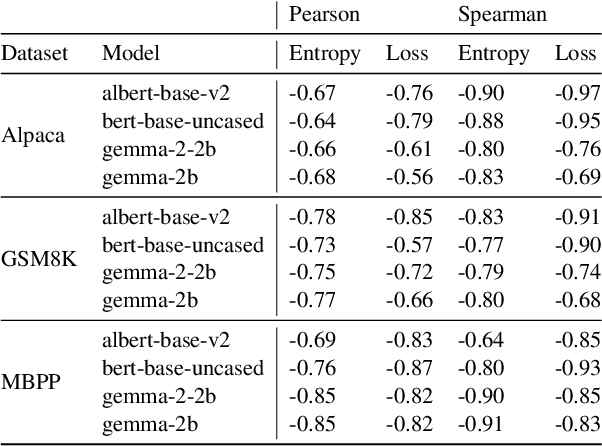
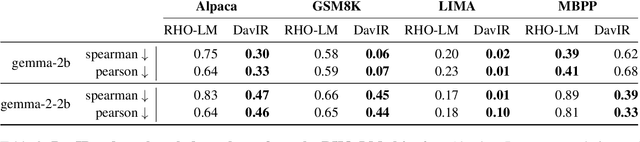
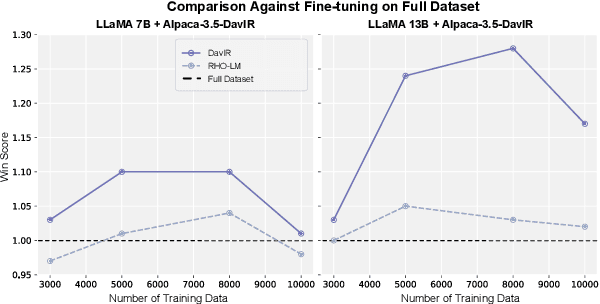
Supervised Fine-Tuning (SFT) serves as a crucial phase in aligning Large Language Models (LLMs) to specific task prerequisites. The selection of fine-tuning data profoundly influences the model's performance, whose principle is traditionally grounded in data quality and distribution. In this paper, we introduce a new dimension in SFT data selection: learnability. This new dimension is motivated by the intuition that SFT unlocks capabilities acquired by a LLM during the pretraining phase. Given that different pretrained models have disparate capabilities, the SFT data appropriate for one may not suit another. Thus, we introduce the term learnability to define the suitability of data for effective learning by the model. We present the Loss Based SFT Data Selection (LoBaSS) method, utilizing data learnability as the principal criterion for the selection SFT data. This method provides a nuanced approach, allowing the alignment of data selection with inherent model capabilities, ensuring optimal compatibility and learning efficiency. In experimental comparisons involving 7B and 13B models, our LoBaSS method is able to surpass full-data fine-tuning at merely 6% of the total training data. When employing 16.7% of the data, LoBaSS harmonizes the model's capabilities across conversational and mathematical domains, proving its efficacy and adaptability.
Let's reward step by step: Step-Level reward model as the Navigators for Reasoning
Oct 16, 2023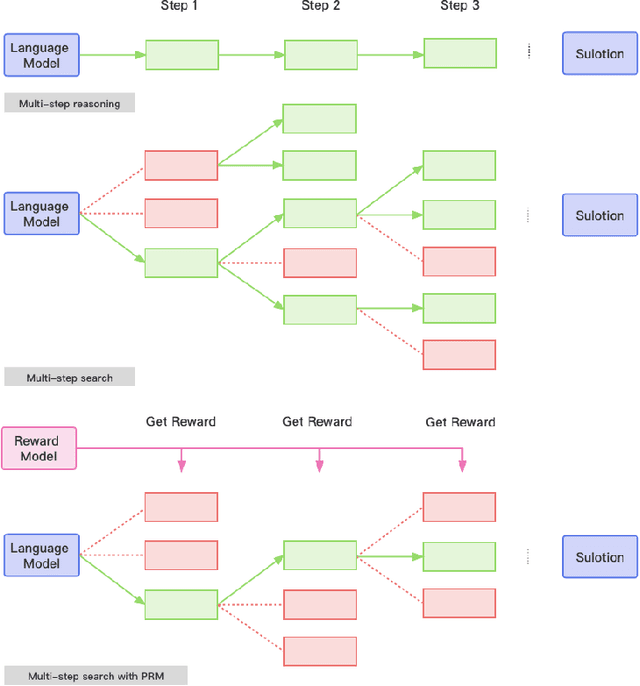

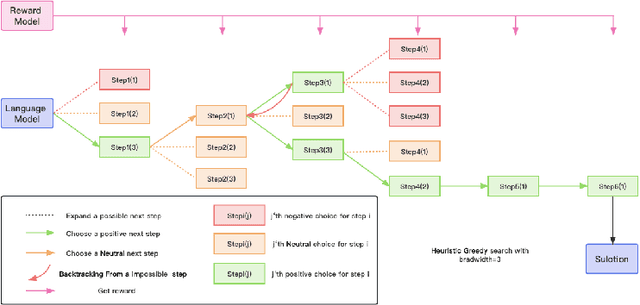

Recent years have seen considerable advancements in multi-step reasoning with Large Language Models (LLMs). The previous studies have elucidated the merits of integrating feedback or search mechanisms during model inference to improve the reasoning accuracy. The Process-Supervised Reward Model (PRM), typically furnishes LLMs with step-by-step feedback during the training phase, akin to Proximal Policy Optimization (PPO) or reject sampling. Our objective is to examine the efficacy of PRM in the inference phase to help discern the optimal solution paths for multi-step tasks such as mathematical reasoning and code generation. To this end, we propose a heuristic greedy search algorithm that employs the step-level feedback from PRM to optimize the reasoning pathways explored by LLMs. This tailored PRM demonstrated enhanced results compared to the Chain of Thought (CoT) on mathematical benchmarks like GSM8K and MATH. Additionally, to explore the versatility of our approach, we develop a novel method to automatically generate step-level reward dataset for coding tasks and observed similar improved performance in the code generation tasks. Thus highlighting the robust nature of our reward-model-based approach to inference for reasoning tasks.