 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Uncertainty-Aware Objective for Language Model Post-Training
Mar 15, 2025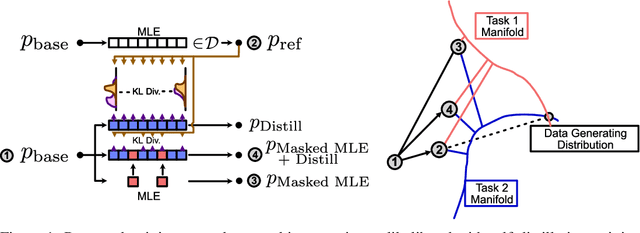
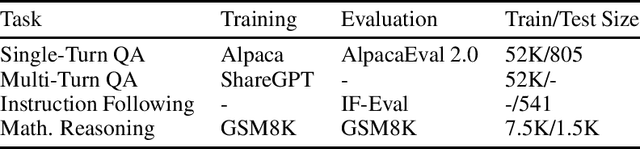
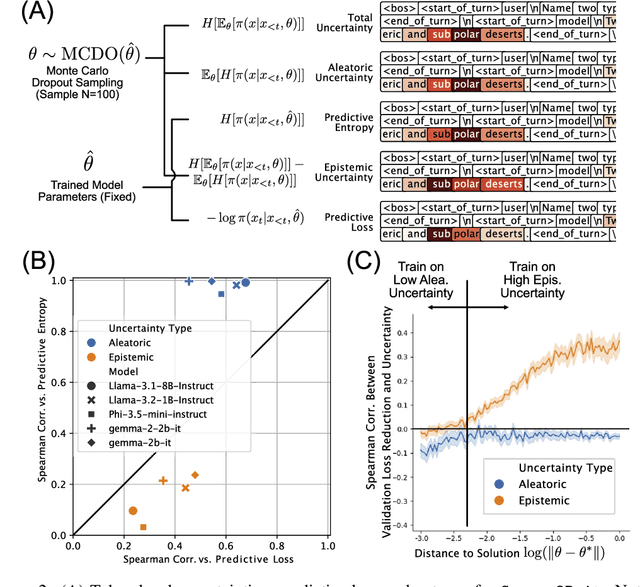
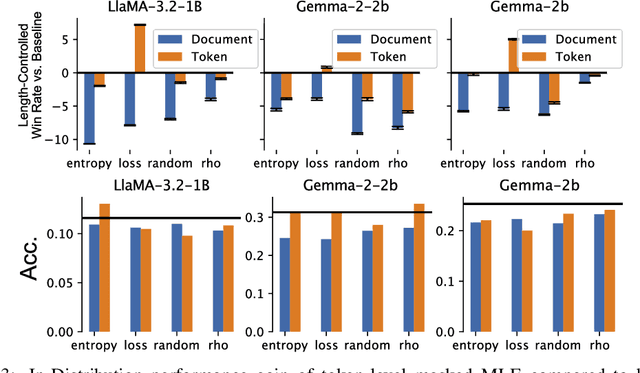
In the current work, we connect token-level uncertainty in causal language modeling to two types of training objectives: 1) masked maximum likelihood (MLE), 2) self-distillation. We show that masked MLE is effective in reducing epistemic uncertainty, and serve as an effective token-level automatic curriculum learning technique. However, masked MLE is prone to overfitting and requires self-distillation regularization to improve or maintain performance on out-of-distribution tasks. We demonstrate significant performance gain via the proposed training objective - combined masked MLE and self-distillation - across multiple architectures (Gemma, LLaMA, Phi) and datasets (Alpaca, ShareGPT, GSM8K), mitigating overfitting while maintaining adaptability during post-training. Our findings suggest that uncertainty-aware training provides an effective mechanism for enhancing language model training.
ElastiFormer: Learned Redundancy Reduction in Transformer via Self-Distillation
Nov 22, 2024



We introduce ElastiFormer, a post-training technique that adapts pretrained Transformer models into an elastic counterpart with variable inference time compute. ElastiFormer introduces small routing modules (as low as .00006% additional trainable parameters) to dynamically selects subsets of network parameters and input tokens to be processed by each layer of the pretrained network in an inputdependent manner. The routing modules are trained using self-distillation losses to minimize the differences between the output of the pretrained-model and their elastic counterparts. As ElastiFormer makes no assumption regarding the modality of the pretrained Transformer model, it can be readily applied to all modalities covering causal language modeling, image modeling as well as visual-language modeling tasks. We show that 20% to 50% compute saving could be achieved for different components of the transformer layer, which could be further reduced by adding very low rank LoRA weights (rank 1) trained via the same distillation objective. Finally, by comparing routing trained on different subsets of ImageNet, we show that ElastiFormer is robust against the training domain.
BabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.
LoBaSS: Gauging Learnability in Supervised Fine-tuning Data
Oct 16, 2023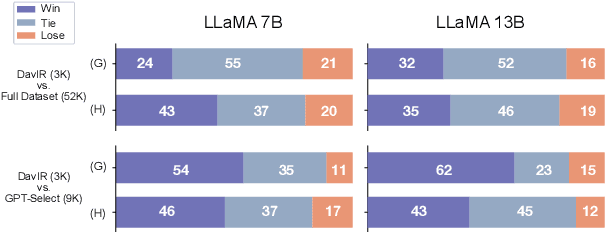
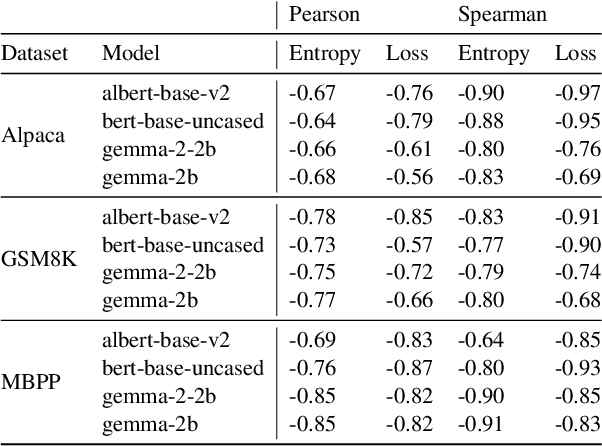
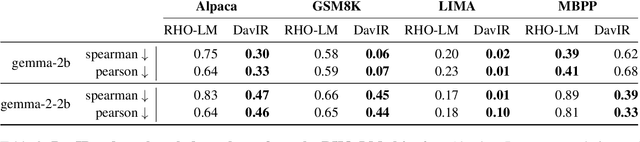
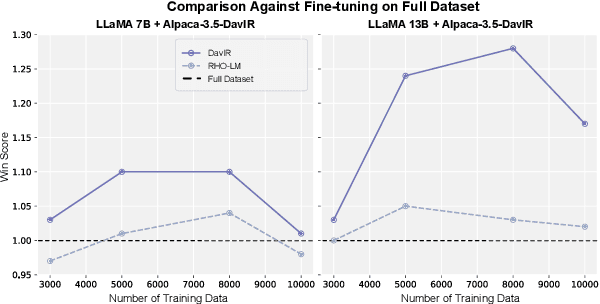
Supervised Fine-Tuning (SFT) serves as a crucial phase in aligning Large Language Models (LLMs) to specific task prerequisites. The selection of fine-tuning data profoundly influences the model's performance, whose principle is traditionally grounded in data quality and distribution. In this paper, we introduce a new dimension in SFT data selection: learnability. This new dimension is motivated by the intuition that SFT unlocks capabilities acquired by a LLM during the pretraining phase. Given that different pretrained models have disparate capabilities, the SFT data appropriate for one may not suit another. Thus, we introduce the term learnability to define the suitability of data for effective learning by the model. We present the Loss Based SFT Data Selection (LoBaSS) method, utilizing data learnability as the principal criterion for the selection SFT data. This method provides a nuanced approach, allowing the alignment of data selection with inherent model capabilities, ensuring optimal compatibility and learning efficiency. In experimental comparisons involving 7B and 13B models, our LoBaSS method is able to surpass full-data fine-tuning at merely 6% of the total training data. When employing 16.7% of the data, LoBaSS harmonizes the model's capabilities across conversational and mathematical domains, proving its efficacy and adaptability.
Let's reward step by step: Step-Level reward model as the Navigators for Reasoning
Oct 16, 2023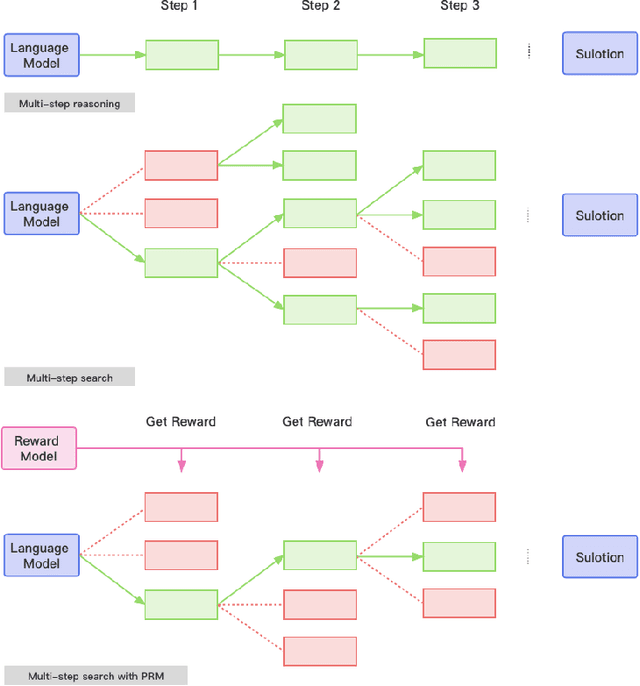

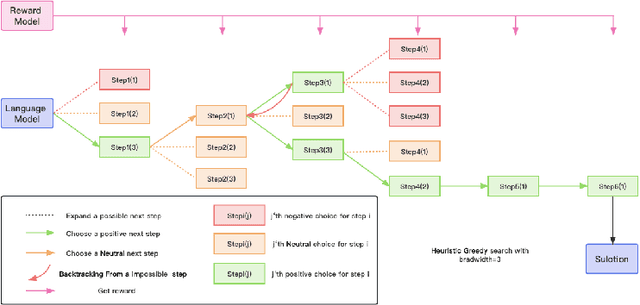

Recent years have seen considerable advancements in multi-step reasoning with Large Language Models (LLMs). The previous studies have elucidated the merits of integrating feedback or search mechanisms during model inference to improve the reasoning accuracy. The Process-Supervised Reward Model (PRM), typically furnishes LLMs with step-by-step feedback during the training phase, akin to Proximal Policy Optimization (PPO) or reject sampling. Our objective is to examine the efficacy of PRM in the inference phase to help discern the optimal solution paths for multi-step tasks such as mathematical reasoning and code generation. To this end, we propose a heuristic greedy search algorithm that employs the step-level feedback from PRM to optimize the reasoning pathways explored by LLMs. This tailored PRM demonstrated enhanced results compared to the Chain of Thought (CoT) on mathematical benchmarks like GSM8K and MATH. Additionally, to explore the versatility of our approach, we develop a novel method to automatically generate step-level reward dataset for coding tasks and observed similar improved performance in the code generation tasks. Thus highlighting the robust nature of our reward-model-based approach to inference for reasoning tasks.
Video-Teller: Enhancing Cross-Modal Generation with Fusion and Decoupling
Oct 11, 2023This paper proposes Video-Teller, a video-language foundation model that leverages multi-modal fusion and fine-grained modality alignment to significantly enhance the video-to-text generation task. Video-Teller boosts the training efficiency by utilizing frozen pretrained vision and language modules. It capitalizes on the robust linguistic capabilities of large language models, enabling the generation of both concise and elaborate video descriptions. To effectively integrate visual and auditory information, Video-Teller builds upon the image-based BLIP-2 model and introduces a cascaded Q-Former which fuses information across frames and ASR texts. To better guide video summarization, we introduce a fine-grained modality alignment objective, where the cascaded Q-Former's output embedding is trained to align with the caption/summary embedding created by a pretrained text auto-encoder. Experimental results demonstrate the efficacy of our proposed video-language foundation model in accurately comprehending videos and generating coherent and precise language descriptions. It is worth noting that the fine-grained alignment enhances the model's capabilities (4% improvement of CIDEr score on MSR-VTT) with only 13% extra parameters in training and zero additional cost in inference.
Video-CSR: Complex Video Digest Creation for Visual-Language Models
Oct 08, 2023



We present a novel task and human annotated dataset for evaluating the ability for visual-language models to generate captions and summaries for real-world video clips, which we call Video-CSR (Captioning, Summarization and Retrieval). The dataset contains 4.8K YouTube video clips of 20-60 seconds in duration and covers a wide range of topics and interests. Each video clip corresponds to 5 independently annotated captions (1 sentence) and summaries (3-10 sentences). Given any video selected from the dataset and its corresponding ASR information, we evaluate visual-language models on either caption or summary generation that is grounded in both the visual and auditory content of the video. Additionally, models are also evaluated on caption- and summary-based retrieval tasks, where the summary-based retrieval task requires the identification of a target video given excerpts of a corresponding summary. Given the novel nature of the paragraph-length video summarization task, we perform extensive comparative analyses of different existing evaluation metrics and their alignment with human preferences. Finally, we propose a foundation model with competitive generation and retrieval capabilities that serves as a baseline for the Video-CSR task. We aim for Video-CSR to serve as a useful evaluation set in the age of large language models and complex multi-modal tasks.
SimVLG: Simple and Efficient Pretraining of Visual Language Generative Models
Oct 07, 2023



In this paper, we propose ``SimVLG'', a streamlined framework for the pre-training of computationally intensive vision-language generative models, leveraging frozen pre-trained large language models (LLMs). The prevailing paradigm in vision-language pre-training (VLP) typically involves a two-stage optimization process: an initial resource-intensive phase dedicated to general-purpose vision-language representation learning, aimed at extracting and consolidating pertinent visual features, followed by a subsequent phase focusing on end-to-end alignment between visual and linguistic modalities. Our one-stage, single-loss framework circumvents the aforementioned computationally demanding first stage of training by gradually merging similar visual tokens during training. This gradual merging process effectively compacts the visual information while preserving the richness of semantic content, leading to fast convergence without sacrificing performance. Our experiments show that our approach can speed up the training of vision-language models by a factor $\times 5$ without noticeable impact on the overall performance. Additionally, we show that our models can achieve comparable performance to current vision-language models with only $1/10$ of the data. Finally, we demonstrate how our image-text models can be easily adapted to video-language generative tasks through a novel soft attentive temporal token merging modules.