 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Image-Text Models are Secretly Video Captioners
Feb 19, 2025Developing video captioning models is computationally expensive. The dynamic nature of video also complicates the design of multimodal models that can effectively caption these sequences. However, we find that by using minimal computational resources and without complex modifications to address video dynamics, an image-based model can be repurposed to outperform several specialised video captioning systems. Our adapted model demonstrates top tier performance on major benchmarks, ranking 2nd on MSRVTT and MSVD, and 3rd on VATEX. We transform it into a competitive video captioner by post training a typical image captioning model BLIP2 with only 6,000 video text pairs and simply concatenating frames (significantly fewer data than other methods), which use 2.5 to 144 million pairs. From a resource optimization perspective, this video captioning study focuses on three fundamental factors: optimizing model scale, maximizing data efficiency, and incorporating reinforcement learning. This extensive study demonstrates that a lightweight, image based adaptation strategy can rival state-of-the-art video captioning systems, offering a practical solution for low-resource scenarios.
SimVLG: Simple and Efficient Pretraining of Visual Language Generative Models
Oct 07, 2023



In this paper, we propose ``SimVLG'', a streamlined framework for the pre-training of computationally intensive vision-language generative models, leveraging frozen pre-trained large language models (LLMs). The prevailing paradigm in vision-language pre-training (VLP) typically involves a two-stage optimization process: an initial resource-intensive phase dedicated to general-purpose vision-language representation learning, aimed at extracting and consolidating pertinent visual features, followed by a subsequent phase focusing on end-to-end alignment between visual and linguistic modalities. Our one-stage, single-loss framework circumvents the aforementioned computationally demanding first stage of training by gradually merging similar visual tokens during training. This gradual merging process effectively compacts the visual information while preserving the richness of semantic content, leading to fast convergence without sacrificing performance. Our experiments show that our approach can speed up the training of vision-language models by a factor $\times 5$ without noticeable impact on the overall performance. Additionally, we show that our models can achieve comparable performance to current vision-language models with only $1/10$ of the data. Finally, we demonstrate how our image-text models can be easily adapted to video-language generative tasks through a novel soft attentive temporal token merging modules.
Bootstrapping Vision-Language Learning with Decoupled Language Pre-training
Jul 13, 2023
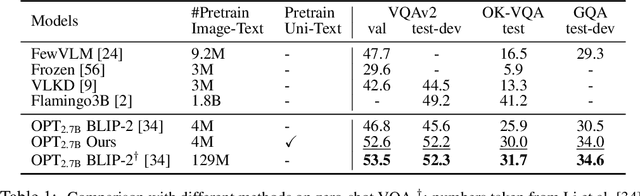

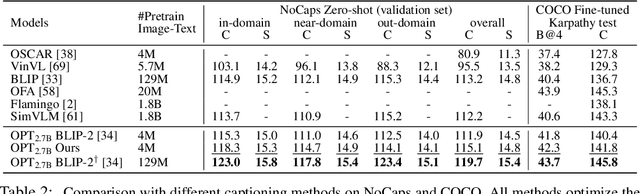
We present a novel methodology aimed at optimizing the application of frozen large language models (LLMs) for resource-intensive vision-language (VL) pre-training. The current paradigm uses visual features as prompts to guide language models, with a focus on determining the most relevant visual features for corresponding text. Our approach diverges by concentrating on the language component, specifically identifying the optimal prompts to align with visual features. We introduce the Prompt-Transformer (P-Former), a model that predicts these ideal prompts, which is trained exclusively on linguistic data, bypassing the need for image-text pairings. This strategy subtly bifurcates the end-to-end VL training process into an additional, separate stage. Our experiments reveal that our framework significantly enhances the performance of a robust image-to-text baseline (BLIP-2), and effectively narrows the performance gap between models trained with either 4M or 129M image-text pairs. Importantly, our framework is modality-agnostic and flexible in terms of architectural design, as validated by its successful application in a video learning task using varied base modules. The code is available at https://github.com/yiren-jian/BLIText
Knowledge from Large-Scale Protein Contact Prediction Models Can Be Transferred to the Data-Scarce RNA Contact Prediction Task
Feb 13, 2023RNA, whose functionality is largely determined by its structure, plays an important role in many biological activities. The prediction of pairwise structural proximity between each nucleotide of an RNA sequence can characterize the structural information of the RNA. Historically, this problem has been tackled by machine learning models using expert-engineered features and trained on scarce labeled datasets. Here, we find that the knowledge learned by a protein-coevolution Transformer-based deep neural network can be transferred to the RNA contact prediction task. As protein datasets are orders of magnitude larger than those for RNA contact prediction, our findings and the subsequent framework greatly reduce the data scarcity bottleneck. Experiments confirm that RNA contact prediction through transfer learning using a publicly available protein model is greatly improved. Our findings indicate that the learned structural patterns of proteins can be transferred to RNAs, opening up potential new avenues for research.
Non-Linguistic Supervision for Contrastive Learning of Sentence Embeddings
Sep 20, 2022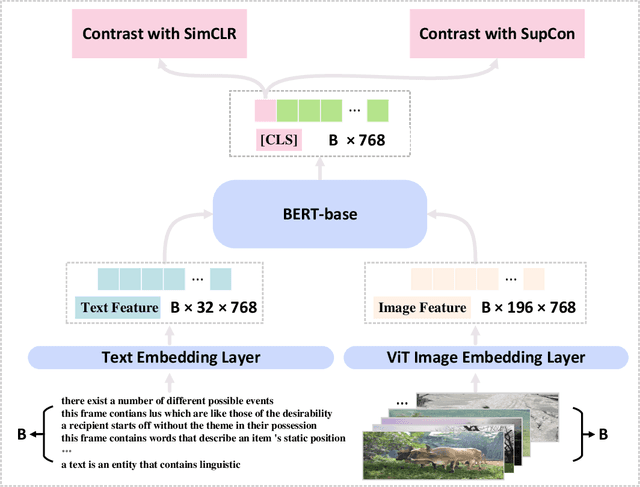
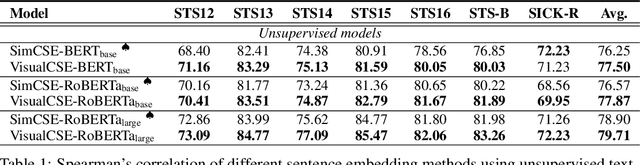
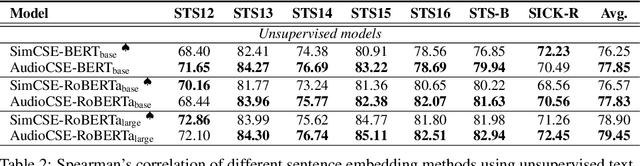

Semantic representation learning for sentences is an important and well-studied problem in NLP. The current trend for this task involves training a Transformer-based sentence encoder through a contrastive objective with text, i.e., clustering sentences with semantically similar meanings and scattering others. In this work, we find the performance of Transformer models as sentence encoders can be improved by training with multi-modal multi-task losses, using unpaired examples from another modality (e.g., sentences and unrelated image/audio data). In particular, besides learning by the contrastive loss on text, our model clusters examples from a non-linguistic domain (e.g., visual/audio) with a similar contrastive loss at the same time. The reliance of our framework on unpaired non-linguistic data makes it language-agnostic, enabling it to be widely applicable beyond English NLP. Experiments on 7 semantic textual similarity benchmarks reveal that models trained with the additional non-linguistic (images/audio) contrastive objective lead to higher quality sentence embeddings. This indicates that Transformer models are able to generalize better by doing a similar task (i.e., clustering) with unpaired examples from different modalities in a multi-task fashion.
Contrastive Learning for Prompt-Based Few-Shot Language Learners
May 03, 2022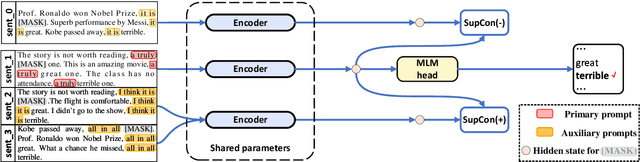
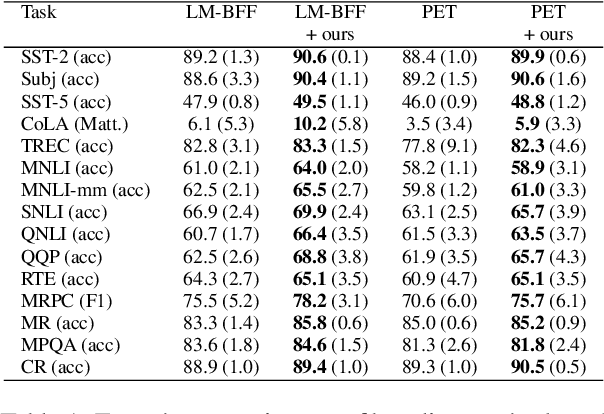
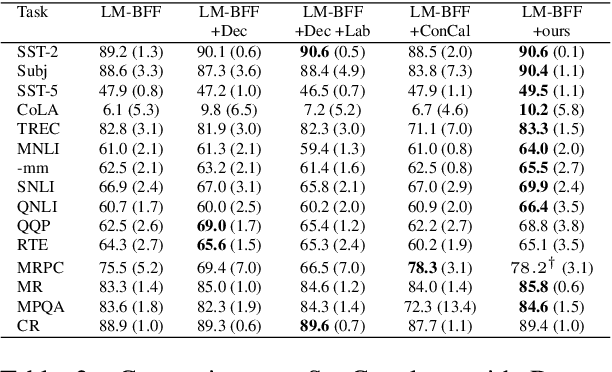
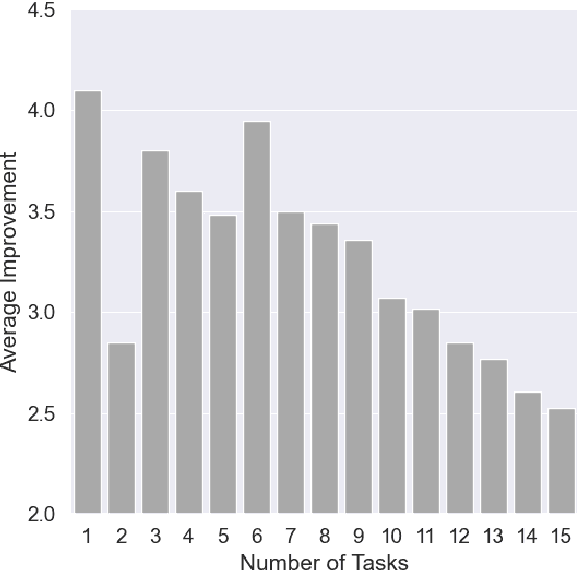
The impressive performance of GPT-3 using natural language prompts and in-context learning has inspired work on better fine-tuning of moderately-sized models under this paradigm. Following this line of work, we present a contrastive learning framework that clusters inputs from the same class for better generality of models trained with only limited examples. Specifically, we propose a supervised contrastive framework that clusters inputs from the same class under different augmented "views" and repel the ones from different classes. We create different "views" of an example by appending it with different language prompts and contextual demonstrations. Combining a contrastive loss with the standard masked language modeling (MLM) loss in prompt-based few-shot learners, the experimental results show that our method can improve over the state-of-the-art methods in a diverse set of 15 language tasks. Our framework makes minimal assumptions on the task or the base model, and can be applied to many recent methods with little modification. The code will be made available at: https://github.com/yiren-jian/LM-SupCon.
Embedding Hallucination for Few-Shot Language Fine-tuning
May 03, 2022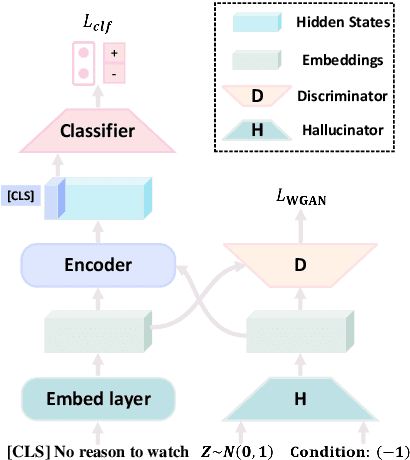
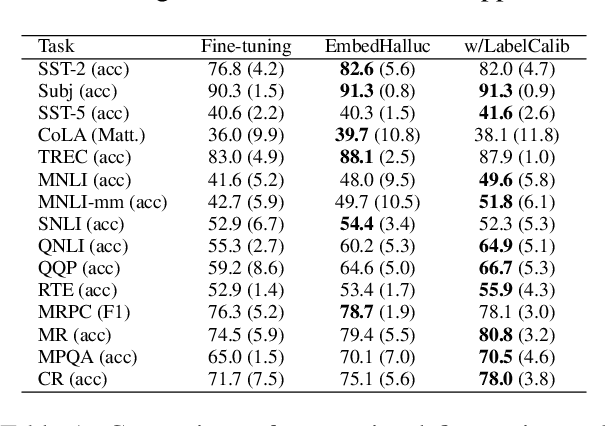
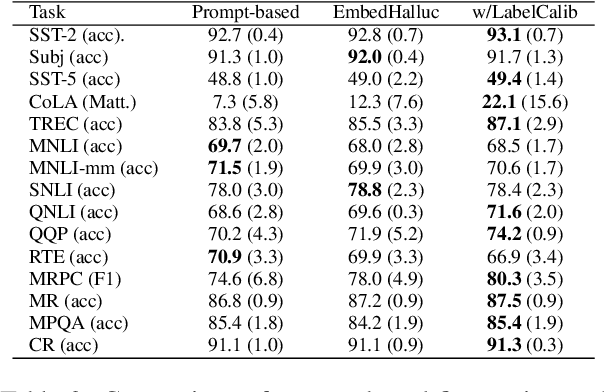
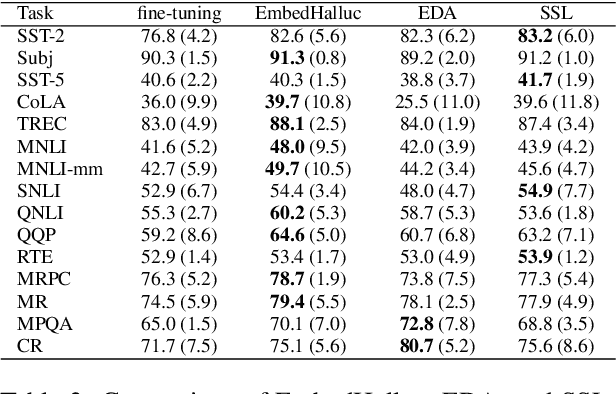
Few-shot language learners adapt knowledge from a pre-trained model to recognize novel classes from a few-labeled sentences. In such settings, fine-tuning a pre-trained language model can cause severe over-fitting. In this paper, we propose an Embedding Hallucination (EmbedHalluc) method, which generates auxiliary embedding-label pairs to expand the fine-tuning dataset. The hallucinator is trained by playing an adversarial game with the discriminator, such that the hallucinated embedding is indiscriminative to the real ones in the fine-tuning dataset. By training with the extended dataset, the language learner effectively learns from the diverse hallucinated embeddings to overcome the over-fitting issue. Experiments demonstrate that our proposed method is effective in a wide range of language tasks, outperforming current fine-tuning methods. Further, we show that EmbedHalluc outperforms other methods that address this over-fitting problem, such as common data augmentation, semi-supervised pseudo-labeling, and regularization. The code will be made available at: https://github.com/yiren-jian/EmbedHalluc.
Label Hallucination for Few-Shot Classification
Dec 06, 2021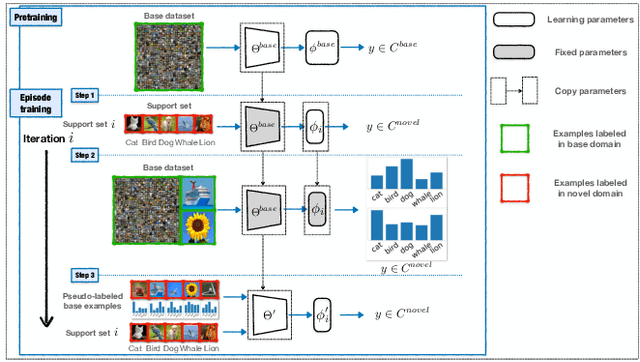
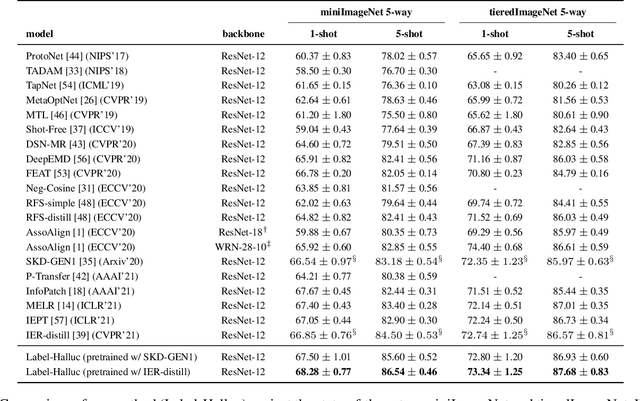
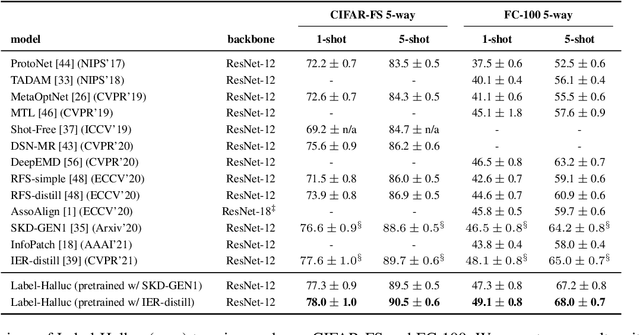
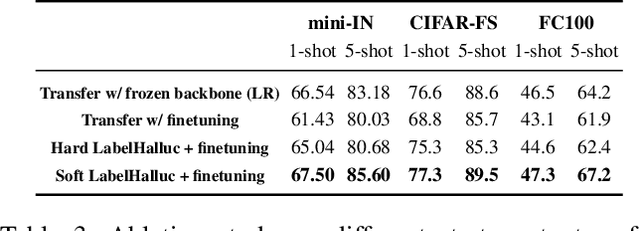
Few-shot classification requires adapting knowledge learned from a large annotated base dataset to recognize novel unseen classes, each represented by few labeled examples. In such a scenario, pretraining a network with high capacity on the large dataset and then finetuning it on the few examples causes severe overfitting. At the same time, training a simple linear classifier on top of "frozen" features learned from the large labeled dataset fails to adapt the model to the properties of the novel classes, effectively inducing underfitting. In this paper we propose an alternative approach to both of these two popular strategies. First, our method pseudo-labels the entire large dataset using the linear classifier trained on the novel classes. This effectively "hallucinates" the novel classes in the large dataset, despite the novel categories not being present in the base database (novel and base classes are disjoint). Then, it finetunes the entire model with a distillation loss on the pseudo-labeled base examples, in addition to the standard cross-entropy loss on the novel dataset. This step effectively trains the network to recognize contextual and appearance cues that are useful for the novel-category recognition but using the entire large-scale base dataset and thus overcoming the inherent data-scarcity problem of few-shot learning. Despite the simplicity of the approach, we show that that our method outperforms the state-of-the-art on four well-established few-shot classification benchmarks.
MetaPix: Domain Transfer for Semantic Segmentation by Meta Pixel Weighting
Oct 05, 2021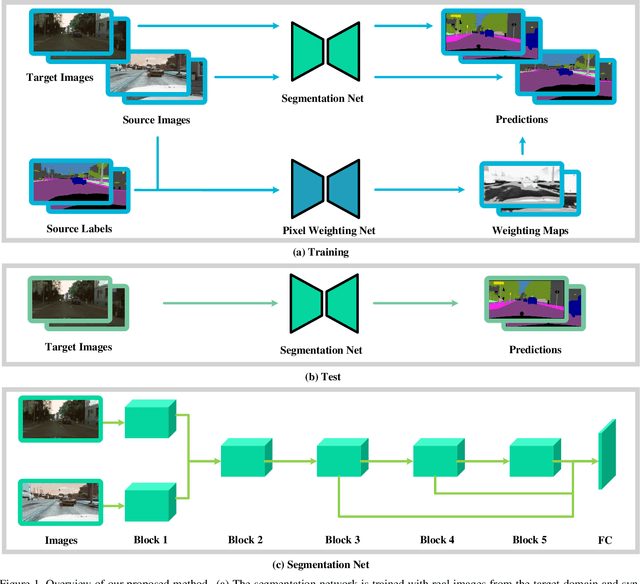
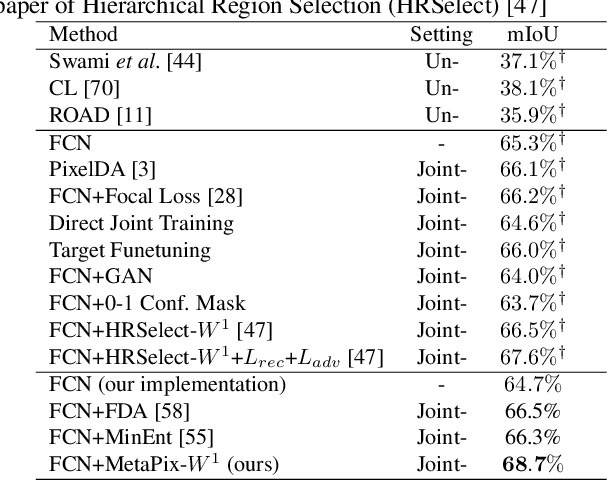
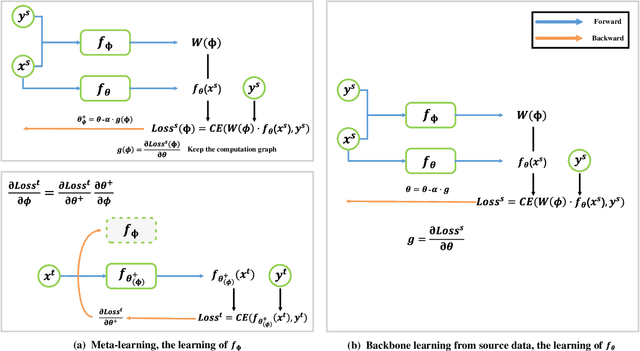
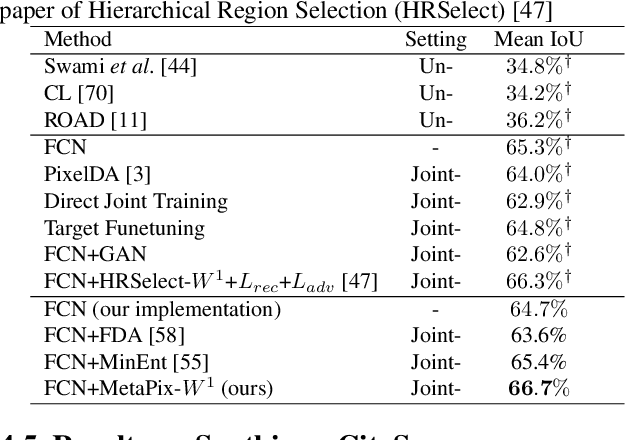
Training a deep neural model for semantic segmentation requires collecting a large amount of pixel-level labeled data. To alleviate the data scarcity problem presented in the real world, one could utilize synthetic data whose label is easy to obtain. Previous work has shown that the performance of a semantic segmentation model can be improved by training jointly with real and synthetic examples with a proper weighting on the synthetic data. Such weighting was learned by a heuristic to maximize the similarity between synthetic and real examples. In our work, we instead learn a pixel-level weighting of the synthetic data by meta-learning, i.e., the learning of weighting should only be minimizing the loss on the target task. We achieve this by gradient-on-gradient technique to propagate the target loss back into the parameters of the weighting model. The experiments show that our method with only one single meta module can outperform a complicated combination of an adversarial feature alignment, a reconstruction loss, plus a hierarchical heuristic weighting at pixel, region and image levels.