 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes a Good Curriculum? Disentangling the Effects of Data Ordering on LLM Mathematical Reasoning
Oct 21, 2025Curriculum learning (CL) - ordering training data from easy to hard - has become a popular strategy for improving reasoning in large language models (LLMs). Yet prior work employs disparate difficulty metrics and training setups, leaving open fundamental questions: When does curriculum help? Which direction - forward or reverse - is better? And does the answer depend on what we measure? We address these questions through a unified offline evaluation framework that decomposes curriculum difficulty into five complementary dimensions: Problem Difficulty, Model Surprisal, Confidence Margin, Predictive Uncertainty, and Decision Variability. Through controlled post-training experiments on mathematical reasoning benchmarks with Llama3.1-8B, Mistral-7B, and Gemma3-4B, we find that (i) no curriculum strategy dominates universally - the relative effectiveness of forward versus reverse CL depends jointly on model capability and task complexity; (ii) even within a single metric, samples at different difficulty levels produce distinct gains depending on task demands; and (iii) task-aligned curricula focus on shaping the model's final representations and generalization, whereas inner-state curricula modulate internal states such as confidence and uncertainty. Our findings challenge the notion of a universal curriculum strategy and offer actionable guidance across model and task regimes, with some metrics indicating that prioritizing decision-uncertain samples can further enhance learning outcomes.
SoundMind: RL-Incentivized Logic Reasoning for Audio-Language Models
Jun 15, 2025While large language models have shown reasoning capabilities, their application to the audio modality, particularly in large audio-language models (ALMs), remains significantly underdeveloped. Addressing this gap requires a systematic approach, involving a capable base model, high-quality reasoning-oriented audio data, and effective training algorithms. In this study, we present a comprehensive solution: we introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building on this resource, we propose SoundMind, a rule-based reinforcement learning (RL) algorithm tailored to endow ALMs with deep bimodal reasoning abilities. By training Qwen2.5-Omni-7B on the ALR dataset using SoundMind, our approach achieves state-of-the-art performance in audio logical reasoning. This work highlights the impact of combining high-quality, reasoning-focused datasets with specialized RL techniques, advancing the frontier of auditory intelligence in language models. Our code and the proposed dataset are available at https://github.com/xid32/SoundMind.
Music's Multimodal Complexity in AVQA: Why We Need More than General Multimodal LLMs
May 27, 2025While recent Multimodal Large Language Models exhibit impressive capabilities for general multimodal tasks, specialized domains like music necessitate tailored approaches. Music Audio-Visual Question Answering (Music AVQA) particularly underscores this, presenting unique challenges with its continuous, densely layered audio-visual content, intricate temporal dynamics, and the critical need for domain-specific knowledge. Through a systematic analysis of Music AVQA datasets and methods, this position paper identifies that specialized input processing, architectures incorporating dedicated spatial-temporal designs, and music-specific modeling strategies are critical for success in this domain. Our study provides valuable insights for researchers by highlighting effective design patterns empirically linked to strong performance, proposing concrete future directions for incorporating musical priors, and aiming to establish a robust foundation for advancing multimodal musical understanding. This work is intended to inspire broader attention and further research, supported by a continuously updated anonymous GitHub repository of relevant papers: https://github.com/xid32/Survey4MusicAVQA.
Scaled Supervision is an Implicit Lipschitz Regularizer
Mar 19, 2025In modern social media, recommender systems (RecSys) rely on the click-through rate (CTR) as the standard metric to evaluate user engagement. CTR prediction is traditionally framed as a binary classification task to predict whether a user will interact with a given item. However, this approach overlooks the complexity of real-world social modeling, where the user, item, and their interactive features change dynamically in fast-paced online environments. This dynamic nature often leads to model instability, reflected in overfitting short-term fluctuations rather than higher-level interactive patterns. While overfitting calls for more scaled and refined supervisions, current solutions often rely on binary labels that overly simplify fine-grained user preferences through the thresholding process, which significantly reduces the richness of the supervision. Therefore, we aim to alleviate the overfitting problem by increasing the supervision bandwidth in CTR training. Specifically, (i) theoretically, we formulate the impact of fine-grained preferences on model stability as a Lipschitz constrain; (ii) empirically, we discover that scaling the supervision bandwidth can act as an implicit Lipschitz regularizer, stably optimizing existing CTR models to achieve better generalizability. Extensive experiments show that this scaled supervision significantly and consistently improves the optimization process and the performance of existing CTR models, even without the need for additional hyperparameter tuning.
Pretrained Image-Text Models are Secretly Video Captioners
Feb 19, 2025Developing video captioning models is computationally expensive. The dynamic nature of video also complicates the design of multimodal models that can effectively caption these sequences. However, we find that by using minimal computational resources and without complex modifications to address video dynamics, an image-based model can be repurposed to outperform several specialised video captioning systems. Our adapted model demonstrates top tier performance on major benchmarks, ranking 2nd on MSRVTT and MSVD, and 3rd on VATEX. We transform it into a competitive video captioner by post training a typical image captioning model BLIP2 with only 6,000 video text pairs and simply concatenating frames (significantly fewer data than other methods), which use 2.5 to 144 million pairs. From a resource optimization perspective, this video captioning study focuses on three fundamental factors: optimizing model scale, maximizing data efficiency, and incorporating reinforcement learning. This extensive study demonstrates that a lightweight, image based adaptation strategy can rival state-of-the-art video captioning systems, offering a practical solution for low-resource scenarios.
Learning Musical Representations for Music Performance Question Answering
Feb 10, 2025


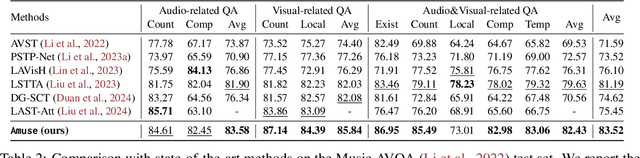
Music performances are representative scenarios for audio-visual modeling. Unlike common scenarios with sparse audio, music performances continuously involve dense audio signals throughout. While existing multimodal learning methods on the audio-video QA demonstrate impressive capabilities in general scenarios, they are incapable of dealing with fundamental problems within the music performances: they underexplore the interaction between the multimodal signals in performance and fail to consider the distinctive characteristics of instruments and music. Therefore, existing methods tend to answer questions regarding musical performances inaccurately. To bridge the above research gaps, (i) given the intricate multimodal interconnectivity inherent to music data, our primary backbone is designed to incorporate multimodal interactions within the context of music; (ii) to enable the model to learn music characteristics, we annotate and release rhythmic and music sources in the current music datasets; (iii) for time-aware audio-visual modeling, we align the model's music predictions with the temporal dimension. Our experiments show state-of-the-art effects on the Music AVQA datasets. Our code is available at https://github.com/xid32/Amuse.
Temporal Working Memory: Query-Guided Segment Refinement for Enhanced Multimodal Understanding
Feb 09, 2025



Multimodal foundation models (MFMs) have demonstrated significant success in tasks such as visual captioning, question answering, and image-text retrieval. However, these models face inherent limitations due to their finite internal capacity, which restricts their ability to process extended temporal sequences, a crucial requirement for comprehensive video and audio analysis. To overcome these challenges, we introduce a specialized cognitive module, temporal working memory (TWM), which aims to enhance the temporal modeling capabilities of MFMs. It selectively retains task-relevant information across temporal dimensions, ensuring that critical details are preserved throughout the processing of video and audio content. The TWM uses a query-guided attention approach to focus on the most informative multimodal segments within temporal sequences. By retaining only the most relevant content, TWM optimizes the use of the model's limited capacity, enhancing its temporal modeling ability. This plug-and-play module can be easily integrated into existing MFMs. With our TWM, nine state-of-the-art models exhibit significant performance improvements across tasks such as video captioning, question answering, and video-text retrieval. By enhancing temporal modeling, TWM extends the capability of MFMs to handle complex, time-sensitive data effectively. Our code is available at https://github.com/xid32/NAACL_2025_TWM.
Diving into Unified Data-Model Sparsity for Class-Imbalanced Graph Representation Learning
Oct 01, 2022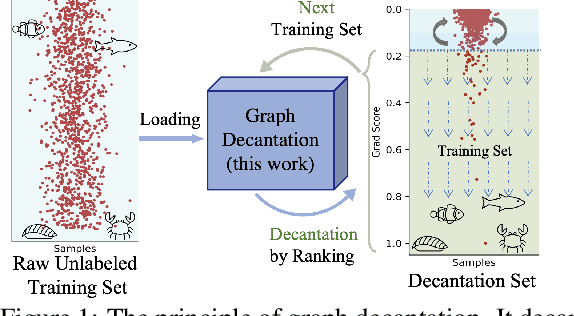
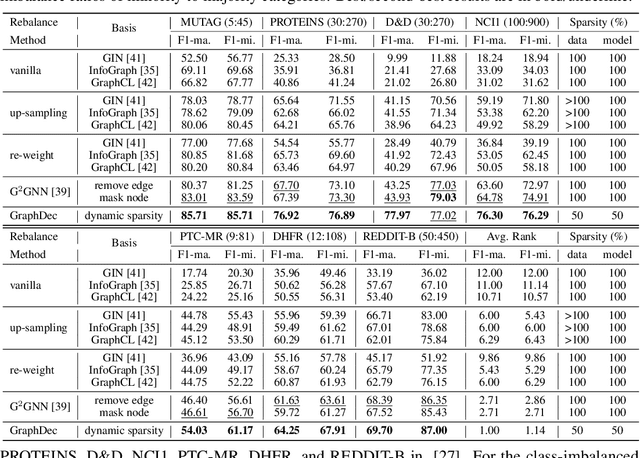
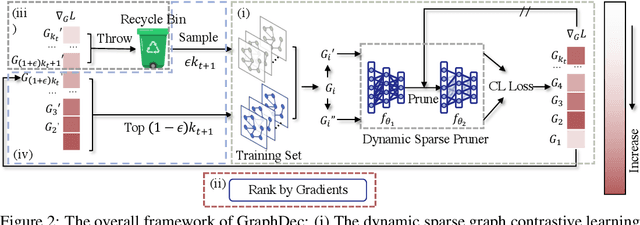
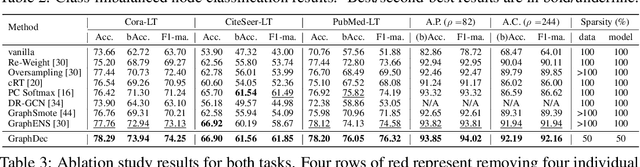
Even pruned by the state-of-the-art network compression methods, Graph Neural Networks (GNNs) training upon non-Euclidean graph data often encounters relatively higher time costs, due to its irregular and nasty density properties, compared with data in the regular Euclidean space. Another natural property concomitantly with graph is class-imbalance which cannot be alleviated by the massive graph data while hindering GNNs' generalization. To fully tackle these unpleasant properties, (i) theoretically, we introduce a hypothesis about what extent a subset of the training data can approximate the full dataset's learning effectiveness. The effectiveness is further guaranteed and proved by the gradients' distance between the subset and the full set; (ii) empirically, we discover that during the learning process of a GNN, some samples in the training dataset are informative for providing gradients to update model parameters. Moreover, the informative subset is not fixed during training process. Samples that are informative in the current training epoch may not be so in the next one. We also notice that sparse subnets pruned from a well-trained GNN sometimes forget the information provided by the informative subset, reflected in their poor performances upon the subset. Based on these findings, we develop a unified data-model dynamic sparsity framework named Graph Decantation (GraphDec) to address challenges brought by training upon a massive class-imbalanced graph data. The key idea of GraphDec is to identify the informative subset dynamically during the training process by adopting sparse graph contrastive learning. Extensive experiments on benchmark datasets demonstrate that GraphDec outperforms baselines for graph and node tasks, with respect to classification accuracy and data usage efficiency.
Adversarial Cross-View Disentangled Graph Contrastive Learning
Sep 16, 2022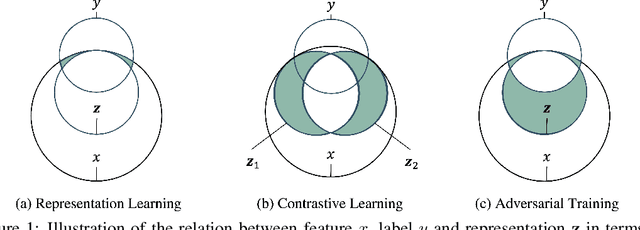
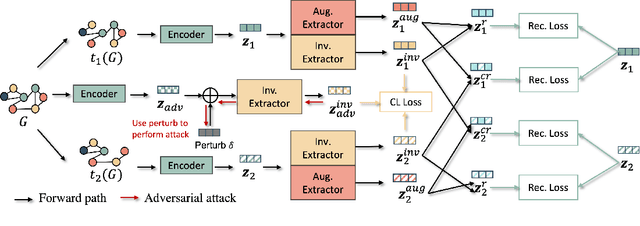

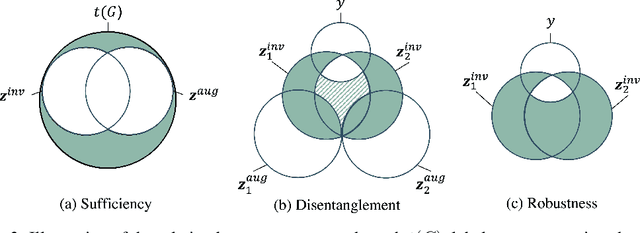
Graph contrastive learning (GCL) is prevalent to tackle the supervision shortage issue in graph learning tasks. Many recent GCL methods have been proposed with various manually designed augmentation techniques, aiming to implement challenging augmentations on the original graph to yield robust representation. Although many of them achieve remarkable performances, existing GCL methods still struggle to improve model robustness without risking losing task-relevant information because they ignore the fact the augmentation-induced latent factors could be highly entangled with the original graph, thus it is more difficult to discriminate the task-relevant information from irrelevant information. Consequently, the learned representation is either brittle or unilluminating. In light of this, we introduce the Adversarial Cross-View Disentangled Graph Contrastive Learning (ACDGCL), which follows the information bottleneck principle to learn minimal yet sufficient representations from graph data. To be specific, our proposed model elicits the augmentation-invariant and augmentation-dependent factors separately. Except for the conventional contrastive loss which guarantees the consistency and sufficiency of the representations across different contrastive views, we introduce a cross-view reconstruction mechanism to pursue the representation disentanglement. Besides, an adversarial view is added as the third view of contrastive loss to enhance model robustness. We empirically demonstrate that our proposed model outperforms the state-of-the-arts on graph classification task over multiple benchmark datasets.