 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph is a Substrate Across Data Modalities
Jan 29, 2026Graphs provide a natural representation of relational structure that arises across diverse domains. Despite this ubiquity, graph structure is typically learned in a modality- and task-isolated manner, where graph representations are constructed within individual task contexts and discarded thereafter. As a result, structural regularities across modalities and tasks are repeatedly reconstructed rather than accumulated at the level of intermediate graph representations. This motivates a representation-learning question: how should graph structure be organized so that it can persist and accumulate across heterogeneous modalities and tasks? We adopt a representation-centric perspective in which graph structure is treated as a structural substrate that persists across learning contexts. To instantiate this perspective, we propose G-Substrate, a graph substrate framework that organizes learning around shared graph structures. G-Substrate comprises two complementary mechanisms: a unified structural schema that ensures compatibility among graph representations across heterogeneous modalities and tasks, and an interleaved role-based training strategy that exposes the same graph structure to multiple functional roles during learning. Experiments across multiple domains, modalities, and tasks show that G-Substrate outperforms task-isolated and naive multi-task learning methods.
LACONIC: Dense-Level Effectiveness for Scalable Sparse Retrieval via a Two-Phase Training Curriculum
Jan 04, 2026While dense retrieval models have become the standard for state-of-the-art information retrieval, their deployment is often constrained by high memory requirements and reliance on GPU accelerators for vector similarity search. Learned sparse retrieval offers a compelling alternative by enabling efficient search via inverted indices, yet it has historically received less attention than dense approaches. In this report, we introduce LACONIC, a family of learned sparse retrievers based on the Llama-3 architecture (1B, 3B, and 8B). We propose a streamlined two-phase training curriculum consisting of (1) weakly supervised pre-finetuning to adapt causal LLMs for bidirectional contextualization and (2) high-signal finetuning using curated hard negatives. Our results demonstrate that LACONIC effectively bridges the performance gap with dense models: the 8B variant achieves a state-of-the-art 60.2 nDCG on the MTEB Retrieval benchmark, ranking 15th on the leaderboard as of January 1, 2026, while utilizing 71\% less index memory than an equivalent dense model. By delivering high retrieval effectiveness on commodity CPU hardware with a fraction of the compute budget required by competing models, LACONIC provides a scalable and efficient solution for real-world search applications.
Reinforcement Learning for Self-Improving Agent with Skill Library
Dec 18, 2025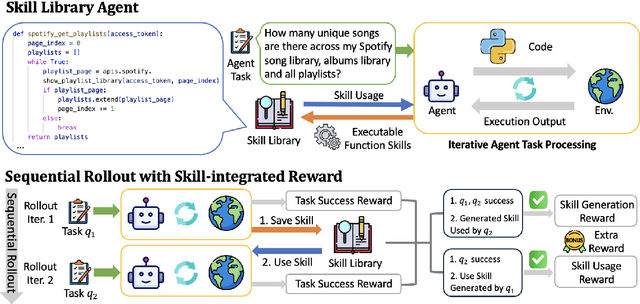
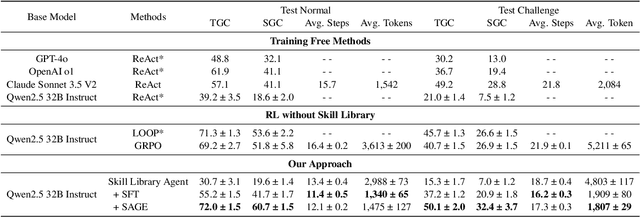
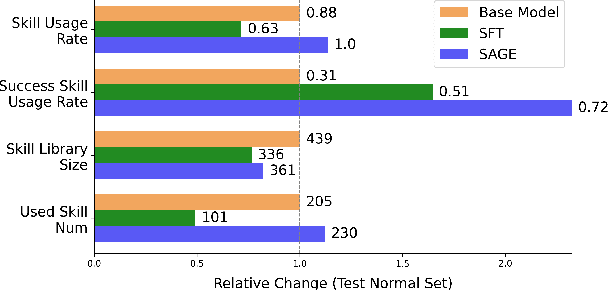
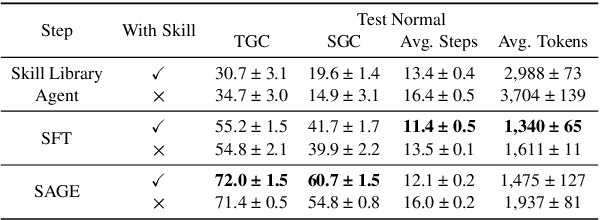
Large Language Model (LLM)-based agents have demonstrated remarkable capabilities in complex reasoning and multi-turn interactions but struggle to continuously improve and adapt when deployed in new environments. One promising approach is implementing skill libraries that allow agents to learn, validate, and apply new skills. However, current skill library approaches rely primarily on LLM prompting, making consistent skill library implementation challenging. To overcome these challenges, we propose a Reinforcement Learning (RL)-based approach to enhance agents' self-improvement capabilities with a skill library. Specifically, we introduce Skill Augmented GRPO for self-Evolution (SAGE), a novel RL framework that systematically incorporates skills into learning. The framework's key component, Sequential Rollout, iteratively deploys agents across a chain of similar tasks for each rollout. As agents navigate through the task chain, skills generated from previous tasks accumulate in the library and become available for subsequent tasks. Additionally, the framework enhances skill generation and utilization through a Skill-integrated Reward that complements the original outcome-based rewards. Experimental results on AppWorld demonstrate that SAGE, when applied to supervised-finetuned model with expert experience, achieves 8.9% higher Scenario Goal Completion while requiring 26% fewer interaction steps and generating 59% fewer tokens, substantially outperforming existing approaches in both accuracy and efficiency.
MV-Debate: Multi-view Agent Debate with Dynamic Reflection Gating for Multimodal Harmful Content Detection in Social Media
Aug 07, 2025Social media has evolved into a complex multimodal environment where text, images, and other signals interact to shape nuanced meanings, often concealing harmful intent. Identifying such intent, whether sarcasm, hate speech, or misinformation, remains challenging due to cross-modal contradictions, rapid cultural shifts, and subtle pragmatic cues. To address these challenges, we propose MV-Debate, a multi-view agent debate framework with dynamic reflection gating for unified multimodal harmful content detection. MV-Debate assembles four complementary debate agents, a surface analyst, a deep reasoner, a modality contrast, and a social contextualist, to analyze content from diverse interpretive perspectives. Through iterative debate and reflection, the agents refine responses under a reflection-gain criterion, ensuring both accuracy and efficiency. Experiments on three benchmark datasets demonstrate that MV-Debate significantly outperforms strong single-model and existing multi-agent debate baselines. This work highlights the promise of multi-agent debate in advancing reliable social intent detection in safety-critical online contexts.
CSPLADE: Learned Sparse Retrieval with Causal Language Models
Apr 15, 2025In recent years, dense retrieval has been the focus of information retrieval (IR) research. While effective, dense retrieval produces uninterpretable dense vectors, and suffers from the drawback of large index size. Learned sparse retrieval (LSR) has emerged as promising alternative, achieving competitive retrieval performance while also being able to leverage the classical inverted index data structure for efficient retrieval. However, limited works have explored scaling LSR beyond BERT scale. In this work, we identify two challenges in training large language models (LLM) for LSR: (1) training instability during the early stage of contrastive training; (2) suboptimal performance due to pre-trained LLM's unidirectional attention. To address these challenges, we propose two corresponding techniques: (1) a lightweight adaptation training phase to eliminate training instability; (2) two model variants to enable bidirectional information. With these techniques, we are able to train LSR models with 8B scale LLM, and achieve competitive retrieval performance with reduced index size. Furthermore, we are among the first to analyze the performance-efficiency tradeoff of LLM-based LSR model through the lens of model quantization. Our findings provide insights into adapting LLMs for efficient retrieval modeling.
Enhancing Multi-hop Reasoning in Vision-Language Models via Self-Distillation with Multi-Prompt Ensembling
Mar 03, 2025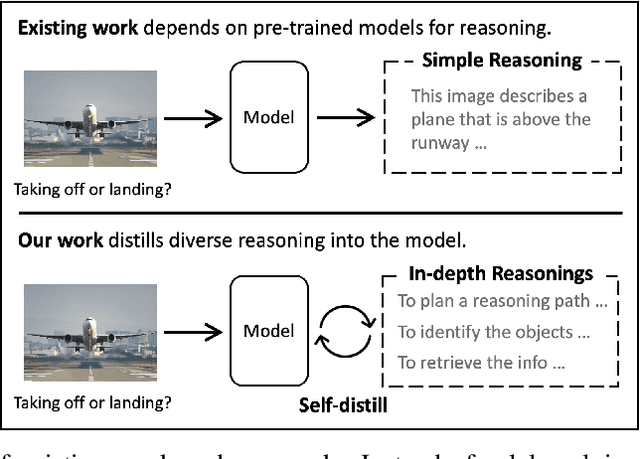

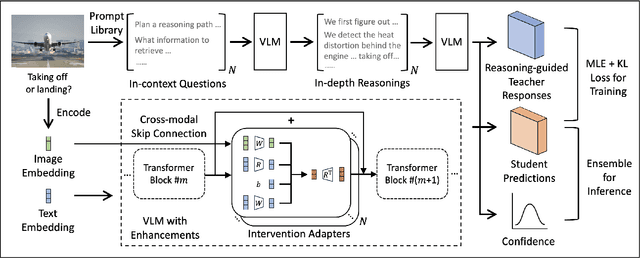

Multi-modal large language models have seen rapid advancement alongside large language models. However, while language models can effectively leverage chain-of-thought prompting for zero or few-shot learning, similar prompting strategies are less effective for multi-modal LLMs due to modality gaps and task complexity. To address this challenge, we explore two prompting approaches: a dual-query method that separates multi-modal input analysis and answer generation into two prompting steps, and an ensemble prompting method that combines multiple prompt variations to arrive at the final answer. Although these approaches enhance the model's reasoning capabilities without fine-tuning, they introduce significant inference overhead. Therefore, building on top of these two prompting techniques, we propose a self-distillation framework such that the model can improve itself without any annotated data. Our self-distillation framework learns representation intervention modules from the reasoning traces collected from ensembled dual-query prompts, in the form of hidden representations. The lightweight intervention modules operate in parallel with the frozen original model, which makes it possible to maintain computational efficiency while significantly improving model capability. We evaluate our method on five widely-used VQA benchmarks, demonstrating its effectiveness in performing multi-hop reasoning for complex tasks.
ChefFusion: Multimodal Foundation Model Integrating Recipe and Food Image Generation
Sep 18, 2024


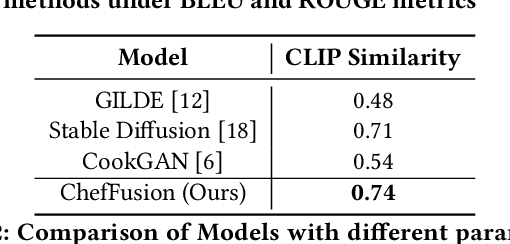
Significant work has been conducted in the domain of food computing, yet these studies typically focus on single tasks such as t2t (instruction generation from food titles and ingredients), i2t (recipe generation from food images), or t2i (food image generation from recipes). None of these approaches integrate all modalities simultaneously. To address this gap, we introduce a novel food computing foundation model that achieves true multimodality, encompassing tasks such as t2t, t2i, i2t, it2t, and t2ti. By leveraging large language models (LLMs) and pre-trained image encoder and decoder models, our model can perform a diverse array of food computing-related tasks, including food understanding, food recognition, recipe generation, and food image generation. Compared to previous models, our foundation model demonstrates a significantly broader range of capabilities and exhibits superior performance, particularly in food image generation and recipe generation tasks. We open-sourced ChefFusion at GitHub.
Machine Unlearning in Generative AI: A Survey
Jul 30, 2024



Generative AI technologies have been deployed in many places, such as (multimodal) large language models and vision generative models. Their remarkable performance should be attributed to massive training data and emergent reasoning abilities. However, the models would memorize and generate sensitive, biased, or dangerous information originated from the training data especially those from web crawl. New machine unlearning (MU) techniques are being developed to reduce or eliminate undesirable knowledge and its effects from the models, because those that were designed for traditional classification tasks could not be applied for Generative AI. We offer a comprehensive survey on many things about MU in Generative AI, such as a new problem formulation, evaluation methods, and a structured discussion on the advantages and limitations of different kinds of MU techniques. It also presents several critical challenges and promising directions in MU research. A curated list of readings can be found: https://github.com/franciscoliu/GenAI-MU-Reading.
Deconstructing The Ethics of Large Language Models from Long-standing Issues to New-emerging Dilemmas
Jun 08, 2024


Large Language Models (LLMs) have achieved unparalleled success across diverse language modeling tasks in recent years. However, this progress has also intensified ethical concerns, impacting the deployment of LLMs in everyday contexts. This paper provides a comprehensive survey of ethical challenges associated with LLMs, from longstanding issues such as copyright infringement, systematic bias, and data privacy, to emerging problems like truthfulness and social norms. We critically analyze existing research aimed at understanding, examining, and mitigating these ethical risks. Our survey underscores integrating ethical standards and societal values into the development of LLMs, thereby guiding the development of responsible and ethically aligned language models.
Post-Fair Federated Learning: Achieving Group and Community Fairness in Federated Learning via Post-processing
May 28, 2024



Federated Learning (FL) is a distributed machine learning framework in which a set of local communities collaboratively learn a shared global model while retaining all training data locally within each community. Two notions of fairness have recently emerged as important issues for federated learning: group fairness and community fairness. Group fairness requires that a model's decisions do not favor any particular group based on a set of legally protected attributes such as race or gender. Community fairness requires that global models exhibit similar levels of performance (accuracy) across all collaborating communities. Both fairness concepts can coexist within an FL framework, but the existing literature has focused on either one concept or the other. This paper proposes and analyzes a post-processing fair federated learning (FFL) framework called post-FFL. Post-FFL uses a linear program to simultaneously enforce group and community fairness while maximizing the utility of the global model. Because Post-FFL is a post-processing approach, it can be used with existing FL training pipelines whose convergence properties are well understood. This paper uses post-FFL on real-world datasets to mimic how hospital networks, for example, use federated learning to deliver community health care. Theoretical results bound the accuracy lost when post-FFL enforces both notion of fairness. Experimental results illustrate that post-FFL simultaneously improves both group and community fairness in FL. Moreover, post-FFL outperforms the existing in-processing fair federated learning in terms of improving both notions of fairness, communication efficiency and computation cost.