 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Context Augmentation from Contrastive Learning of Experience via Agentic Reflection
Apr 08, 2026Large language model agents rely on effective model context to obtain task-relevant information for decision-making. Many existing context engineering approaches primarily rely on the context generated from the past experience and retrieval mechanisms that reuse these context. However, retrieved context from past tasks must be adapted by the execution agent to fit new situations, placing additional reasoning burden on the underlying LLM. To address this limitation, we propose a generative context augmentation framework using Contrastive Learning of Experience via Agentic Reflection (CLEAR). CLEAR first employs a reflection agent to perform contrastive analysis over past execution trajectories and summarize useful context for each observed task. These summaries are then used as supervised fine-tuning data to train a context augmentation model (CAM). Then we further optimize CAM using reinforcement learning, where the reward signal is obtained by running the task execution agent. By learning to generate task-specific knowledge rather than retrieve knowledge from the past, CAM produces context that is better tailored to the current task. We conduct comprehensive evaluations on the AppWorld and WebShop benchmarks. Experimental results show that CLEAR consistently outperforms strong baselines. It improves task completion rate from 72.62% to 81.15% on AppWorld test set and averaged reward from 0.68 to 0.74 on a subset of WebShop, compared with baseline agent. Our code is publicly available at https://github.com/awslabs/CLEAR.
Reinforcement Learning for Self-Improving Agent with Skill Library
Dec 18, 2025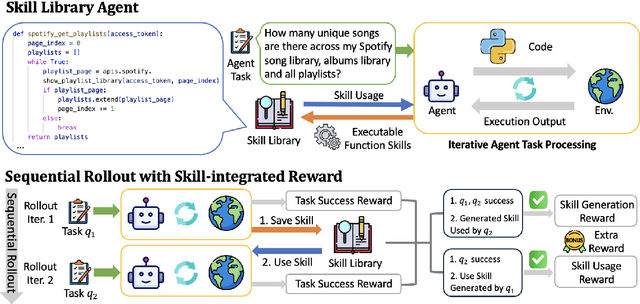
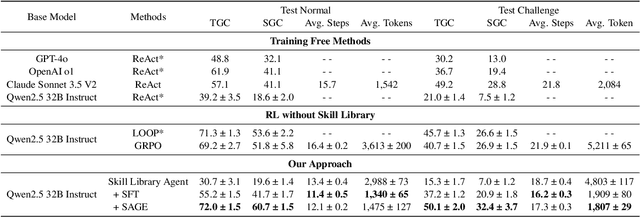
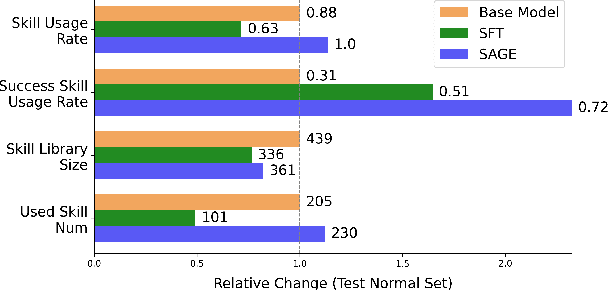
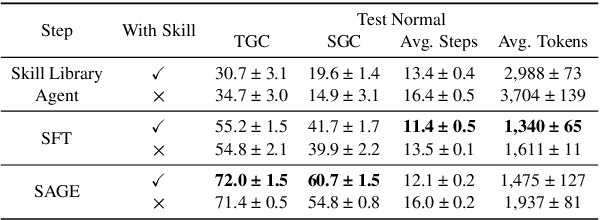
Large Language Model (LLM)-based agents have demonstrated remarkable capabilities in complex reasoning and multi-turn interactions but struggle to continuously improve and adapt when deployed in new environments. One promising approach is implementing skill libraries that allow agents to learn, validate, and apply new skills. However, current skill library approaches rely primarily on LLM prompting, making consistent skill library implementation challenging. To overcome these challenges, we propose a Reinforcement Learning (RL)-based approach to enhance agents' self-improvement capabilities with a skill library. Specifically, we introduce Skill Augmented GRPO for self-Evolution (SAGE), a novel RL framework that systematically incorporates skills into learning. The framework's key component, Sequential Rollout, iteratively deploys agents across a chain of similar tasks for each rollout. As agents navigate through the task chain, skills generated from previous tasks accumulate in the library and become available for subsequent tasks. Additionally, the framework enhances skill generation and utilization through a Skill-integrated Reward that complements the original outcome-based rewards. Experimental results on AppWorld demonstrate that SAGE, when applied to supervised-finetuned model with expert experience, achieves 8.9% higher Scenario Goal Completion while requiring 26% fewer interaction steps and generating 59% fewer tokens, substantially outperforming existing approaches in both accuracy and efficiency.
Enhancing Multi-hop Reasoning in Vision-Language Models via Self-Distillation with Multi-Prompt Ensembling
Mar 03, 2025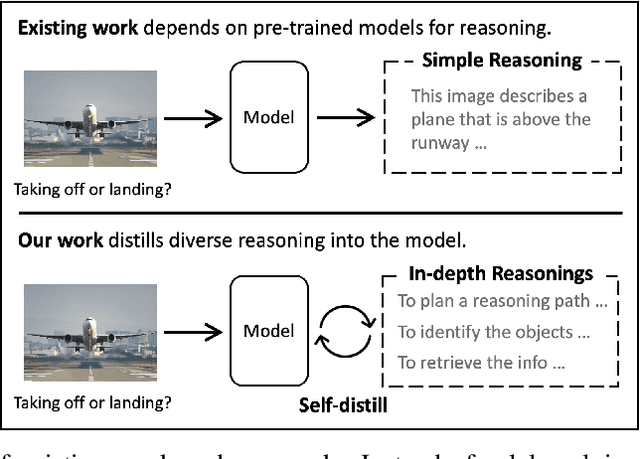

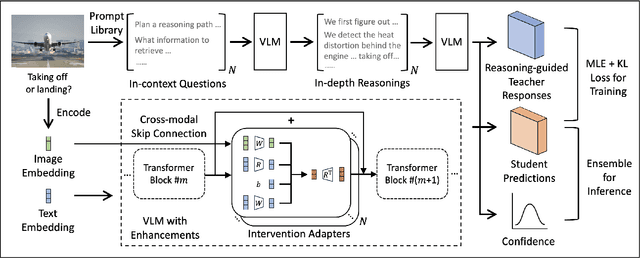

Multi-modal large language models have seen rapid advancement alongside large language models. However, while language models can effectively leverage chain-of-thought prompting for zero or few-shot learning, similar prompting strategies are less effective for multi-modal LLMs due to modality gaps and task complexity. To address this challenge, we explore two prompting approaches: a dual-query method that separates multi-modal input analysis and answer generation into two prompting steps, and an ensemble prompting method that combines multiple prompt variations to arrive at the final answer. Although these approaches enhance the model's reasoning capabilities without fine-tuning, they introduce significant inference overhead. Therefore, building on top of these two prompting techniques, we propose a self-distillation framework such that the model can improve itself without any annotated data. Our self-distillation framework learns representation intervention modules from the reasoning traces collected from ensembled dual-query prompts, in the form of hidden representations. The lightweight intervention modules operate in parallel with the frozen original model, which makes it possible to maintain computational efficiency while significantly improving model capability. We evaluate our method on five widely-used VQA benchmarks, demonstrating its effectiveness in performing multi-hop reasoning for complex tasks.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
Diversity-aware Web APIs Recommendation with Compatibility Guarantee
Aug 10, 2021



With the ever-increasing prevalence of web APIs (Application Programming Interfaces) in enabling smart software developments, finding and composing a list of existing web APIs that can corporately fulfil the software developers' functional needs have become a promising way to develop a successful mobile app, economically and conveniently. However, the big volume and diversity of candidate web APIs put additional burden on the app developers' web APIs selection decision-makings, since it is often a challenging task to simultaneously guarantee the diversity and compatibility of the finally selected a set of web APIs. Considering this challenge, a Diversity-aware and Compatibility-driven web APIs Recommendation approach, namely DivCAR, is put forward in this paper. First, to achieve diversity, DivCAR employs random walk sampling technique on a pre-built correlation graph to generate diverse correlation subgraphs. Afterwards, with the diverse correlation subgraphs, we model the compatible web APIs recommendation problem to be a minimum group Steiner tree search problem. Through solving the minimum group Steiner tree search problem, manifold sets of compatible and diverse web APIs ranked are returned to the app developers. At last, we design and enact a set of experiments on a real-world dataset crawled from www.programmableWeb.com. Experimental results validate the effectiveness and efficiency of our proposed DivCAR approach in balancing the web APIs recommendation diversity and compatibility.
Reward function shape exploration in adversarial imitation learning: an empirical study
Apr 14, 2021
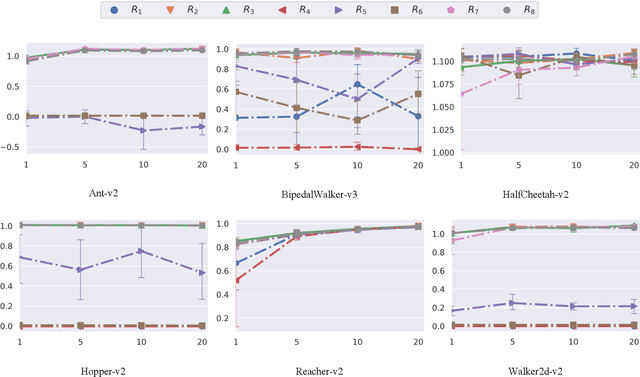
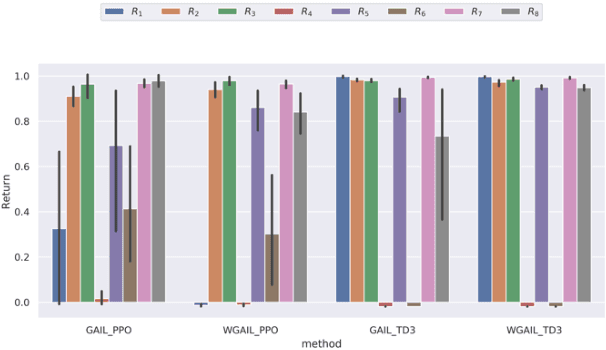
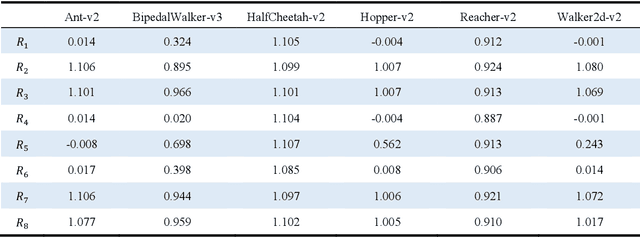
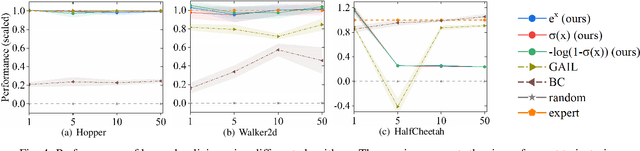
For adversarial imitation learning algorithms (AILs), no true rewards are obtained from the environment for learning the strategy. However, the pseudo rewards based on the output of the discriminator are still required. Given the implicit reward bias problem in AILs, we design several representative reward function shapes and compare their performances by large-scale experiments. To ensure our results' reliability, we conduct the experiments on a series of Mujoco and Box2D continuous control tasks based on four different AILs. Besides, we also compare the performance of various reward function shapes using varying numbers of expert trajectories. The empirical results reveal that the positive logarithmic reward function works well in typical continuous control tasks. In contrast, the so-called unbiased reward function is limited to specific kinds of tasks. Furthermore, several designed reward functions perform excellently in these environments as well.
Autonomous Charging of Electric Vehicle Fleets to Enhance Renewable Generation Dispatchability
Dec 22, 2020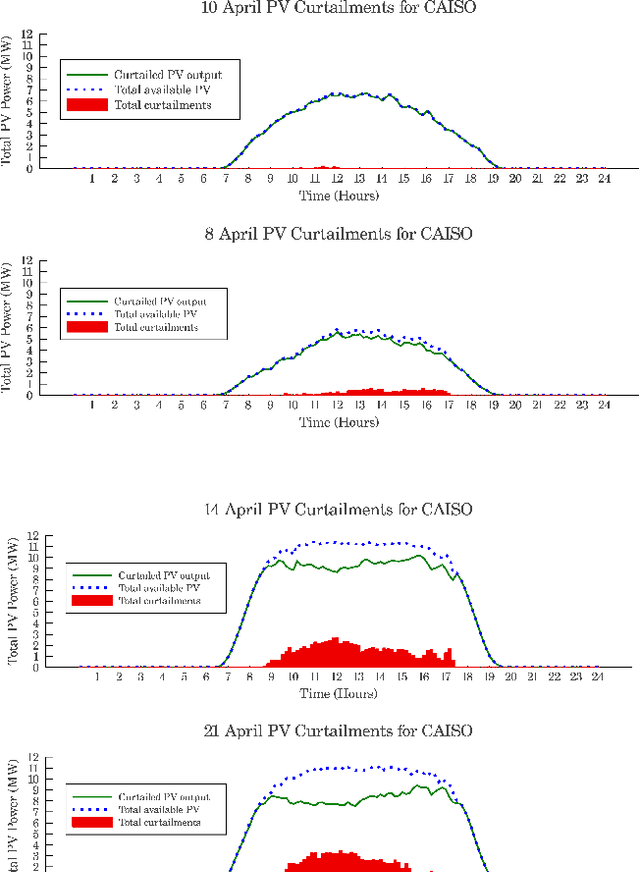

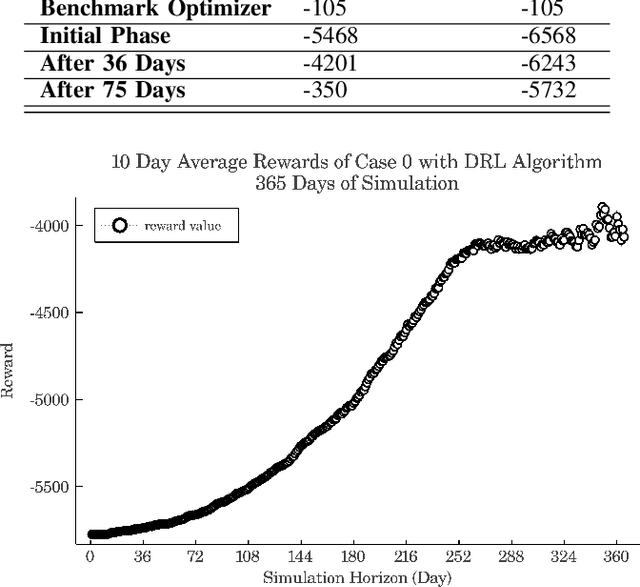
A total 19% of generation capacity in California is offered by PV units and over some months, more than 10% of this energy is curtailed. In this research, a novel approach to reduce renewable generation curtailments and increasing system flexibility by means of electric vehicles' charging coordination is represented. The presented problem is a sequential decision making process, and is solved by fitted Q-iteration algorithm which unlike other reinforcement learning methods, needs fewer episodes of learning. Three case studies are presented to validate the effectiveness of the proposed approach. These cases include aggregator load following, ramp service and utilization of non-deterministic PV generation. The results suggest that through this framework, EVs successfully learn how to adjust their charging schedule in stochastic scenarios where their trip times, as well as solar power generation are unknown beforehand.
Wasserstein Distance guided Adversarial Imitation Learning with Reward Shape Exploration
Jun 05, 2020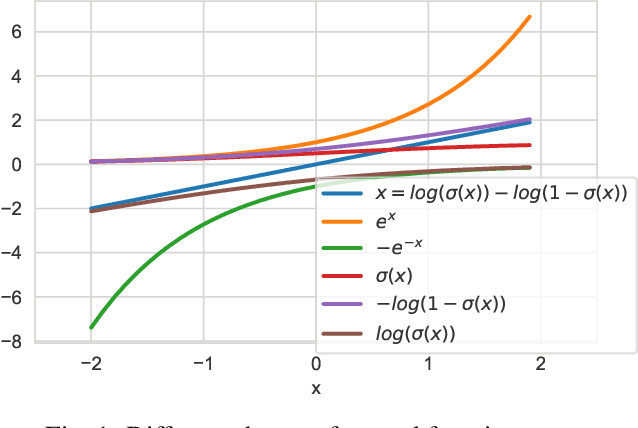
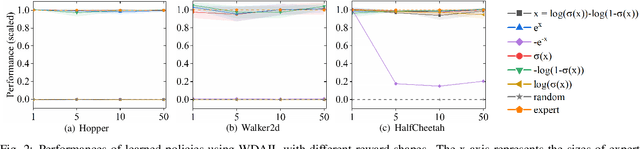

The generative adversarial imitation learning (GAIL) has provided an adversarial learning framework for imitating expert policy from demonstrations in high-dimensional continuous tasks. However, almost all GAIL and its extensions only design a kind of reward function of logarithmic form in the adversarial training strategy with the Jensen-Shannon (JS) divergence for all complex environments. The fixed logarithmic type of reward function may be difficult to solve all complex tasks, and the vanishing gradients problem caused by the JS divergence will harm the adversarial learning process. In this paper, we propose a new algorithm named Wasserstein Distance guided Adversarial Imitation Learning (WDAIL) for promoting the performance of imitation learning (IL). There are three improvements in our method: (a) introducing the Wasserstein distance to obtain more appropriate measure in adversarial training process, (b) using proximal policy optimization (PPO) in the reinforcement learning stage which is much simpler to implement and makes the algorithm more efficient, and (c) exploring different reward function shapes to suit different tasks for improving the performance. The experiment results show that the learning procedure remains remarkably stable, and achieves significant performance in the complex continuous control tasks of MuJoCo.