 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQL-Trail: Multi-Turn Reinforcement Learning with Interleaved Feedback for Text-to-SQL
Jan 25, 2026While large language models (LLMs) have substantially improved Text-to-SQL generation, a pronounced gap remains between AI systems and human experts on challenging benchmarks such as BIRD-SQL. We argue this gap stems largely from the prevailing single-pass paradigm, which lacks the iterative reasoning, schema exploration, and error-correction behaviors that humans naturally employ. To address this limitation, we introduce SQL-Trail, a multi-turn reinforcement learning (RL) agentic framework for Text-to-SQL. Rather than producing a query in one shot, SQL-Trail interacts with the database environment and uses execution feedback to iteratively refine its predictions. Our approach centers on two key ideas: (i) an adaptive turn-budget allocation mechanism that scales the agent's interaction depth to match question difficulty, and (ii) a composite reward panel that jointly incentivizes SQL correctness and efficient exploration. Across benchmarks, SQL-Trail sets a new state of the art and delivers strong data efficiency--up to 18x higher than prior single-pass RL state-of-the-art methods. Notably, our 7B and 14B models outperform substantially larger proprietary systems by 5% on average, underscoring the effectiveness of interactive, agentic workflows for robust Text-to-SQL generation.
SLOT: Structuring the Output of Large Language Models
May 06, 2025



Structured outputs are essential for large language models (LLMs) in critical applications like agents and information extraction. Despite their capabilities, LLMs often generate outputs that deviate from predefined schemas, significantly hampering reliable application development. We present SLOT (Structured LLM Output Transformer), a model-agnostic approach that transforms unstructured LLM outputs into precise structured formats. While existing solutions predominantly rely on constrained decoding techniques or are tightly coupled with specific models, SLOT employs a fine-tuned lightweight language model as a post-processing layer, achieving flexibility across various LLMs and schema specifications. We introduce a systematic pipeline for data curation and synthesis alongside a formal evaluation methodology that quantifies both schema accuracy and content fidelity. Our results demonstrate that fine-tuned Mistral-7B model with constrained decoding achieves near perfect schema accuracy (99.5%) and content similarity (94.0%), outperforming Claude-3.5-Sonnet by substantial margins (+25 and +20 percentage points, respectively). Notably, even compact models like Llama-3.2-1B can match or exceed the structured output capabilities of much larger proprietary models when equipped with SLOT, enabling reliable structured generation in resource-constrained environments.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
Pushing the Limits of All-Atom Geometric Graph Neural Networks: Pre-Training, Scaling and Zero-Shot Transfer
Oct 29, 2024Constructing transferable descriptors for conformation representation of molecular and biological systems finds numerous applications in drug discovery, learning-based molecular dynamics, and protein mechanism analysis. Geometric graph neural networks (Geom-GNNs) with all-atom information have transformed atomistic simulations by serving as a general learnable geometric descriptors for downstream tasks including prediction of interatomic potential and molecular properties. However, common practices involve supervising Geom-GNNs on specific downstream tasks, which suffer from the lack of high-quality data and inaccurate labels leading to poor generalization and performance degradation on out-of-distribution (OOD) scenarios. In this work, we explored the possibility of using pre-trained Geom-GNNs as transferable and highly effective geometric descriptors for improved generalization. To explore their representation power, we studied the scaling behaviors of Geom-GNNs under self-supervised pre-training, supervised and unsupervised learning setups. We find that the expressive power of different architectures can differ on the pre-training task. Interestingly, Geom-GNNs do not follow the power-law scaling on the pre-training task, and universally lack predictable scaling behavior on the supervised tasks with quantum chemical labels important for screening and design of novel molecules. More importantly, we demonstrate how all-atom graph embedding can be organically combined with other neural architectures to enhance the expressive power. Meanwhile, the low-dimensional projection of the latent space shows excellent agreement with conventional geometrical descriptors.
OpenTab: Advancing Large Language Models as Open-domain Table Reasoners
Feb 22, 2024



Large Language Models (LLMs) trained on large volumes of data excel at various natural language tasks, but they cannot handle tasks requiring knowledge that has not been trained on previously. One solution is to use a retriever that fetches relevant information to expand LLM's knowledge scope. However, existing textual-oriented retrieval-based LLMs are not ideal on structured table data due to diversified data modalities and large table sizes. In this work, we propose OpenTab, an open-domain table reasoning framework powered by LLMs. Overall, OpenTab leverages table retriever to fetch relevant tables and then generates SQL programs to parse the retrieved tables efficiently. Utilizing the intermediate data derived from the SQL executions, it conducts grounded inference to produce accurate response. Extensive experimental evaluation shows that OpenTab significantly outperforms baselines in both open- and closed-domain settings, achieving up to 21.5% higher accuracy. We further run ablation studies to validate the efficacy of our proposed designs of the system.
Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection
Oct 30, 2023Large Language Models (LLMs) can adapt to new tasks via in-context learning (ICL). ICL is efficient as it does not require any parameter updates to the trained LLM, but only few annotated examples as input for the LLM. In this work, we investigate an active learning approach for ICL, where there is a limited budget for annotating examples. We propose a model-adaptive optimization-free algorithm, termed AdaICL, which identifies examples that the model is uncertain about, and performs semantic diversity-based example selection. Diversity-based sampling improves overall effectiveness, while uncertainty sampling improves budget efficiency and helps the LLM learn new information. Moreover, AdaICL poses its sampling strategy as a Maximum Coverage problem, that dynamically adapts based on the model's feedback and can be approximately solved via greedy algorithms. Extensive experiments on nine datasets and seven LLMs show that AdaICL improves performance by 4.4% accuracy points over SOTA (7.7% relative improvement), is up to 3x more budget-efficient than performing annotations uniformly at random, while it outperforms SOTA with 2x fewer ICL examples.
NameGuess: Column Name Expansion for Tabular Data
Oct 19, 2023Recent advances in large language models have revolutionized many sectors, including the database industry. One common challenge when dealing with large volumes of tabular data is the pervasive use of abbreviated column names, which can negatively impact performance on various data search, access, and understanding tasks. To address this issue, we introduce a new task, called NameGuess, to expand column names (used in database schema) as a natural language generation problem. We create a training dataset of 384K abbreviated-expanded column pairs using a new data fabrication method and a human-annotated evaluation benchmark that includes 9.2K examples from real-world tables. To tackle the complexities associated with polysemy and ambiguity in NameGuess, we enhance auto-regressive language models by conditioning on table content and column header names -- yielding a fine-tuned model (with 2.7B parameters) that matches human performance. Furthermore, we conduct a comprehensive analysis (on multiple LLMs) to validate the effectiveness of table content in NameGuess and identify promising future opportunities. Code has been made available at https://github.com/amazon-science/nameguess.
Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
Oct 14, 2023

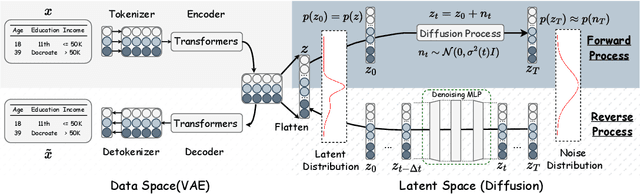

Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces TABSYN, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed TABSYN include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that TABSYN outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.