 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrasoundAgents: Hierarchical Multi-Agent Evidence-Chain Reasoning for Breast Ultrasound Diagnosis
Mar 11, 2026Breast ultrasound diagnosis typically proceeds from global lesion localization to local sign assessment and then evidence integration to assign a BI-RADS category and determine benignity or malignancy. Many existing methods rely on end-to-end prediction or provide only weakly grounded evidence, which can miss fine-grained lesion cues and limit auditability and clinical review. To align with the clinical workflow and improve evidence traceability, we propose a hierarchical multi-agent framework, termed UltrasoundAgents. A main agent localizes the lesion in the full image and triggers a crop-and-zoom operation. A sub-agent analyzes the local view and predicts four clinically relevant attributes, namely echogenicity pattern, calcification, boundary type, and edge (margin) morphology. The main agent then integrates these structured attributes to perform evidence-based reasoning and output the BI-RADS category and the malignancy prediction, while producing reviewable intermediate evidence. Furthermore, hierarchical multi-agent training often suffers from error propagation, difficult credit assignment, and sparse rewards. To alleviate this and improve training stability, we introduce a decoupled progressive training strategy. We first train the attribute agent, then train the main agent with oracle attributes to learn robust attribute-based reasoning, and finally apply corrective trajectory self-distillation with spatial supervision to build high-quality trajectories for supervised fine-tuning, yielding a deployable end-to-end policy. Experiments show consistent gains over strong vision-language baselines in diagnostic accuracy and attribute agreement, together with structured evidence and traceable reasoning.
Learning to Ideate for Machine Learning Engineering Agents
Jan 24, 2026Existing machine learning engineering (MLE) agents struggle to iteratively optimize their implemented algorithms for effectiveness. To address this, we introduce MLE-Ideator, a dual-agent framework that separates ideation from implementation. In our system, an implementation agent can request strategic help from a dedicated Ideator. We show this approach is effective in two ways. First, in a training-free setup, our framework significantly outperforms implementation-only agent baselines on MLE-Bench. Second, we demonstrate that the Ideator can be trained with reinforcement learning (RL) to generate more effective ideas. With only 1K training samples from 10 MLE tasks, our RL-trained Qwen3-8B Ideator achieves an 11.5% relative improvement compared to its untrained counterpart and surpasses Claude Sonnet 3.5. These results highlights a promising path toward training strategic AI systems for scientific discovery.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Diffusion Language Model Inference with Monte Carlo Tree Search
Dec 13, 2025Diffusion language models (DLMs) have recently emerged as a compelling alternative to autoregressive generation, offering parallel generation and improved global coherence. During inference, DLMs generate text by iteratively denoising masked sequences in parallel; however, determining which positions to unmask and which tokens to commit forms a large combinatorial search problem. Existing inference methods approximate this search using heuristics, which often yield suboptimal decoding paths; other approaches instead rely on additional training to guide token selection. To introduce a principled search mechanism for DLMs inference, we introduce MEDAL, a framework that integrates Monte Carlo Tree SEarch initialization for Diffusion LAnguage Model inference. We employ Monte Carlo Tree Search at the initialization stage to explore promising unmasking trajectories, providing a robust starting point for subsequent refinement. This integration is enabled by restricting the search space to high-confidence actions and prioritizing token choices that improve model confidence over remaining masked positions. Across multiple benchmarks, MEDAL achieves up to 22.0% improvement over existing inference strategies, establishing a new paradigm for search-based inference in diffusion language models.
A Gradient Meta-Learning Joint Optimization for Beamforming and Antenna Position in Pinching-Antenna Systems
Jun 14, 2025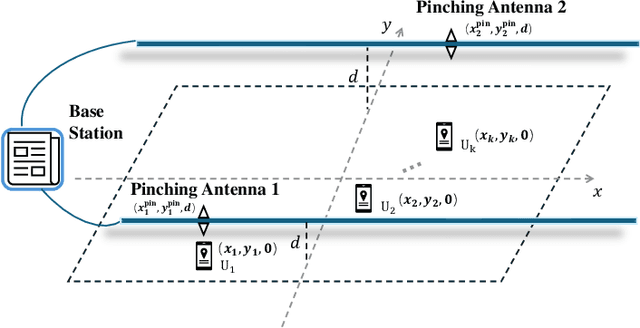
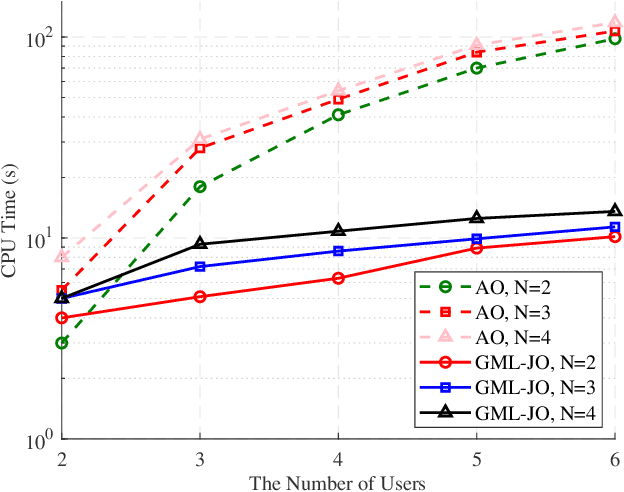
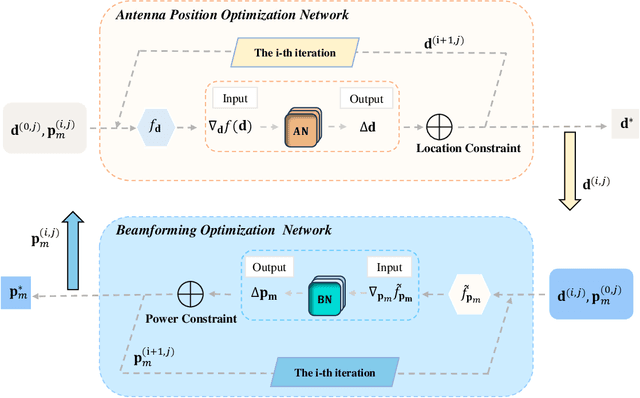
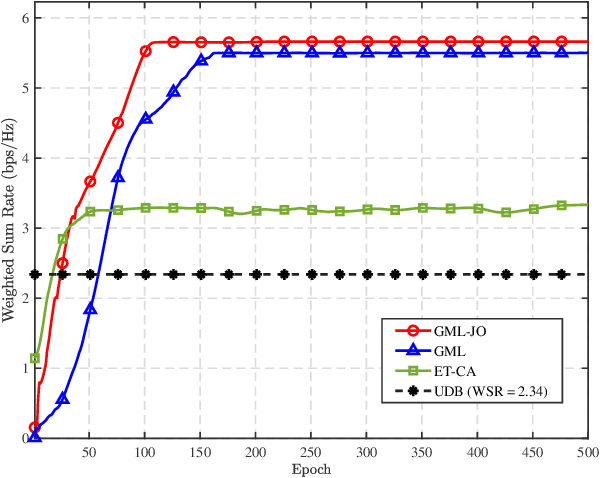
In this paper, we consider a novel optimization design for multi-waveguide pinching-antenna systems, aiming to maximize the weighted sum rate (WSR) by jointly optimizing beamforming coefficients and antenna position. To handle the formulated non-convex problem, a gradient-based meta-learning joint optimization (GML-JO) algorithm is proposed. Specifically, the original problem is initially decomposed into two sub-problems of beamforming optimization and antenna position optimization through equivalent substitution. Then, the convex approximation methods are used to deal with the nonconvex constraints of sub-problems, and two sub-neural networks are constructed to calculate the sub-problems separately. Different from alternating optimization (AO), where two sub-problems are solved alternately and the solutions are influenced by the initial values, two sub-neural networks of proposed GML-JO with fixed channel coefficients are considered as local sub-tasks and the computation results are used to calculate the loss function of joint optimization. Finally, the parameters of sub-networks are updated using the average loss function over different sub-tasks and the solution that is robust to the initial value is obtained. Simulation results demonstrate that the proposed GML-JO algorithm achieves 5.6 bits/s/Hz WSR within 100 iterations, yielding a 32.7\% performance enhancement over conventional AO with substantially reduced computational complexity. Moreover, the proposed GML-JO algorithm is robust to different choices of initialization and yields better performance compared with the existing optimization methods.
Towards a More Generalized Approach in Open Relation Extraction
May 28, 2025Open Relation Extraction (OpenRE) seeks to identify and extract novel relational facts between named entities from unlabeled data without pre-defined relation schemas. Traditional OpenRE methods typically assume that the unlabeled data consists solely of novel relations or is pre-divided into known and novel instances. However, in real-world scenarios, novel relations are arbitrarily distributed. In this paper, we propose a generalized OpenRE setting that considers unlabeled data as a mixture of both known and novel instances. To address this, we propose MixORE, a two-phase framework that integrates relation classification and clustering to jointly learn known and novel relations. Experiments on three benchmark datasets demonstrate that MixORE consistently outperforms competitive baselines in known relation classification and novel relation clustering. Our findings contribute to the advancement of generalized OpenRE research and real-world applications.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
Black-Box Visual Prompt Engineering for Mitigating Object Hallucination in Large Vision Language Models
Apr 30, 2025Large Vision Language Models (LVLMs) often suffer from object hallucination, which undermines their reliability. Surprisingly, we find that simple object-based visual prompting -- overlaying visual cues (e.g., bounding box, circle) on images -- can significantly mitigate such hallucination; however, different visual prompts (VPs) vary in effectiveness. To address this, we propose Black-Box Visual Prompt Engineering (BBVPE), a framework to identify optimal VPs that enhance LVLM responses without needing access to model internals. Our approach employs a pool of candidate VPs and trains a router model to dynamically select the most effective VP for a given input image. This black-box approach is model-agnostic, making it applicable to both open-source and proprietary LVLMs. Evaluations on benchmarks such as POPE and CHAIR demonstrate that BBVPE effectively reduces object hallucination.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.