 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisAnalog: A Diagnostic Suite for Visual Concept Transfer on Natural Images
May 22, 2026A useful test of visual concept learning is not just whether a model can recognize a concept in a single image, but whether it can preserve and manipulate concept-level properties under transformation and transfer them to new scenes. We introduce VisAnalog, a controlled suite for this setting on natural images. Each example instantiates $A\!:\!B::C\!:\,?$: images $B$ and a hidden target image $D$ are produced by applying the same deterministic transformation sequence to source images $A$ and $C$. Given $A$, $B$, and $C$, a model must answer a multiple-choice question about $D$. The benchmark contains 617 human-validated questions spanning one- to four-step transformations such as zoom, quadrant swap, rotation, flip, and hue rotation. Across strong proprietary and open-source VLMs, end-to-end accuracy is substantially lower than oracle accuracy when $D$ is directly shown, and degrades sharply as transformation depth increases, while human performance remains near the ceiling. A program-conditioned evaluation further separates failures of relation inference from failures of transformation application, showing that inferring the visual relation from $A \rightarrow B$ is the dominant bottleneck, with additional application errors emerging on harder multi-step cases. The dataset is publicly available at https://huggingface.co/datasets/zli99/VisAnalog.
Investigating Context-Faithfulness in Large Language Models: The Roles of Memory Strength and Evidence Style
Sep 17, 2024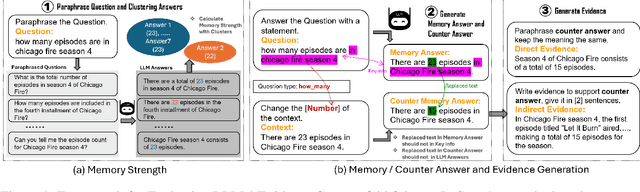

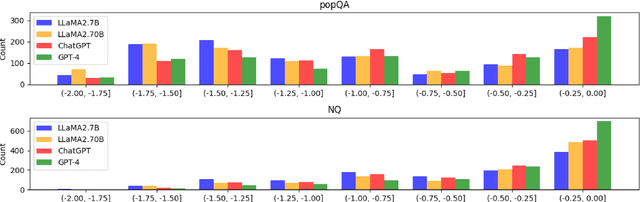
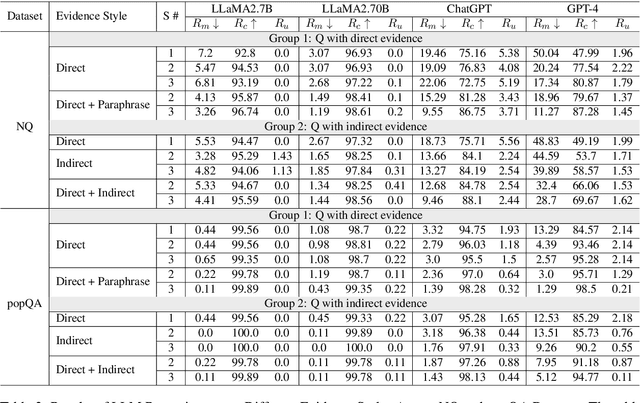
Retrieval-augmented generation (RAG) improves Large Language Models (LLMs) by incorporating external information into the response generation process. However, how context-faithful LLMs are and what factors influence LLMs' context-faithfulness remain largely unexplored. In this study, we investigate the impact of memory strength and evidence presentation on LLMs' receptiveness to external evidence. We introduce a method to quantify the memory strength of LLMs by measuring the divergence in LLMs' responses to different paraphrases of the same question, which is not considered by previous works. We also generate evidence in various styles to evaluate the effects of evidence in different styles. Two datasets are used for evaluation: Natural Questions (NQ) with popular questions and popQA featuring long-tail questions. Our results show that for questions with high memory strength, LLMs are more likely to rely on internal memory, particularly for larger LLMs such as GPT-4. On the other hand, presenting paraphrased evidence significantly increases LLMs' receptiveness compared to simple repetition or adding details.
A Consistent Lebesgue Measure for Multi-label Learning
Feb 01, 2024Multi-label loss functions are usually non-differentiable, requiring surrogate loss functions for gradient-based optimisation. The consistency of surrogate loss functions is not proven and is exacerbated by the conflicting nature of multi-label loss functions. To directly learn from multiple related, yet potentially conflicting multi-label loss functions, we propose a Consistent Lebesgue Measure-based Multi-label Learner (CLML) and prove that CLML can achieve theoretical consistency under a Bayes risk framework. Empirical evidence supports our theory by demonstrating that: (1) CLML can consistently achieve state-of-the-art results; (2) the primary performance factor is the Lebesgue measure design, as CLML optimises a simpler feedforward model without additional label graph, perturbation-based conditioning, or semantic embeddings; and (3) an analysis of the results not only distinguishes CLML's effectiveness but also highlights inconsistencies between the surrogate and the desired loss functions.