 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Context-Faithfulness in Large Language Models: The Roles of Memory Strength and Evidence Style
Paper and Code
Sep 17, 2024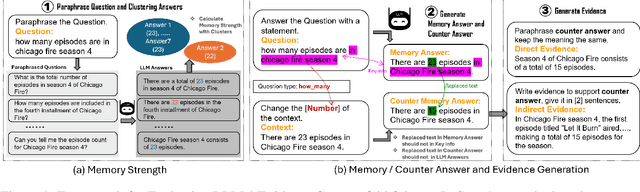

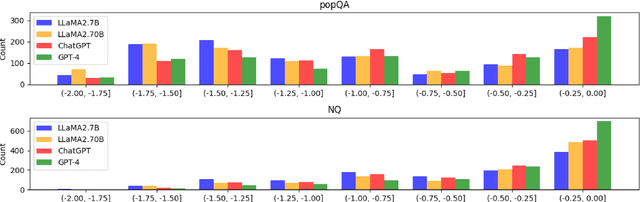
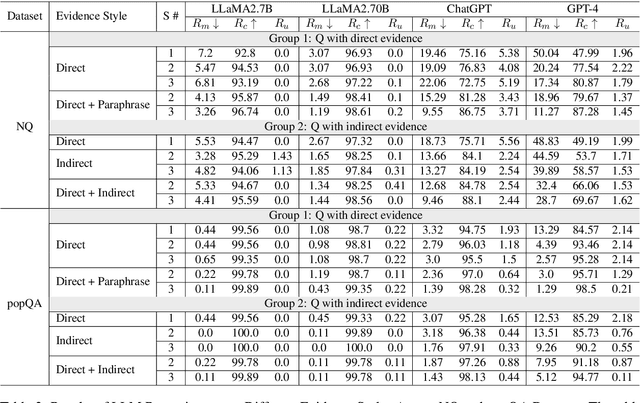
Retrieval-augmented generation (RAG) improves Large Language Models (LLMs) by incorporating external information into the response generation process. However, how context-faithful LLMs are and what factors influence LLMs' context-faithfulness remain largely unexplored. In this study, we investigate the impact of memory strength and evidence presentation on LLMs' receptiveness to external evidence. We introduce a method to quantify the memory strength of LLMs by measuring the divergence in LLMs' responses to different paraphrases of the same question, which is not considered by previous works. We also generate evidence in various styles to evaluate the effects of evidence in different styles. Two datasets are used for evaluation: Natural Questions (NQ) with popular questions and popQA featuring long-tail questions. Our results show that for questions with high memory strength, LLMs are more likely to rely on internal memory, particularly for larger LLMs such as GPT-4. On the other hand, presenting paraphrased evidence significantly increases LLMs' receptiveness compared to simple repetition or adding details.