 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesFlow: A Probability Inference Framework for Meta-Agent Assisted Workflow Generation
Jan 29, 2026Automatic workflow generation is the process of automatically synthesizing sequences of LLM calls, tool invocations, and post-processing steps for complex end-to-end tasks. Most prior methods cast this task as an optimization problem with limited theoretical grounding. We propose to cast workflow generation as Bayesian inference over a posterior distribution on workflows, and introduce \textbf{Bayesian Workflow Generation (BWG)}, a sampling framework that builds workflows step-by-step using parallel look-ahead rollouts for importance weighting and a sequential in-loop refiner for pool-wide improvements. We prove that, without the refiner, the weighted empirical distribution converges to the target posterior. We instantiate BWG as \textbf{BayesFlow}, a training-free algorithm for workflow construction. Across six benchmark datasets, BayesFlow improves accuracy by up to 9 percentage points over SOTA workflow generation baselines and by up to 65 percentage points over zero-shot prompting, establishing BWG as a principled upgrade to search-based workflow design. Code will be available on https://github.com/BoYuanVisionary/BayesFlow.
Learning to Ideate for Machine Learning Engineering Agents
Jan 24, 2026Existing machine learning engineering (MLE) agents struggle to iteratively optimize their implemented algorithms for effectiveness. To address this, we introduce MLE-Ideator, a dual-agent framework that separates ideation from implementation. In our system, an implementation agent can request strategic help from a dedicated Ideator. We show this approach is effective in two ways. First, in a training-free setup, our framework significantly outperforms implementation-only agent baselines on MLE-Bench. Second, we demonstrate that the Ideator can be trained with reinforcement learning (RL) to generate more effective ideas. With only 1K training samples from 10 MLE tasks, our RL-trained Qwen3-8B Ideator achieves an 11.5% relative improvement compared to its untrained counterpart and surpasses Claude Sonnet 3.5. These results highlights a promising path toward training strategic AI systems for scientific discovery.
Erased, But Not Forgotten: Erased Rectified Flow Transformers Still Remain Unsafe Under Concept Attack
Oct 01, 2025Recent advances in text-to-image (T2I) diffusion models have enabled impressive generative capabilities, but they also raise significant safety concerns due to the potential to produce harmful or undesirable content. While concept erasure has been explored as a mitigation strategy, most existing approaches and corresponding attack evaluations are tailored to Stable Diffusion (SD) and exhibit limited effectiveness when transferred to next-generation rectified flow transformers such as Flux. In this work, we present ReFlux, the first concept attack method specifically designed to assess the robustness of concept erasure in the latest rectified flow-based T2I framework. Our approach is motivated by the observation that existing concept erasure techniques, when applied to Flux, fundamentally rely on a phenomenon known as attention localization. Building on this insight, we propose a simple yet effective attack strategy that specifically targets this property. At its core, a reverse-attention optimization strategy is introduced to effectively reactivate suppressed signals while stabilizing attention. This is further reinforced by a velocity-guided dynamic that enhances the robustness of concept reactivation by steering the flow matching process, and a consistency-preserving objective that maintains the global layout and preserves unrelated content. Extensive experiments consistently demonstrate the effectiveness and efficiency of the proposed attack method, establishing a reliable benchmark for evaluating the robustness of concept erasure strategies in rectified flow transformers.
ReferSplat: Referring Segmentation in 3D Gaussian Splatting
Aug 11, 2025We introduce Referring 3D Gaussian Splatting Segmentation (R3DGS), a new task that aims to segment target objects in a 3D Gaussian scene based on natural language descriptions, which often contain spatial relationships or object attributes. This task requires the model to identify newly described objects that may be occluded or not directly visible in a novel view, posing a significant challenge for 3D multi-modal understanding. Developing this capability is crucial for advancing embodied AI. To support research in this area, we construct the first R3DGS dataset, Ref-LERF. Our analysis reveals that 3D multi-modal understanding and spatial relationship modeling are key challenges for R3DGS. To address these challenges, we propose ReferSplat, a framework that explicitly models 3D Gaussian points with natural language expressions in a spatially aware paradigm. ReferSplat achieves state-of-the-art performance on both the newly proposed R3DGS task and 3D open-vocabulary segmentation benchmarks. Dataset and code are available at https://github.com/heshuting555/ReferSplat.
Black-Box Visual Prompt Engineering for Mitigating Object Hallucination in Large Vision Language Models
Apr 30, 2025Large Vision Language Models (LVLMs) often suffer from object hallucination, which undermines their reliability. Surprisingly, we find that simple object-based visual prompting -- overlaying visual cues (e.g., bounding box, circle) on images -- can significantly mitigate such hallucination; however, different visual prompts (VPs) vary in effectiveness. To address this, we propose Black-Box Visual Prompt Engineering (BBVPE), a framework to identify optimal VPs that enhance LVLM responses without needing access to model internals. Our approach employs a pool of candidate VPs and trains a router model to dynamically select the most effective VP for a given input image. This black-box approach is model-agnostic, making it applicable to both open-source and proprietary LVLMs. Evaluations on benchmarks such as POPE and CHAIR demonstrate that BBVPE effectively reduces object hallucination.
Collaborative LLM Numerical Reasoning with Local Data Protection
Apr 01, 2025Numerical reasoning over documents, which demands both contextual understanding and logical inference, is challenging for low-capacity local models deployed on computation-constrained devices. Although such complex reasoning queries could be routed to powerful remote models like GPT-4, exposing local data raises significant data leakage concerns. Existing mitigation methods generate problem descriptions or examples for remote assistance. However, the inherent complexity of numerical reasoning hinders the local model from generating logically equivalent queries and accurately inferring answers with remote guidance. In this paper, we present a model collaboration framework with two key innovations: (1) a context-aware synthesis strategy that shifts the query domains while preserving logical consistency; and (2) a tool-based answer reconstruction approach that reuses the remote-generated problem-solving pattern with code snippets. Experimental results demonstrate that our method achieves better reasoning accuracy than solely using local models while providing stronger data protection than fully relying on remote models. Furthermore, our method improves accuracy by 16.2% - 43.6% while reducing data leakage by 2.3% - 44.6% compared to existing data protection approaches.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
Machine Learning for Raman Spectroscopy-based Cyber-Marine Fish Biochemical Composition Analysis
Sep 29, 2024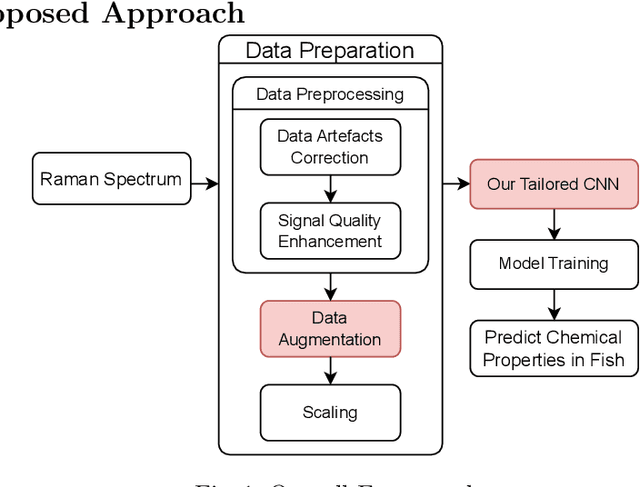

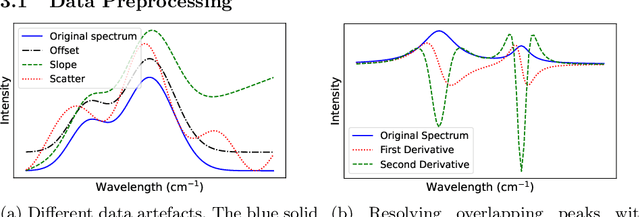
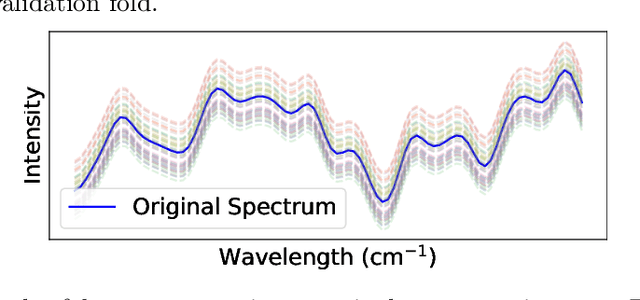
The rapid and accurate detection of biochemical compositions in fish is a crucial real-world task that facilitates optimal utilization and extraction of high-value products in the seafood industry. Raman spectroscopy provides a promising solution for quickly and non-destructively analyzing the biochemical composition of fish by associating Raman spectra with biochemical reference data using machine learning regression models. This paper investigates different regression models to address this task and proposes a new design of Convolutional Neural Networks (CNNs) for jointly predicting water, protein, and lipids yield. To the best of our knowledge, we are the first to conduct a successful study employing CNNs to analyze the biochemical composition of fish based on a very small Raman spectroscopic dataset. Our approach combines a tailored CNN architecture with the comprehensive data preparation procedure, effectively mitigating the challenges posed by extreme data scarcity. The results demonstrate that our CNN can significantly outperform two state-of-the-art CNN models and multiple traditional machine learning models, paving the way for accurate and automated analysis of fish biochemical composition.
DAGAM: A Domain Adversarial Graph Attention Model for Subject Independent EEG-Based Emotion Recognition
Feb 27, 2022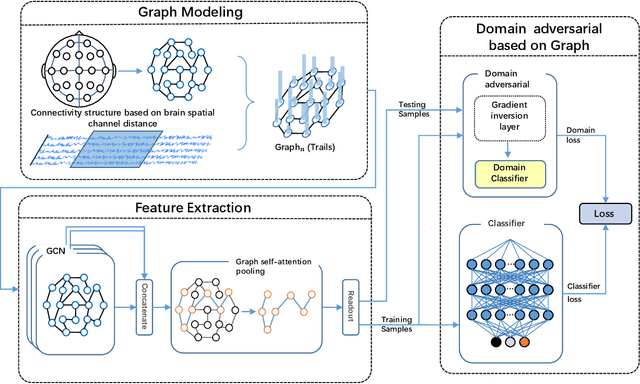
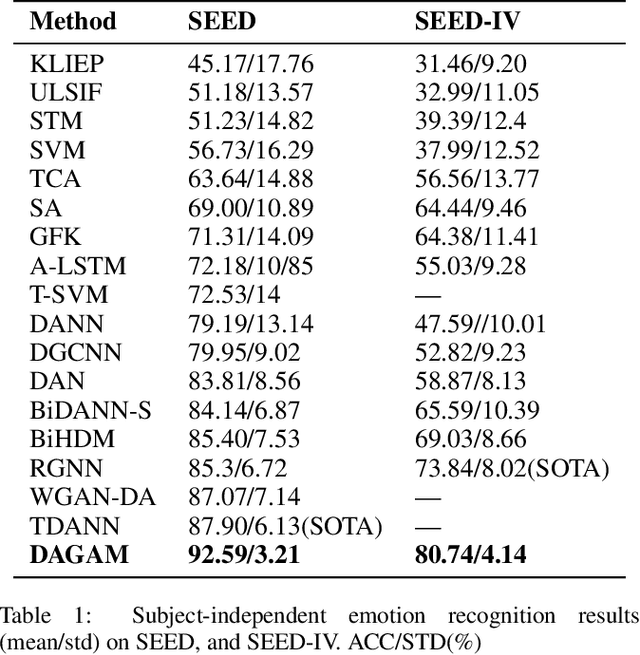
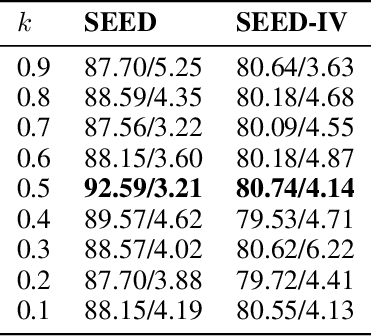
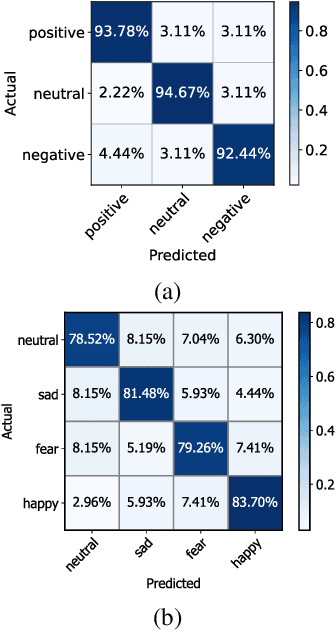
One of the most significant challenges of EEG-based emotion recognition is the cross-subject EEG variations, leading to poor performance and generalizability. This paper proposes a novel EEG-based emotion recognition model called the domain adversarial graph attention model (DAGAM). The basic idea is to generate a graph to model multichannel EEG signals using biological topology. Graph theory can topologically describe and analyze relationships and mutual dependency between channels of EEG. Then, unlike other graph convolutional networks, self-attention pooling is applied to benefit salient EEG feature extraction from the graph, which effectively improves the performance. Finally, after graph pooling, the domain adversarial based on the graph is employed to identify and handle EEG variation across subjects, efficiently reaching good generalizability. We conduct extensive evaluations on two benchmark datasets (SEED and SEED IV) and obtain state-of-the-art results in subject-independent emotion recognition. Our model boosts the SEED accuracy to 92.59% (4.69% improvement) with the lowest standard deviation of 3.21% (2.92% decrements) and SEED IV accuracy to 80.74% (6.90% improvement) with the lowest standard deviation of 4.14% (3.88% decrements) respectively.
Rethinking Feature Uncertainty in Stochastic Neural Networks for Adversarial Robustness
Jan 01, 2022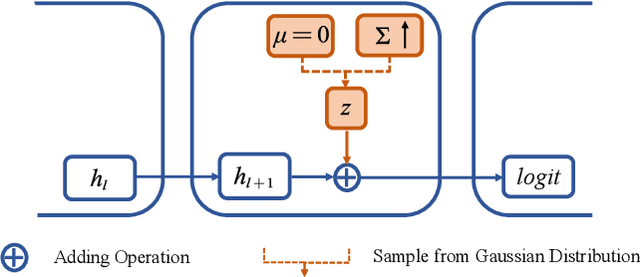
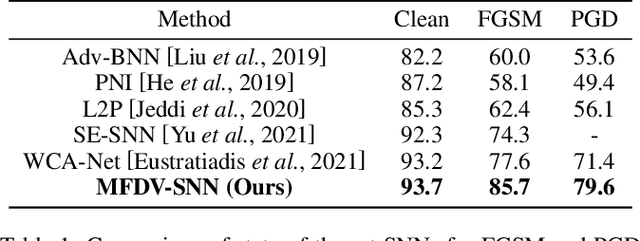
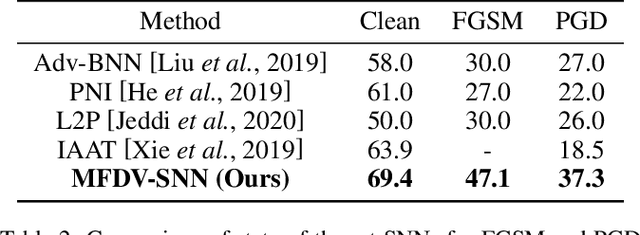
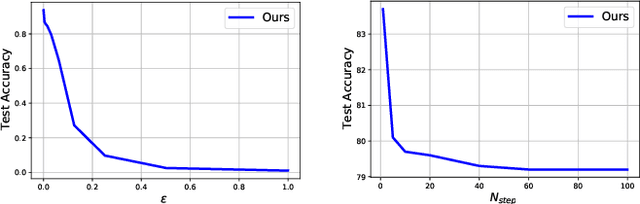
It is well-known that deep neural networks (DNNs) have shown remarkable success in many fields. However, when adding an imperceptible magnitude perturbation on the model input, the model performance might get rapid decrease. To address this issue, a randomness technique has been proposed recently, named Stochastic Neural Networks (SNNs). Specifically, SNNs inject randomness into the model to defend against unseen attacks and improve the adversarial robustness. However, existed studies on SNNs mainly focus on injecting fixed or learnable noises to model weights/activations. In this paper, we find that the existed SNNs performances are largely bottlenecked by the feature representation ability. Surprisingly, simply maximizing the variance per dimension of the feature distribution leads to a considerable boost beyond all previous methods, which we named maximize feature distribution variance stochastic neural network (MFDV-SNN). Extensive experiments on well-known white- and black-box attacks show that MFDV-SNN achieves a significant improvement over existing methods, which indicates that it is a simple but effective method to improve model robustness.