 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiPair: Fast and Accurate Distillation for Trillion-Scale Text Matching and Pair Modeling
Oct 07, 2020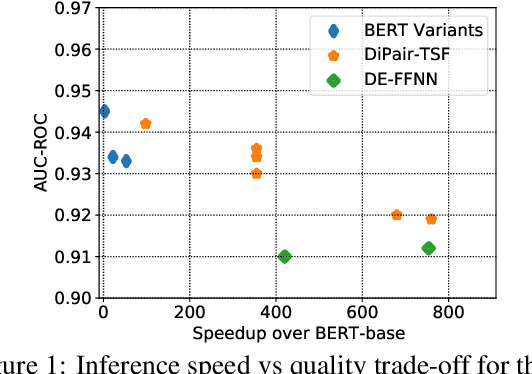

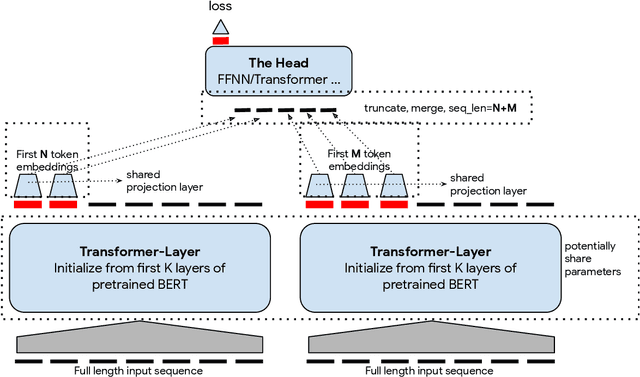
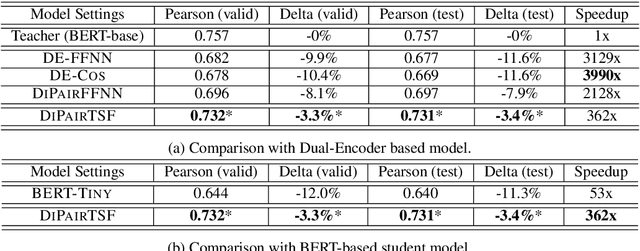
Pre-trained models like BERT (Devlin et al., 2018) have dominated NLP / IR applications such as single sentence classification, text pair classification, and question answering. However, deploying these models in real systems is highly non-trivial due to their exorbitant computational costs. A common remedy to this is knowledge distillation (Hinton et al., 2015), leading to faster inference. However -- as we show here -- existing works are not optimized for dealing with pairs (or tuples) of texts. Consequently, they are either not scalable or demonstrate subpar performance. In this work, we propose DiPair -- a novel framework for distilling fast and accurate models on text pair tasks. Coupled with an end-to-end training strategy, DiPair is both highly scalable and offers improved quality-speed tradeoffs. Empirical studies conducted on both academic and real-world e-commerce benchmarks demonstrate the efficacy of the proposed approach with speedups of over 350x and minimal quality drop relative to the cross-attention teacher BERT model.