 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching Personal Collections
Dec 16, 2024This article describes the history of information retrieval on personal document collections.
Creator Context for Tweet Recommendation
Nov 29, 2023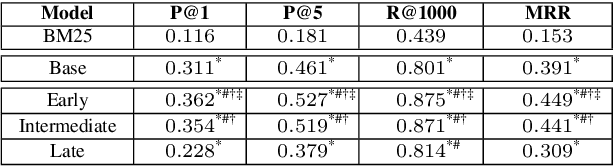

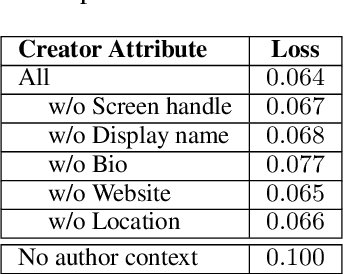
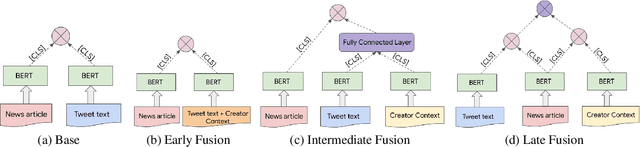
When discussing a tweet, people usually not only refer to the content it delivers, but also to the person behind the tweet. In other words, grounding the interpretation of the tweet in the context of its creator plays an important role in deciphering the true intent and the importance of the tweet. In this paper, we attempt to answer the question of how creator context should be used to advance tweet understanding. Specifically, we investigate the usefulness of different types of creator context, and examine different model structures for incorporating creator context in tweet modeling. We evaluate our tweet understanding models on a practical use case -- recommending relevant tweets to news articles. This use case already exists in popular news apps, and can also serve as a useful assistive tool for journalists. We discover that creator context is essential for tweet understanding, and can improve application metrics by a large margin. However, we also observe that not all creator contexts are equal. Creator context can be time sensitive and noisy. Careful creator context selection and deliberate model structure design play an important role in creator context effectiveness.
Exploring the Viability of Synthetic Query Generation for Relevance Prediction
May 19, 2023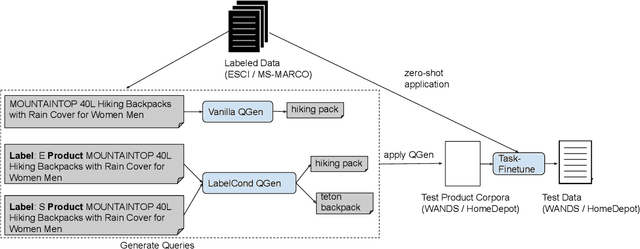

Query-document relevance prediction is a critical problem in Information Retrieval systems. This problem has increasingly been tackled using (pretrained) transformer-based models which are finetuned using large collections of labeled data. However, in specialized domains such as e-commerce and healthcare, the viability of this approach is limited by the dearth of large in-domain data. To address this paucity, recent methods leverage these powerful models to generate high-quality task and domain-specific synthetic data. Prior work has largely explored synthetic data generation or query generation (QGen) for Question-Answering (QA) and binary (yes/no) relevance prediction, where for instance, the QGen models are given a document, and trained to generate a query relevant to that document. However in many problems, we have a more fine-grained notion of relevance than a simple yes/no label. Thus, in this work, we conduct a detailed study into how QGen approaches can be leveraged for nuanced relevance prediction. We demonstrate that -- contrary to claims from prior works -- current QGen approaches fall short of the more conventional cross-domain transfer-learning approaches. Via empirical studies spanning 3 public e-commerce benchmarks, we identify new shortcomings of existing QGen approaches -- including their inability to distinguish between different grades of relevance. To address this, we introduce label-conditioned QGen models which incorporates knowledge about the different relevance. While our experiments demonstrate that these modifications help improve performance of QGen techniques, we also find that QGen approaches struggle to capture the full nuance of the relevance label space and as a result the generated queries are not faithful to the desired relevance label.
Do Not Blindly Imitate the Teacher: Using Perturbed Loss for Knowledge Distillation
May 08, 2023



Knowledge distillation is a popular technique to transfer knowledge from large teacher models to a small student model. Typically, the student learns to imitate the teacher by minimizing the KL divergence of its output distribution with the teacher's output distribution. In this work, we argue that such a learning objective is sub-optimal because there exists a discrepancy between the teacher's output distribution and the ground truth label distribution. Therefore, forcing the student to blindly imitate the unreliable teacher output distribution leads to inferior performance. To this end, we propose a novel knowledge distillation objective PTLoss by first representing the vanilla KL-based distillation loss function via a Maclaurin series and then perturbing the leading-order terms in this series. This perturbed loss implicitly transforms the original teacher into a proxy teacher with a distribution closer to the ground truth distribution. We establish the theoretical connection between this "distribution closeness" and the student model generalizability, which enables us to select the PTLoss's perturbation coefficients in a principled way. Extensive experiments on five datasets demonstrate PTLoss can significantly improve the distillation effectiveness for teachers of various scales.
"Why is this misleading?": Detecting News Headline Hallucinations with Explanations
Feb 12, 2023



Automatic headline generation enables users to comprehend ongoing news events promptly and has recently become an important task in web mining and natural language processing. With the growing need for news headline generation, we argue that the hallucination issue, namely the generated headlines being not supported by the original news stories, is a critical challenge for the deployment of this feature in web-scale systems Meanwhile, due to the infrequency of hallucination cases and the requirement of careful reading for raters to reach the correct consensus, it is difficult to acquire a large dataset for training a model to detect such hallucinations through human curation. In this work, we present a new framework named ExHalder to address this challenge for headline hallucination detection. ExHalder adapts the knowledge from public natural language inference datasets into the news domain and learns to generate natural language sentences to explain the hallucination detection results. To evaluate the model performance, we carefully collect a dataset with more than six thousand labeled <article, headline> pairs. Extensive experiments on this dataset and another six public ones demonstrate that ExHalder can identify hallucinated headlines accurately and justifies its predictions with human-readable natural language explanations.
Towards Disentangling Relevance and Bias in Unbiased Learning to Rank
Dec 28, 2022Unbiased learning to rank (ULTR) studies the problem of mitigating various biases from implicit user feedback data such as clicks, and has been receiving considerable attention recently. A popular ULTR approach for real-world applications uses a two-tower architecture, where click modeling is factorized into a relevance tower with regular input features, and a bias tower with bias-relevant inputs such as the position of a document. A successful factorization will allow the relevance tower to be exempt from biases. In this work, we identify a critical issue that existing ULTR methods ignored - the bias tower can be confounded with the relevance tower via the underlying true relevance. In particular, the positions were determined by the logging policy, i.e., the previous production model, which would possess relevance information. We give both theoretical analysis and empirical results to show the negative effects on relevance tower due to such a correlation. We then propose three methods to mitigate the negative confounding effects by better disentangling relevance and bias. Empirical results on both controlled public datasets and a large-scale industry dataset show the effectiveness of the proposed approaches.
DSI++: Updating Transformer Memory with New Documents
Dec 19, 2022



Differentiable Search Indices (DSIs) encode a corpus of documents in the parameters of a model and use the same model to map queries directly to relevant document identifiers. Despite the strong performance of DSI models, deploying them in situations where the corpus changes over time is computationally expensive because reindexing the corpus requires re-training the model. In this work, we introduce DSI++, a continual learning challenge for DSI to incrementally index new documents while being able to answer queries related to both previously and newly indexed documents. Across different model scales and document identifier representations, we show that continual indexing of new documents leads to considerable forgetting of previously indexed documents. We also hypothesize and verify that the model experiences forgetting events during training, leading to unstable learning. To mitigate these issues, we investigate two approaches. The first focuses on modifying the training dynamics. Flatter minima implicitly alleviate forgetting, so we optimize for flatter loss basins and show that the model stably memorizes more documents (+12\%). Next, we introduce a generative memory to sample pseudo-queries for documents and supplement them during continual indexing to prevent forgetting for the retrieval task. Extensive experiments on novel continual indexing benchmarks based on Natural Questions (NQ) and MS MARCO demonstrate that our proposed solution mitigates forgetting by a significant margin. Concretely, it improves the average Hits@10 by $+21.1\%$ over competitive baselines for NQ and requires $6$ times fewer model updates compared to re-training the DSI model for incrementally indexing five corpora in a sequence.
Regression Compatible Listwise Objectives for Calibrated Ranking
Nov 02, 2022


As Learning-to-Rank (LTR) approaches primarily seek to improve ranking quality, their output scores are not scale-calibrated by design -- for example, adding a constant to the score of each item on the list will not affect the list ordering. This fundamentally limits LTR usage in score-sensitive applications. Though a simple multi-objective approach that combines a regression and a ranking objective can effectively learn scale-calibrated scores, we argue that the two objectives can be inherently conflicting, which makes the trade-off far from ideal for both of them. In this paper, we propose a novel regression compatible ranking (RCR) approach to achieve a better trade-off. The advantage of the proposed approach is that the regression and ranking components are well aligned which brings new opportunities for harmonious regression and ranking. Theoretically, we show that the two components share the same minimizer at global minima while the regression component ensures scale calibration. Empirically, we show that the proposed approach performs well on both regression and ranking metrics on several public LTR datasets, and significantly improves the Pareto frontiers in the context of multi-objective optimization. Furthermore, we evaluated the proposed approach on YouTube Search and found that it not only improved the ranking quality of the production pCTR model, but also brought gains to the click prediction accuracy.
Out-of-Domain Semantics to the Rescue! Zero-Shot Hybrid Retrieval Models
Jan 25, 2022



The pre-trained language model (eg, BERT) based deep retrieval models achieved superior performance over lexical retrieval models (eg, BM25) in many passage retrieval tasks. However, limited work has been done to generalize a deep retrieval model to other tasks and domains. In this work, we carefully select five datasets, including two in-domain datasets and three out-of-domain datasets with different levels of domain shift, and study the generalization of a deep model in a zero-shot setting. Our findings show that the performance of a deep retrieval model is significantly deteriorated when the target domain is very different from the source domain that the model was trained on. On the contrary, lexical models are more robust across domains. We thus propose a simple yet effective framework to integrate lexical and deep retrieval models. Our experiments demonstrate that these two models are complementary, even when the deep model is weaker in the out-of-domain setting. The hybrid model obtains an average of 20.4% relative gain over the deep retrieval model, and an average of 9.54% over the lexical model in three out-of-domain datasets.
Data-Efficient Information Extraction from Form-Like Documents
Jan 07, 2022
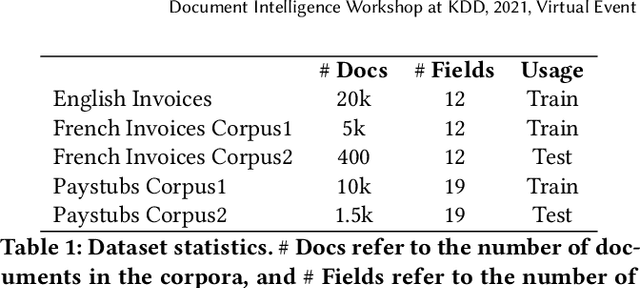
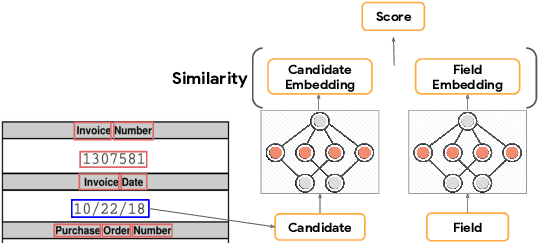
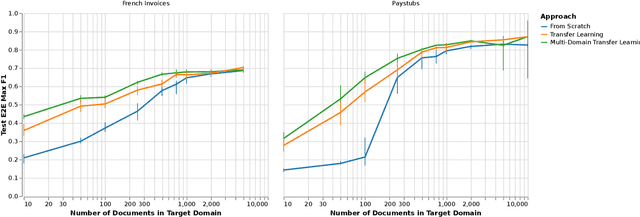
Automating information extraction from form-like documents at scale is a pressing need due to its potential impact on automating business workflows across many industries like financial services, insurance, and healthcare. The key challenge is that form-like documents in these business workflows can be laid out in virtually infinitely many ways; hence, a good solution to this problem should generalize to documents with unseen layouts and languages. A solution to this problem requires a holistic understanding of both the textual segments and the visual cues within a document, which is non-trivial. While the natural language processing and computer vision communities are starting to tackle this problem, there has not been much focus on (1) data-efficiency, and (2) ability to generalize across different document types and languages. In this paper, we show that when we have only a small number of labeled documents for training (~50), a straightforward transfer learning approach from a considerably structurally-different larger labeled corpus yields up to a 27 F1 point improvement over simply training on the small corpus in the target domain. We improve on this with a simple multi-domain transfer learning approach, that is currently in production use, and show that this yields up to a further 8 F1 point improvement. We make the case that data efficiency is critical to enable information extraction systems to scale to handle hundreds of different document-types, and learning good representations is critical to accomplishing this.