 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Range Tasks Using Short-Context LLMs: Incremental Reasoning With Structured Memories
Dec 25, 2024



Long-range tasks require reasoning over long inputs. Existing solutions either need large compute budgets, training data, access to model weights, or use complex, task-specific approaches. We present PRISM, which alleviates these concerns by processing information as a stream of chunks, maintaining a structured in-context memory specified by a typed hierarchy schema. This approach demonstrates superior performance to baselines on diverse tasks while using at least 4x smaller contexts than long-context models. Moreover, PRISM is token-efficient. By producing short outputs and efficiently leveraging key-value (KV) caches, it achieves up to 54% cost reduction when compared to alternative short-context approaches. The method also scales down to tiny information chunks (e.g., 500 tokens) without increasing the number of tokens encoded or sacrificing quality. Furthermore, we show that it is possible to generate schemas to generalize our approach to new tasks with minimal effort.
Enhancing Incremental Summarization with Structured Representations
Jul 21, 2024



Large language models (LLMs) often struggle with processing extensive input contexts, which can lead to redundant, inaccurate, or incoherent summaries. Recent methods have used unstructured memory to incrementally process these contexts, but they still suffer from information overload due to the volume of unstructured data handled. In our study, we introduce structured knowledge representations ($GU_{json}$), which significantly improve summarization performance by 40% and 14% across two public datasets. Most notably, we propose the Chain-of-Key strategy ($CoK_{json}$) that dynamically updates or augments these representations with new information, rather than recreating the structured memory for each new source. This method further enhances performance by 7% and 4% on the datasets.
SUMIE: A Synthetic Benchmark for Incremental Entity Summarization
Jun 07, 2024
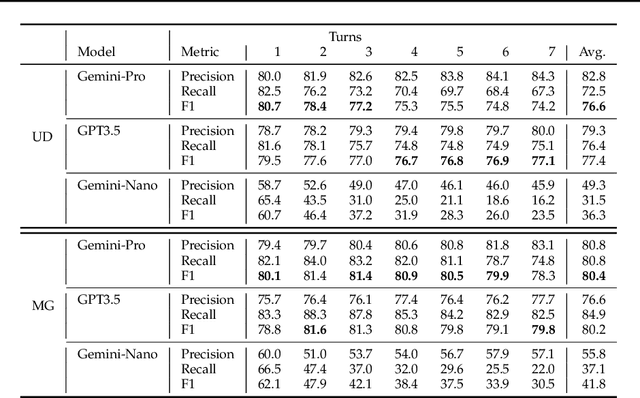
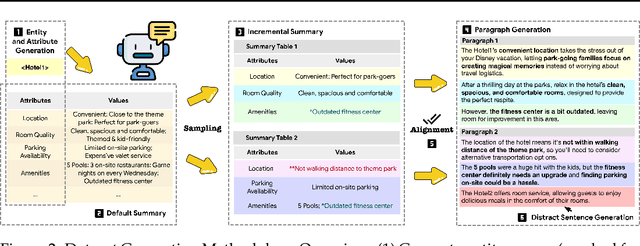
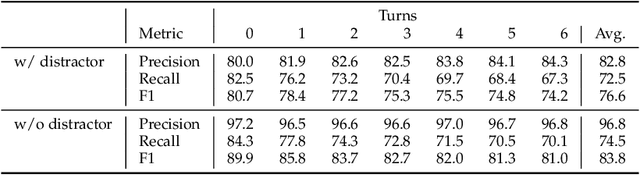
No existing dataset adequately tests how well language models can incrementally update entity summaries - a crucial ability as these models rapidly advance. The Incremental Entity Summarization (IES) task is vital for maintaining accurate, up-to-date knowledge. To address this, we introduce SUMIE, a fully synthetic dataset designed to expose real-world IES challenges. This dataset effectively highlights problems like incorrect entity association and incomplete information presentation. Unlike common synthetic datasets, ours captures the complexity and nuances found in real-world data. We generate informative and diverse attributes, summaries, and unstructured paragraphs in sequence, ensuring high quality. The alignment between generated summaries and paragraphs exceeds 96%, confirming the dataset's quality. Extensive experiments demonstrate the dataset's difficulty - state-of-the-art LLMs struggle to update summaries with an F1 higher than 80.4%. We will open source the benchmark and the evaluation metrics to help the community make progress on IES tasks.
CASPR: Automated Evaluation Metric for Contrastive Summarization
Apr 23, 2024



Summarizing comparative opinions about entities (e.g., hotels, phones) from a set of source reviews, often referred to as contrastive summarization, can considerably aid users in decision making. However, reliably measuring the contrastiveness of the output summaries without relying on human evaluations remains an open problem. Prior work has proposed token-overlap based metrics, Distinctiveness Score, to measure contrast which does not take into account the sensitivity to meaning-preserving lexical variations. In this work, we propose an automated evaluation metric CASPR to better measure contrast between a pair of summaries. Our metric is based on a simple and light-weight method that leverages natural language inference (NLI) task to measure contrast by segmenting reviews into single-claim sentences and carefully aggregating NLI scores between them to come up with a summary-level score. We compare CASPR with Distinctiveness Score and a simple yet powerful baseline based on BERTScore. Our results on a prior dataset CoCoTRIP demonstrate that CASPR can more reliably capture the contrastiveness of the summary pairs compared to the baselines.
STRUM-LLM: Attributed and Structured Contrastive Summarization
Mar 25, 2024Users often struggle with decision-making between two options (A vs B), as it usually requires time-consuming research across multiple web pages. We propose STRUM-LLM that addresses this challenge by generating attributed, structured, and helpful contrastive summaries that highlight key differences between the two options. STRUM-LLM identifies helpful contrast: the specific attributes along which the two options differ significantly and which are most likely to influence the user's decision. Our technique is domain-agnostic, and does not require any human-labeled data or fixed attribute list as supervision. STRUM-LLM attributes all extractions back to the input sources along with textual evidence, and it does not have a limit on the length of input sources that it can process. STRUM-LLM Distilled has 100x more throughput than the models with comparable performance while being 10x smaller. In this paper, we provide extensive evaluations for our method and lay out future directions for our currently deployed system.
An Augmentation Strategy for Visually Rich Documents
Dec 22, 2022Many business workflows require extracting important fields from form-like documents (e.g. bank statements, bills of lading, purchase orders, etc.). Recent techniques for automating this task work well only when trained with large datasets. In this work we propose a novel data augmentation technique to improve performance when training data is scarce, e.g. 10-250 documents. Our technique, which we call FieldSwap, works by swapping out the key phrases of a source field with the key phrases of a target field to generate new synthetic examples of the target field for use in training. We demonstrate that this approach can yield 1-7 F1 point improvements in extraction performance.
A Benchmark for Structured Extractions from Complex Documents
Nov 15, 2022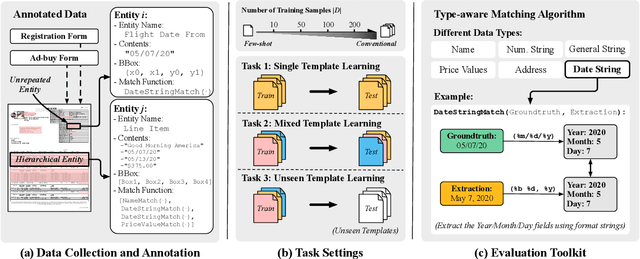
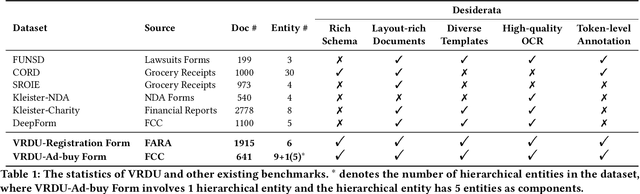


Understanding visually-rich business documents to extract structured data and automate business workflows has been receiving attention both in academia and industry. Although recent multi-modal language models have achieved impressive results, we find that existing benchmarks do not reflect the complexity of real documents seen in industry. In this work, we identify the desiderata for a more comprehensive benchmark and propose one we call Visually Rich Document Understanding (VRDU). VRDU contains two datasets that represent several challenges: rich schema including diverse data types as well as nested entities, complex templates including tables and multi-column layouts, and diversity of different layouts (templates) within a single document type. We design few-shot and conventional experiment settings along with a carefully designed matching algorithm to evaluate extraction results. We report the performance of strong baselines and three observations: (1) generalizing to new document templates is very challenging, (2) few-shot performance has a lot of headroom, and (3) models struggle with nested fields such as line-items in an invoice. We plan to open source the benchmark and the evaluation toolkit. We hope this helps the community make progress on these challenging tasks in extracting structured data from visually rich documents.
Radically Lower Data-Labeling Costs for Visually Rich Document Extraction Models
Oct 28, 2022A key bottleneck in building automatic extraction models for visually rich documents like invoices is the cost of acquiring the several thousand high-quality labeled documents that are needed to train a model with acceptable accuracy. We propose Selective Labeling to simplify the labeling task to provide "yes/no" labels for candidate extractions predicted by a model trained on partially labeled documents. We combine this with a custom active learning strategy to find the predictions that the model is most uncertain about. We show through experiments on document types drawn from 3 different domains that selective labeling can reduce the cost of acquiring labeled data by $10\times$ with a negligible loss in accuracy.
Data-Efficient Information Extraction from Form-Like Documents
Jan 07, 2022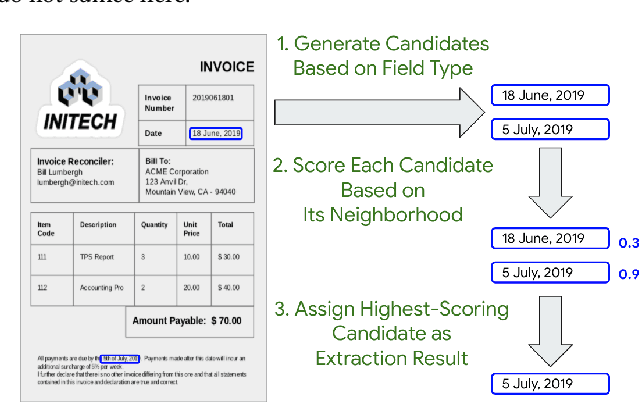
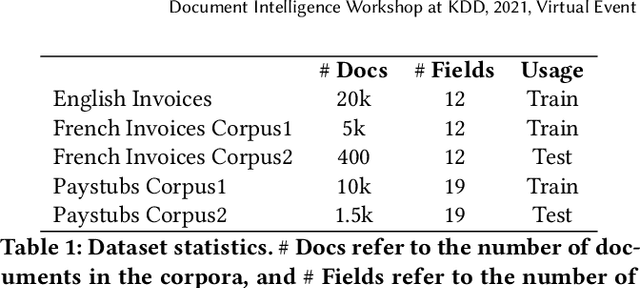
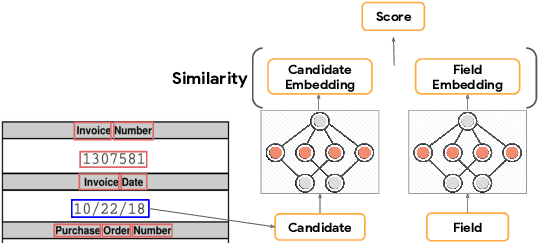
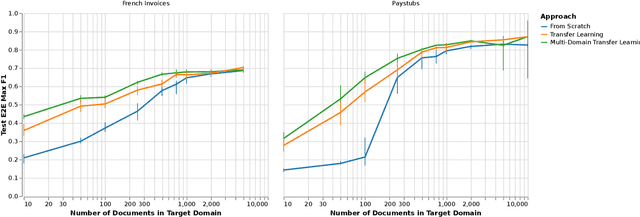
Automating information extraction from form-like documents at scale is a pressing need due to its potential impact on automating business workflows across many industries like financial services, insurance, and healthcare. The key challenge is that form-like documents in these business workflows can be laid out in virtually infinitely many ways; hence, a good solution to this problem should generalize to documents with unseen layouts and languages. A solution to this problem requires a holistic understanding of both the textual segments and the visual cues within a document, which is non-trivial. While the natural language processing and computer vision communities are starting to tackle this problem, there has not been much focus on (1) data-efficiency, and (2) ability to generalize across different document types and languages. In this paper, we show that when we have only a small number of labeled documents for training (~50), a straightforward transfer learning approach from a considerably structurally-different larger labeled corpus yields up to a 27 F1 point improvement over simply training on the small corpus in the target domain. We improve on this with a simple multi-domain transfer learning approach, that is currently in production use, and show that this yields up to a further 8 F1 point improvement. We make the case that data efficiency is critical to enable information extraction systems to scale to handle hundreds of different document-types, and learning good representations is critical to accomplishing this.
Simplified DOM Trees for Transferable Attribute Extraction from the Web
Jan 07, 2021
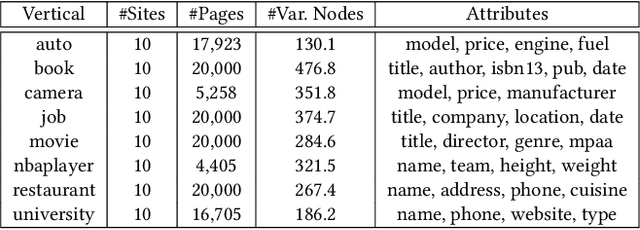
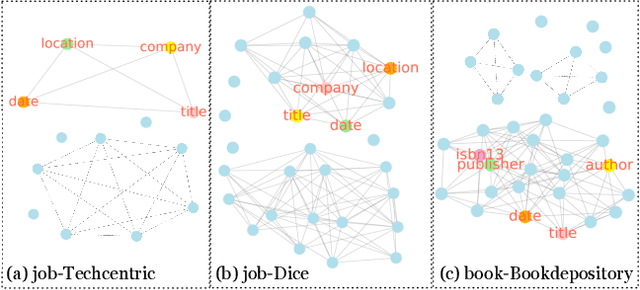
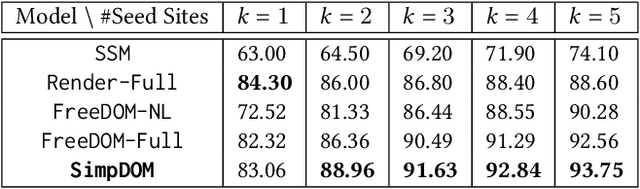
There has been a steady need to precisely extract structured knowledge from the web (i.e. HTML documents). Given a web page, extracting a structured object along with various attributes of interest (e.g. price, publisher, author, and genre for a book) can facilitate a variety of downstream applications such as large-scale knowledge base construction, e-commerce product search, and personalized recommendation. Considering each web page is rendered from an HTML DOM tree, existing approaches formulate the problem as a DOM tree node tagging task. However, they either rely on computationally expensive visual feature engineering or are incapable of modeling the relationship among the tree nodes. In this paper, we propose a novel transferable method, Simplified DOM Trees for Attribute Extraction (SimpDOM), to tackle the problem by efficiently retrieving useful context for each node by leveraging the tree structure. We study two challenging experimental settings: (i) intra-vertical few-shot extraction, and (ii) cross-vertical fewshot extraction with out-of-domain knowledge, to evaluate our approach. Extensive experiments on the SWDE public dataset show that SimpDOM outperforms the state-of-the-art (SOTA) method by 1.44% on the F1 score. We also find that utilizing knowledge from a different vertical (cross-vertical extraction) is surprisingly useful and helps beat the SOTA by a further 1.37%.