 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUMIE: A Synthetic Benchmark for Incremental Entity Summarization
Paper and Code

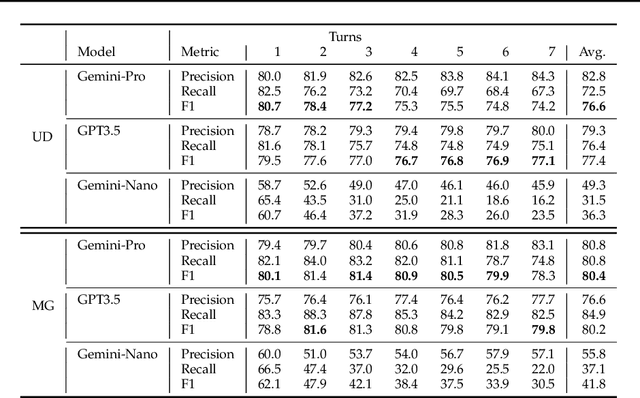
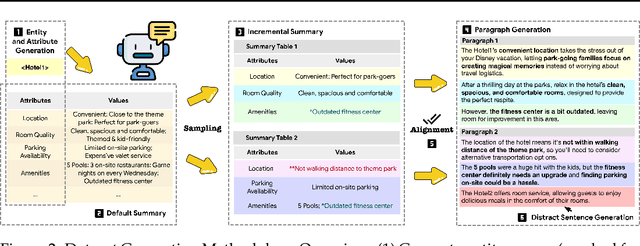
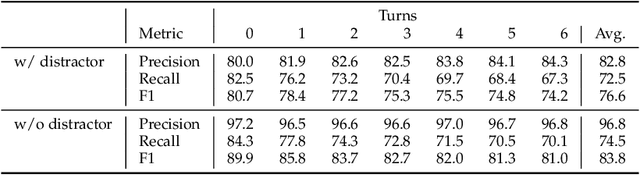
No existing dataset adequately tests how well language models can incrementally update entity summaries - a crucial ability as these models rapidly advance. The Incremental Entity Summarization (IES) task is vital for maintaining accurate, up-to-date knowledge. To address this, we introduce SUMIE, a fully synthetic dataset designed to expose real-world IES challenges. This dataset effectively highlights problems like incorrect entity association and incomplete information presentation. Unlike common synthetic datasets, ours captures the complexity and nuances found in real-world data. We generate informative and diverse attributes, summaries, and unstructured paragraphs in sequence, ensuring high quality. The alignment between generated summaries and paragraphs exceeds 96%, confirming the dataset's quality. Extensive experiments demonstrate the dataset's difficulty - state-of-the-art LLMs struggle to update summaries with an F1 higher than 80.4%. We will open source the benchmark and the evaluation metrics to help the community make progress on IES tasks.