 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiency Follows Global-Local Decoupling
Mar 20, 2026Modern vision models must capture image-level context without sacrificing local detail while remaining computationally affordable. We revisit this tradeoff and advance a simple principle: decouple the roles of global reasoning and local representation. To operationalize this principle, we introduce ConvNeur, a two-branch architecture in which a lightweight neural memory branch aggregates global context on a compact set of tokens, and a locality-preserving branch extracts fine structure. A learned gate lets global cues modulate local features without entangling their objectives. This separation yields subquadratic scaling with image size, retains inductive priors associated with local processing, and reduces overhead relative to fully global attention. On standard classification, detection, and segmentation benchmarks, ConvNeur matches or surpasses comparable alternatives at similar or lower compute and offers favorable accuracy versus latency trade-offs at similar budgets. These results support the view that efficiency follows global-local decoupling.
Prototype-Guided Concept Erasure in Diffusion Models
Mar 09, 2026Concept erasure is extensively utilized in image generation to prevent text-to-image models from generating undesired content. Existing methods can effectively erase narrow concepts that are specific and concrete, such as distinct intellectual properties (e.g. Pikachu) or recognizable characters (e.g. Elon Musk). However, their performance degrades on broad concepts such as ``sexual'' or ``violent'', whose wide scope and multi-faceted nature make them difficult to erase reliably. To overcome this limitation, we exploit the model's intrinsic embedding geometry to identify latent embeddings that encode a given concept. By clustering these embeddings, we derive a set of concept prototypes that summarize the model's internal representations of the concept, and employ them as negative conditioning signals during inference to achieve precise and reliable erasure. Extensive experiments across multiple benchmarks show that our approach achieves substantially more reliable removal of broad concepts while preserving overall image quality, marking a step towards safer and more controllable image generation.
ProToM: Promoting Prosocial Behaviour via Theory of Mind-Informed Feedback
Sep 05, 2025



While humans are inherently social creatures, the challenge of identifying when and how to assist and collaborate with others - particularly when pursuing independent goals - can hinder cooperation. To address this challenge, we aim to develop an AI system that provides useful feedback to promote prosocial behaviour - actions that benefit others, even when not directly aligned with one's own goals. We introduce ProToM, a Theory of Mind-informed facilitator that promotes prosocial actions in multi-agent systems by providing targeted, context-sensitive feedback to individual agents. ProToM first infers agents' goals using Bayesian inverse planning, then selects feedback to communicate by maximising expected utility, conditioned on the inferred goal distribution. We evaluate our approach against baselines in two multi-agent environments: Doors, Keys, and Gems, as well as Overcooked. Our results suggest that state-of-the-art large language and reasoning models fall short of communicating feedback that is both contextually grounded and well-timed - leading to higher communication overhead and task speedup. In contrast, ProToM provides targeted and helpful feedback, achieving a higher success rate, shorter task completion times, and is consistently preferred by human users.
Beyond the LUMIR challenge: The pathway to foundational registration models
May 30, 2025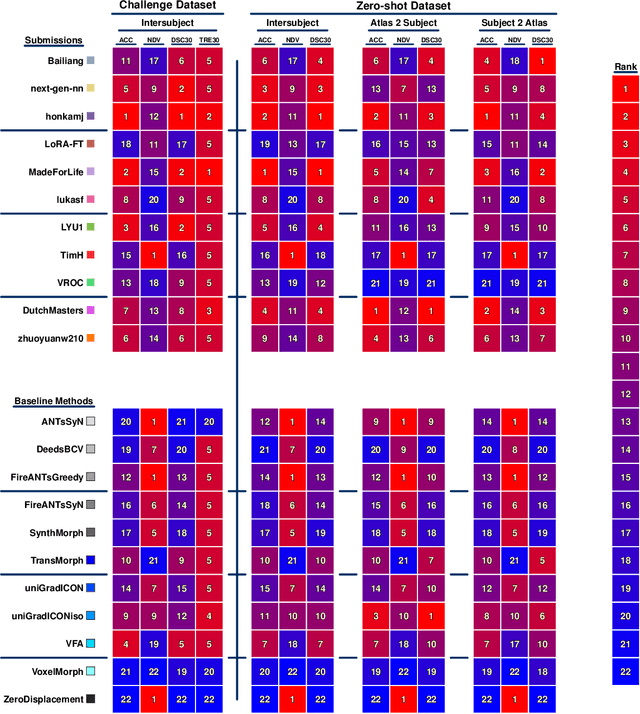
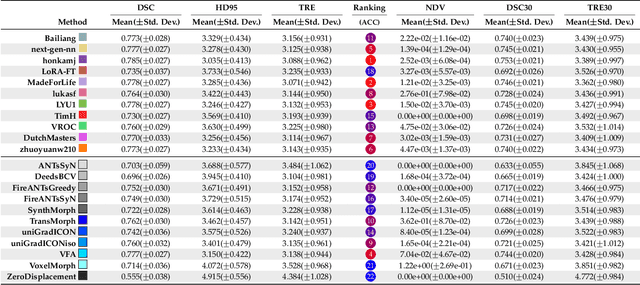

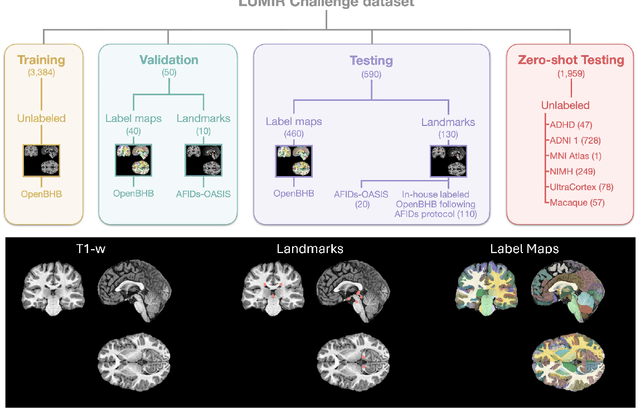
Medical image challenges have played a transformative role in advancing the field, catalyzing algorithmic innovation and establishing new performance standards across diverse clinical applications. Image registration, a foundational task in neuroimaging pipelines, has similarly benefited from the Learn2Reg initiative. Building on this foundation, we introduce the Large-scale Unsupervised Brain MRI Image Registration (LUMIR) challenge, a next-generation benchmark designed to assess and advance unsupervised brain MRI registration. Distinct from prior challenges that leveraged anatomical label maps for supervision, LUMIR removes this dependency by providing over 4,000 preprocessed T1-weighted brain MRIs for training without any label maps, encouraging biologically plausible deformation modeling through self-supervision. In addition to evaluating performance on 590 held-out test subjects, LUMIR introduces a rigorous suite of zero-shot generalization tasks, spanning out-of-domain imaging modalities (e.g., FLAIR, T2-weighted, T2*-weighted), disease populations (e.g., Alzheimer's disease), acquisition protocols (e.g., 9.4T MRI), and species (e.g., macaque brains). A total of 1,158 subjects and over 4,000 image pairs were included for evaluation. Performance was assessed using both segmentation-based metrics (Dice coefficient, 95th percentile Hausdorff distance) and landmark-based registration accuracy (target registration error). Across both in-domain and zero-shot tasks, deep learning-based methods consistently achieved state-of-the-art accuracy while producing anatomically plausible deformation fields. The top-performing deep learning-based models demonstrated diffeomorphic properties and inverse consistency, outperforming several leading optimization-based methods, and showing strong robustness to most domain shifts, the exception being a drop in performance on out-of-domain contrasts.
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Oct 02, 2024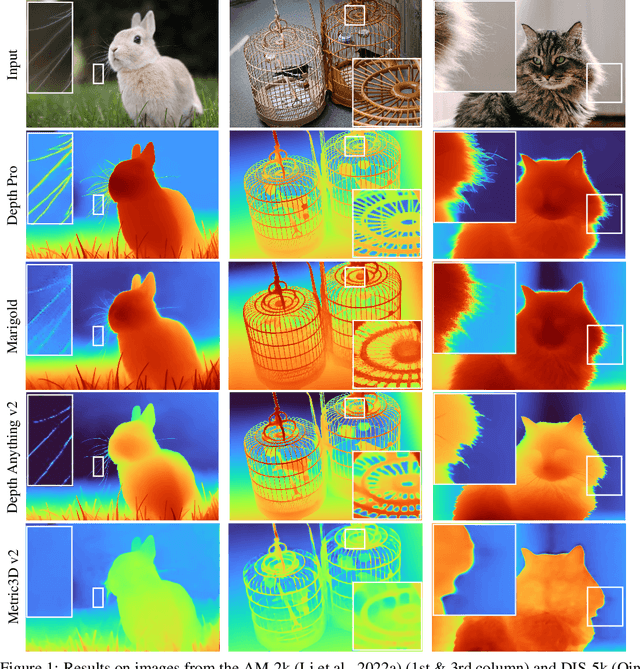
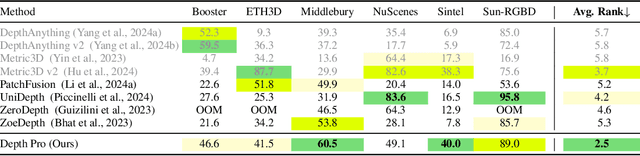
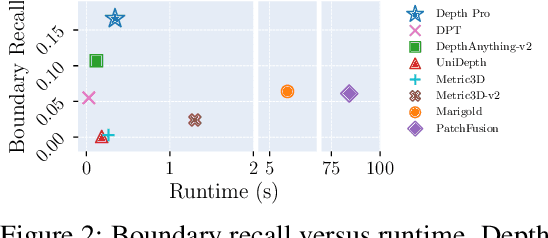
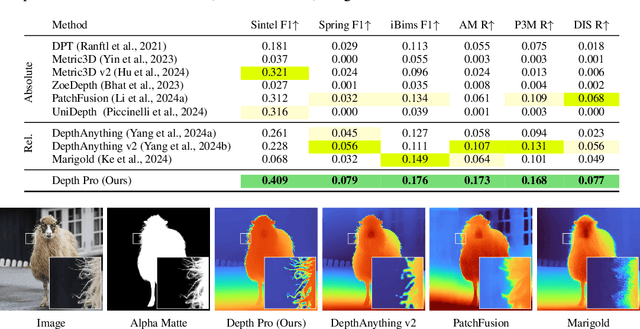
We present a foundation model for zero-shot metric monocular depth estimation. Our model, Depth Pro, synthesizes high-resolution depth maps with unparalleled sharpness and high-frequency details. The predictions are metric, with absolute scale, without relying on the availability of metadata such as camera intrinsics. And the model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU. These characteristics are enabled by a number of technical contributions, including an efficient multi-scale vision transformer for dense prediction, a training protocol that combines real and synthetic datasets to achieve high metric accuracy alongside fine boundary tracing, dedicated evaluation metrics for boundary accuracy in estimated depth maps, and state-of-the-art focal length estimation from a single image. Extensive experiments analyze specific design choices and demonstrate that Depth Pro outperforms prior work along multiple dimensions. We release code and weights at https://github.com/apple/ml-depth-pro
Enhancing Incremental Summarization with Structured Representations
Jul 21, 2024



Large language models (LLMs) often struggle with processing extensive input contexts, which can lead to redundant, inaccurate, or incoherent summaries. Recent methods have used unstructured memory to incrementally process these contexts, but they still suffer from information overload due to the volume of unstructured data handled. In our study, we introduce structured knowledge representations ($GU_{json}$), which significantly improve summarization performance by 40% and 14% across two public datasets. Most notably, we propose the Chain-of-Key strategy ($CoK_{json}$) that dynamically updates or augments these representations with new information, rather than recreating the structured memory for each new source. This method further enhances performance by 7% and 4% on the datasets.
SUMIE: A Synthetic Benchmark for Incremental Entity Summarization
Jun 07, 2024
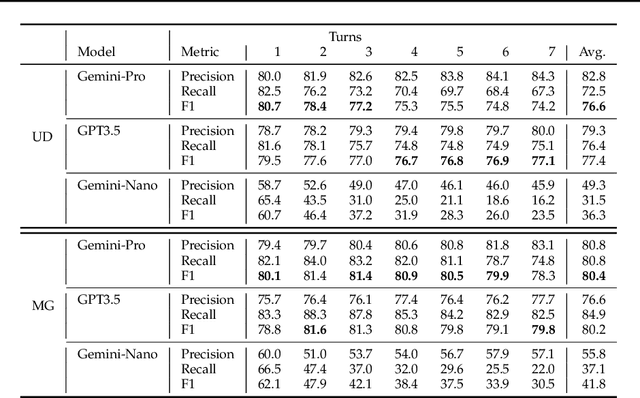
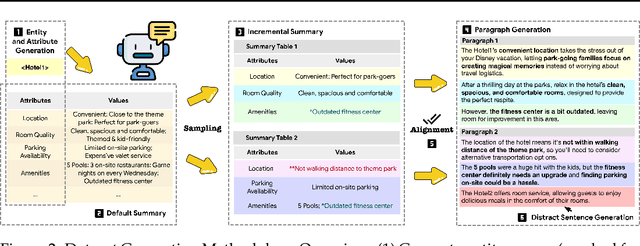
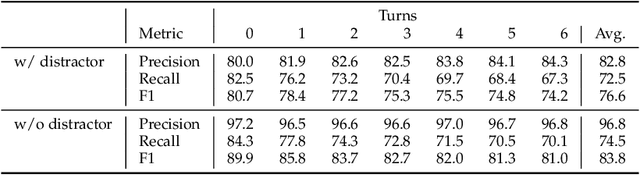
No existing dataset adequately tests how well language models can incrementally update entity summaries - a crucial ability as these models rapidly advance. The Incremental Entity Summarization (IES) task is vital for maintaining accurate, up-to-date knowledge. To address this, we introduce SUMIE, a fully synthetic dataset designed to expose real-world IES challenges. This dataset effectively highlights problems like incorrect entity association and incomplete information presentation. Unlike common synthetic datasets, ours captures the complexity and nuances found in real-world data. We generate informative and diverse attributes, summaries, and unstructured paragraphs in sequence, ensuring high quality. The alignment between generated summaries and paragraphs exceeds 96%, confirming the dataset's quality. Extensive experiments demonstrate the dataset's difficulty - state-of-the-art LLMs struggle to update summaries with an F1 higher than 80.4%. We will open source the benchmark and the evaluation metrics to help the community make progress on IES tasks.
STRUM-LLM: Attributed and Structured Contrastive Summarization
Mar 25, 2024Users often struggle with decision-making between two options (A vs B), as it usually requires time-consuming research across multiple web pages. We propose STRUM-LLM that addresses this challenge by generating attributed, structured, and helpful contrastive summaries that highlight key differences between the two options. STRUM-LLM identifies helpful contrast: the specific attributes along which the two options differ significantly and which are most likely to influence the user's decision. Our technique is domain-agnostic, and does not require any human-labeled data or fixed attribute list as supervision. STRUM-LLM attributes all extractions back to the input sources along with textual evidence, and it does not have a limit on the length of input sources that it can process. STRUM-LLM Distilled has 100x more throughput than the models with comparable performance while being 10x smaller. In this paper, we provide extensive evaluations for our method and lay out future directions for our currently deployed system.
Adaptive Integration of Partial Label Learning and Negative Learning for Enhanced Noisy Label Learning
Dec 15, 2023



There has been significant attention devoted to the effectiveness of various domains, such as semi-supervised learning, contrastive learning, and meta-learning, in enhancing the performance of methods for noisy label learning (NLL) tasks. However, most existing methods still depend on prior assumptions regarding clean samples amidst different sources of noise (\eg, a pre-defined drop rate or a small subset of clean samples). In this paper, we propose a simple yet powerful idea called \textbf{NPN}, which revolutionizes \textbf{N}oisy label learning by integrating \textbf{P}artial label learning (PLL) and \textbf{N}egative learning (NL). Toward this goal, we initially decompose the given label space adaptively into the candidate and complementary labels, thereby establishing the conditions for PLL and NL. We propose two adaptive data-driven paradigms of label disambiguation for PLL: hard disambiguation and soft disambiguation. Furthermore, we generate reliable complementary labels using all non-candidate labels for NL to enhance model robustness through indirect supervision. To maintain label reliability during the later stage of model training, we introduce a consistency regularization term that encourages agreement between the outputs of multiple augmentations. Experiments conducted on both synthetically corrupted and real-world noisy datasets demonstrate the superiority of NPN compared to other state-of-the-art (SOTA) methods. The source code has been made available at {\color{purple}{\url{https://github.com/NUST-Machine-Intelligence-Laboratory/NPN}}}.
FaceStudio: Put Your Face Everywhere in Seconds
Dec 06, 2023This study investigates identity-preserving image synthesis, an intriguing task in image generation that seeks to maintain a subject's identity while adding a personalized, stylistic touch. Traditional methods, such as Textual Inversion and DreamBooth, have made strides in custom image creation, but they come with significant drawbacks. These include the need for extensive resources and time for fine-tuning, as well as the requirement for multiple reference images. To overcome these challenges, our research introduces a novel approach to identity-preserving synthesis, with a particular focus on human images. Our model leverages a direct feed-forward mechanism, circumventing the need for intensive fine-tuning, thereby facilitating quick and efficient image generation. Central to our innovation is a hybrid guidance framework, which combines stylized images, facial images, and textual prompts to guide the image generation process. This unique combination enables our model to produce a variety of applications, such as artistic portraits and identity-blended images. Our experimental results, including both qualitative and quantitative evaluations, demonstrate the superiority of our method over existing baseline models and previous works, particularly in its remarkable efficiency and ability to preserve the subject's identity with high fidelity.