 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRUM-LLM: Attributed and Structured Contrastive Summarization
Mar 25, 2024Users often struggle with decision-making between two options (A vs B), as it usually requires time-consuming research across multiple web pages. We propose STRUM-LLM that addresses this challenge by generating attributed, structured, and helpful contrastive summaries that highlight key differences between the two options. STRUM-LLM identifies helpful contrast: the specific attributes along which the two options differ significantly and which are most likely to influence the user's decision. Our technique is domain-agnostic, and does not require any human-labeled data or fixed attribute list as supervision. STRUM-LLM attributes all extractions back to the input sources along with textual evidence, and it does not have a limit on the length of input sources that it can process. STRUM-LLM Distilled has 100x more throughput than the models with comparable performance while being 10x smaller. In this paper, we provide extensive evaluations for our method and lay out future directions for our currently deployed system.
An Augmentation Strategy for Visually Rich Documents
Dec 22, 2022Many business workflows require extracting important fields from form-like documents (e.g. bank statements, bills of lading, purchase orders, etc.). Recent techniques for automating this task work well only when trained with large datasets. In this work we propose a novel data augmentation technique to improve performance when training data is scarce, e.g. 10-250 documents. Our technique, which we call FieldSwap, works by swapping out the key phrases of a source field with the key phrases of a target field to generate new synthetic examples of the target field for use in training. We demonstrate that this approach can yield 1-7 F1 point improvements in extraction performance.
Radically Lower Data-Labeling Costs for Visually Rich Document Extraction Models
Oct 28, 2022A key bottleneck in building automatic extraction models for visually rich documents like invoices is the cost of acquiring the several thousand high-quality labeled documents that are needed to train a model with acceptable accuracy. We propose Selective Labeling to simplify the labeling task to provide "yes/no" labels for candidate extractions predicted by a model trained on partially labeled documents. We combine this with a custom active learning strategy to find the predictions that the model is most uncertain about. We show through experiments on document types drawn from 3 different domains that selective labeling can reduce the cost of acquiring labeled data by $10\times$ with a negligible loss in accuracy.
Data-Efficient Information Extraction from Form-Like Documents
Jan 07, 2022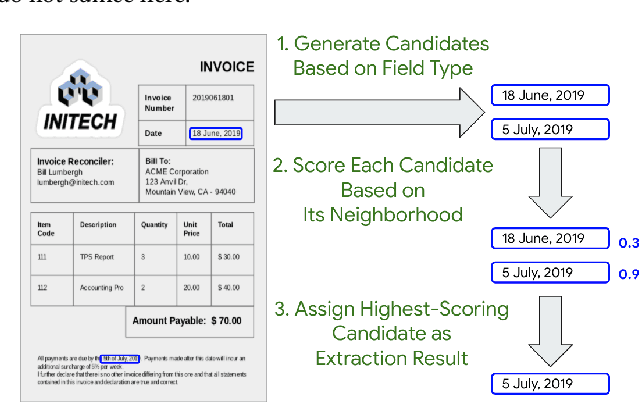
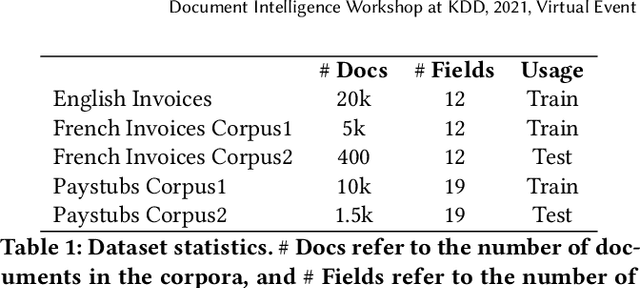
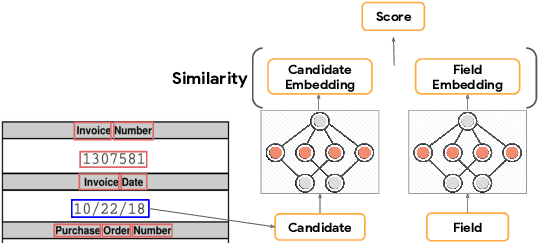
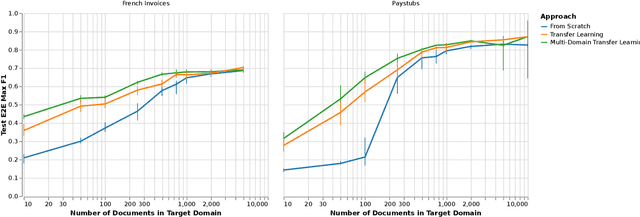
Automating information extraction from form-like documents at scale is a pressing need due to its potential impact on automating business workflows across many industries like financial services, insurance, and healthcare. The key challenge is that form-like documents in these business workflows can be laid out in virtually infinitely many ways; hence, a good solution to this problem should generalize to documents with unseen layouts and languages. A solution to this problem requires a holistic understanding of both the textual segments and the visual cues within a document, which is non-trivial. While the natural language processing and computer vision communities are starting to tackle this problem, there has not been much focus on (1) data-efficiency, and (2) ability to generalize across different document types and languages. In this paper, we show that when we have only a small number of labeled documents for training (~50), a straightforward transfer learning approach from a considerably structurally-different larger labeled corpus yields up to a 27 F1 point improvement over simply training on the small corpus in the target domain. We improve on this with a simple multi-domain transfer learning approach, that is currently in production use, and show that this yields up to a further 8 F1 point improvement. We make the case that data efficiency is critical to enable information extraction systems to scale to handle hundreds of different document-types, and learning good representations is critical to accomplishing this.