 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPGL-Swarm: Integrated Multimodal Risk Stratification and Hereditary Syndrome Detection in Pheochromocytoma and Paraganglioma
Mar 23, 2026Pheochromocytomas and paragangliomas (PPGLs) are rare neuroendocrine tumors, of which 15-25% develop metastatic disease with 5-year survival rates reported as low as 34%. PPGL may indicate hereditary syndromes requiring stricter, syndrome-specific treatment and surveillance, but clinicians often fail to recognize these associations in routine care. Clinical practice uses GAPP score for PPGL grading, but several limitations remain for PPGL diagnosis: (1) GAPP scoring demands a high workload for clinician because it requires the manual evaluation of six independent components; (2) key components such as cellularity and Ki-67 are often evaluated with subjective criteria; (3) several clinically relevant metastatic risk factors are not captured by GAPP, such as SDHB mutations, which have been associated with reported metastatic rates of 35-75%. Agent-driven diagnostic systems appear promising, but most lack traceable reasoning for decision-making and do not incorporate domain-specific knowledge such as PPGL genotype information. To address these limitations, we present PPGL-Swarm, an agentic PPGL diagnostic system that generates a comprehensive report, including automated GAPP scoring (with quantified cellularity and Ki-67), genotype risk alerts, and multimodal report with integrated evidence. The system provides an auditable reasoning trail by decomposing diagnosis into micro-tasks, each assigned to a specialized agent. The gene and table agents use knowledge enhancement to better interpret genotype and laboratory findings, and during training we use reinforcement learning to refine tool selection and task assignment.
MM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
Mar 10, 2026Self-evolving has emerged as a key paradigm for improving foundational models such as Large Language Models (LLMs) and Vision Language Models (VLMs) with minimal human intervention. While recent approaches have demonstrated that LLM agents can self-evolve from scratch with little to no data, VLMs introduce an additional visual modality that typically requires at least some seed data, such as images, to bootstrap the self-evolution process. In this work, we present Multi-model Multimodal Zero (MM-Zero), the first RL-based framework to achieve zero-data self-evolution for VLM reasoning. Moving beyond prior dual-role (Proposer and Solver) setups, MM-Zero introduces a multi-role self-evolving training framework comprising three specialized roles: a Proposer that generates abstract visual concepts and formulates questions; a Coder that translates these concepts into executable code (e.g., Python, SVG) to render visual images; and a Solver that performs multimodal reasoning over the generated visual content. All three roles are initialized from the same base model and trained using Group Relative Policy Optimization (GRPO), with carefully designed reward mechanisms that integrate execution feedback, visual verification, and difficulty balancing. Our experiments show that MM-Zero improves VLM reasoning performance across a wide range of multimodal benchmarks. MM-Zero establishes a scalable path toward self-evolving multi-model systems for multimodal models, extending the frontier of self-improvement beyond the conventional two-model paradigm.
Prefill-Based Jailbreak: A Novel Approach of Bypassing LLM Safety Boundary
Apr 28, 2025Large Language Models (LLMs) are designed to generate helpful and safe content. However, adversarial attacks, commonly referred to as jailbreak, can bypass their safety protocols, prompting LLMs to generate harmful content or reveal sensitive data. Consequently, investigating jailbreak methodologies is crucial for exposing systemic vulnerabilities within LLMs, ultimately guiding the continuous implementation of security enhancements by developers. In this paper, we introduce a novel jailbreak attack method that leverages the prefilling feature of LLMs, a feature designed to enhance model output constraints. Unlike traditional jailbreak methods, the proposed attack circumvents LLMs' safety mechanisms by directly manipulating the probability distribution of subsequent tokens, thereby exerting control over the model's output. We propose two attack variants: Static Prefilling (SP), which employs a universal prefill text, and Optimized Prefilling (OP), which iteratively optimizes the prefill text to maximize the attack success rate. Experiments on six state-of-the-art LLMs using the AdvBench benchmark validate the effectiveness of our method and demonstrate its capability to substantially enhance attack success rates when combined with existing jailbreak approaches. The OP method achieved attack success rates of up to 99.82% on certain models, significantly outperforming baseline methods. This work introduces a new jailbreak attack method in LLMs, emphasizing the need for robust content validation mechanisms to mitigate the adversarial exploitation of prefilling features. All code and data used in this paper are publicly available.
Enhancing Incremental Summarization with Structured Representations
Jul 21, 2024



Large language models (LLMs) often struggle with processing extensive input contexts, which can lead to redundant, inaccurate, or incoherent summaries. Recent methods have used unstructured memory to incrementally process these contexts, but they still suffer from information overload due to the volume of unstructured data handled. In our study, we introduce structured knowledge representations ($GU_{json}$), which significantly improve summarization performance by 40% and 14% across two public datasets. Most notably, we propose the Chain-of-Key strategy ($CoK_{json}$) that dynamically updates or augments these representations with new information, rather than recreating the structured memory for each new source. This method further enhances performance by 7% and 4% on the datasets.
From ChatGPT, DALL-E 3 to Sora: How has Generative AI Changed Digital Humanities Research and Services?
Apr 29, 2024Generative large-scale language models create the fifth paradigm of scientific research, organically combine data science and computational intelligence, transform the research paradigm of natural language processing and multimodal information processing, promote the new trend of AI-enabled social science research, and provide new ideas for digital humanities research and application. This article profoundly explores the application of large-scale language models in digital humanities research, revealing their significant potential in ancient book protection, intelligent processing, and academic innovation. The article first outlines the importance of ancient book resources and the necessity of digital preservation, followed by a detailed introduction to developing large-scale language models, such as ChatGPT, and their applications in document management, content understanding, and cross-cultural research. Through specific cases, the article demonstrates how AI can assist in the organization, classification, and content generation of ancient books. Then, it explores the prospects of AI applications in artistic innovation and cultural heritage preservation. Finally, the article explores the challenges and opportunities in the interaction of technology, information, and society in the digital humanities triggered by AI technologies.
STRUM-LLM: Attributed and Structured Contrastive Summarization
Mar 25, 2024Users often struggle with decision-making between two options (A vs B), as it usually requires time-consuming research across multiple web pages. We propose STRUM-LLM that addresses this challenge by generating attributed, structured, and helpful contrastive summaries that highlight key differences between the two options. STRUM-LLM identifies helpful contrast: the specific attributes along which the two options differ significantly and which are most likely to influence the user's decision. Our technique is domain-agnostic, and does not require any human-labeled data or fixed attribute list as supervision. STRUM-LLM attributes all extractions back to the input sources along with textual evidence, and it does not have a limit on the length of input sources that it can process. STRUM-LLM Distilled has 100x more throughput than the models with comparable performance while being 10x smaller. In this paper, we provide extensive evaluations for our method and lay out future directions for our currently deployed system.
An Augmentation Strategy for Visually Rich Documents
Dec 22, 2022Many business workflows require extracting important fields from form-like documents (e.g. bank statements, bills of lading, purchase orders, etc.). Recent techniques for automating this task work well only when trained with large datasets. In this work we propose a novel data augmentation technique to improve performance when training data is scarce, e.g. 10-250 documents. Our technique, which we call FieldSwap, works by swapping out the key phrases of a source field with the key phrases of a target field to generate new synthetic examples of the target field for use in training. We demonstrate that this approach can yield 1-7 F1 point improvements in extraction performance.
Radically Lower Data-Labeling Costs for Visually Rich Document Extraction Models
Oct 28, 2022A key bottleneck in building automatic extraction models for visually rich documents like invoices is the cost of acquiring the several thousand high-quality labeled documents that are needed to train a model with acceptable accuracy. We propose Selective Labeling to simplify the labeling task to provide "yes/no" labels for candidate extractions predicted by a model trained on partially labeled documents. We combine this with a custom active learning strategy to find the predictions that the model is most uncertain about. We show through experiments on document types drawn from 3 different domains that selective labeling can reduce the cost of acquiring labeled data by $10\times$ with a negligible loss in accuracy.
Towards lifelong learning of Recurrent Neural Networks for control design
Aug 08, 2022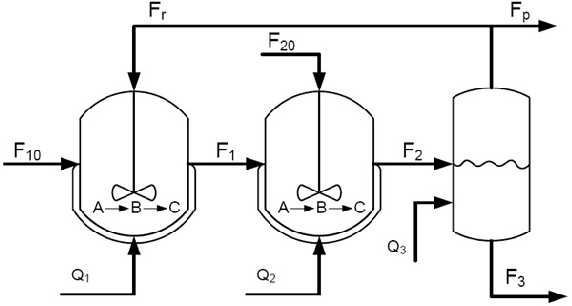
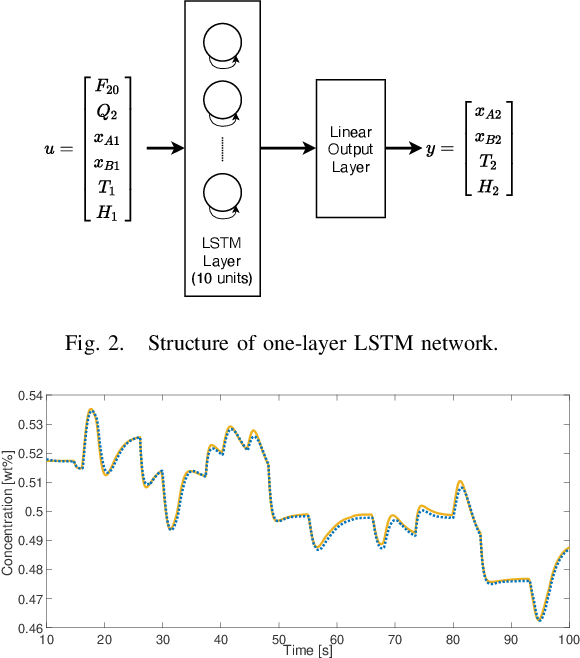

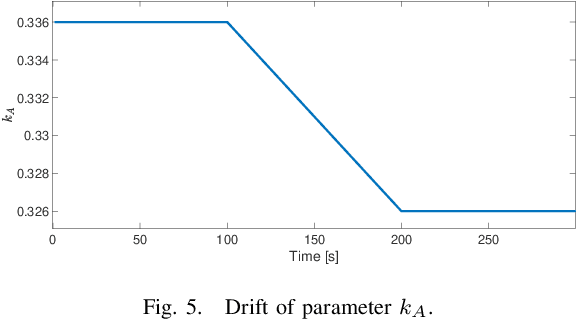
This paper proposes a method for lifelong learning of Recurrent Neural Networks, such as NNARX, ESN, LSTM, and GRU, to be used as plant models in control system synthesis. The problem is significant because in many practical applications it is required to adapt the model when new information is available and/or the system undergoes changes, without the need to store an increasing amount of data as time proceeds. Indeed, in this context, many problems arise, such as the well known Catastrophic Forgetting and Capacity Saturation ones. We propose an adaptation algorithm inspired by Moving Horizon Estimators, deriving conditions for its convergence. The described method is applied to a simulated chemical plant, already adopted as a challenging benchmark in the existing literature. The main results achieved are discussed.
* Copyright 2022 EUCA. This article appears in the Proceedings of the 2022 European Control Conference (ECC'22), July 12-15, 2022, London, pp. 2018-2023
An Offset-Free Nonlinear MPC scheme for systems learned by Neural NARX models
Mar 30, 2022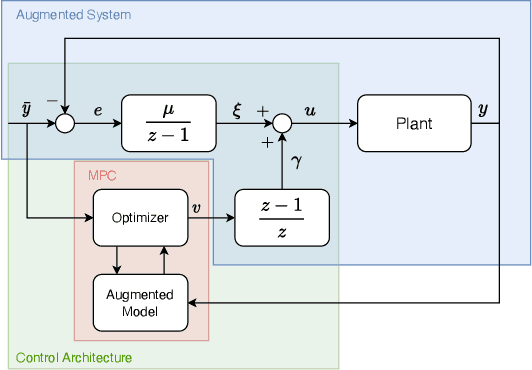
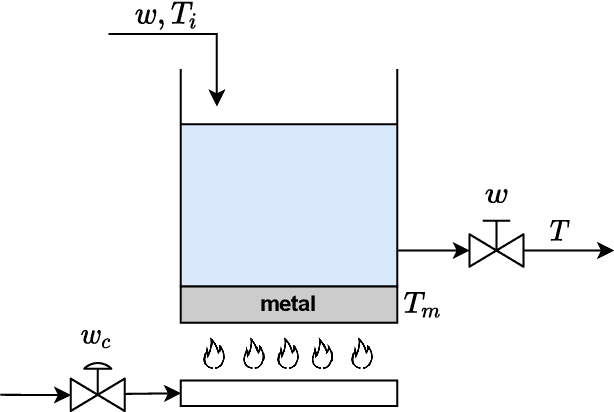

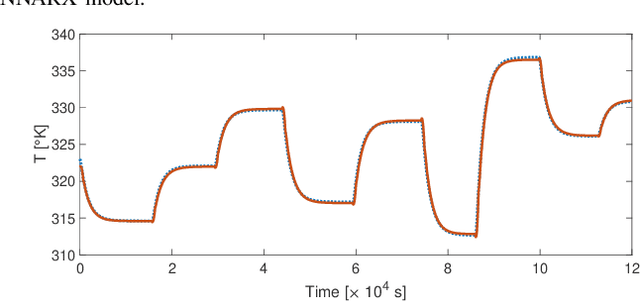
This paper deals with the design of nonlinear MPC controllers that provide offset-free setpoint tracking for models described by Neural Nonlinear AutoRegressive eXogenous (NNARX) networks. The NNARX model is identified from input-output data collected from the plant, and can be given a state-space representation with known measurable states made by past input and output variables, so that a state observer is not required. In the training phase, the Incremental Input-to-State Stability ({\delta}ISS) property can be forced when consistent with the behavior of the plant. The {\delta}ISS property is then leveraged to augment the model with an explicit integral action on the output tracking error, which allows to achieve offset-free tracking capabilities to the designed control scheme. The proposed control architecture is numerically tested on a water heating system and the achieved results are compared to those scored by another popular offset-free MPC method, showing that the proposed scheme attains remarkable performances even in presence of disturbances acting on the plant.